Adversarial Attack Type I: Cheat Classifiers by Significant Changes
出于实现目的,翻译原文(侵删)

Published in: IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI 2019)
源码地址:http://www.pami.sjtu.edu.cn/Show/56/115
目录:
II. TYPE I ATTACK AND ITS RELATIONSHIP TO TYPE II
A. Toy Example on Feature Interpretation
III. SUPERVISED VAE MODEL FOR TYPE I ATTACK
A. Supervised Variational Autoencoder
C. Generating Adversarial Examples for Type I Attack
A. Type I Attack on Digits Classifier
B. Type I Attack on Face Recognizer
C. Type I Attack Defenses by Detecting
D. Type I Attack Defenses by Strengthening
E. Type I Attack on Latent Space
尽管深度神经网络取得了巨大的成功,但对抗性攻击可以通过小扰动欺骗一些训练有素的分类器。在本文中,我们提出了另一种类型的对抗性攻击,可以通过显著的变化欺骗分类器。例如,我们可以显著地改变一张脸,但是训练有素的神经网络仍然将对手和原来的例子识别为同一个人。统计上,现有的对抗攻击增加了II型错误,并且所提出的攻击针对I型错误,因此分别命名为II型和I型对抗攻击。这两种类型的攻击同样重要,但本质上不同,这是直观的解释和数值评估。为了实现该攻击,设计了一个有监督的变分自编码器,然后利用梯度信息更新潜在变量对分类器进行攻击。此外,利用预训练生成模型,研究了隐空间的I型攻击。实验结果表明,该方法在大规模图像数据集上生成I型对抗样本是实用有效的。大多数生成的样本都可以通过为防御II型攻击而设计的检测器,并且增强策略仅对特定类型的攻击有效,这都意味着I型和II型攻击的根本原因不同。
近年来,深度神经网络(DNN)在图像分类[1,2],分割[3]和生成任务[4,5]等方面显示了强大的能力。但是许多DNN模型已经被发现容易受到对抗样本的攻击[6,7,8],这些例子阻止了DNNs在物理世界中的部署,例如自动驾驶和外科机器人。对抗性攻击揭示了训练有素的DNNs和oracle之间的不一致性,即使它们在已知样本上有一致的性能。这种不一致性表明DNNs对于对抗性干扰[9]过于敏感,因此当污染的样本与正确分类的样本只有微小的差别时,DNNs可能会错误地改变它们的标签。在形式上,可以描述为以下问题:
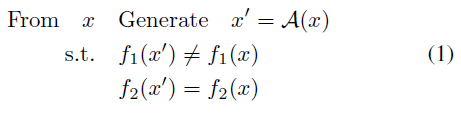
其中f1是要被攻击的分类器,而f2是攻击者,它可能是一个oracle分类器,例如一组人类标注者。在一些文献[10]中,最后一个要求,即f2(x)=f2(x'),写为d(g2(x),g2(x'))≤ε,这要求x和x'的距离不超过阈值,并且自然导致f2的预测结果相同。
对抗攻击的研究对DNNs的鲁棒性研究具有重要意义,对DNNs的许多应用都具有重要意义。例如,生成样本通常对DNNs来说是困难的,对于增强神经网络是非常有价值的。此外,原样本x与对抗样本x'之间的关系以及生成过程是非常重要的,可能会对DNNs产生深刻的理解。因此,自其提出以来,对抗性攻击、对抗性防御、对抗性理解一直备受关注。例如,快速梯度符号法(FGSM,[6])可以通过近似线性化分类器在一步内产生对抗样本。文献[11]设计了一种强大的攻击算法,通过同时最小化输入失真和DNNs输出与目标输出之间的距离,获得了较高的成功率。
在不丧失一般性的情况下,我们可以假设原始样本x具有正标签,即f1(x)=f2(x)=1 in(1),并将其他类别的样本视为负。然后通过(1),我们生成一个样本x',使得f1(x')=-1,f2(x')=1。从这个意义上说,(1)产生假阴性并导致II型错误。研究产生假阴性和防止II型错误是非常重要的。近年来取得了很大的进展,如[6][7][10][12][13][14][15]。然而,II型错误只是硬币的一面。只部分强调(1)并不能得到理想的结果:常数函数f1(x)=1,∀x免疫对抗性攻击(1),假阴性率为0,但这个函数明显不好。从统计学上讲,与假阳性相对应的I型错误应与II型误差同时考虑。它们的组合为一个分类器提供了一个全面的度量:在上述极端情况下,一个常数函数没有II型错误,但是I型错误的比率很高,因此它不是一个好的分类器。
对抗性攻击(1)是通过产生假阴性来增加II型错误的攻击,近年来受到越来越多的关注。但是关于I型错误的讨论没有。对于I型错误,我们关注假阳性,即从一个样本x,f1(x)=f2(x)=1,我们生成一个对抗样本x',满足f1(x')=1,而f2(x')=-1。从数学上讲,
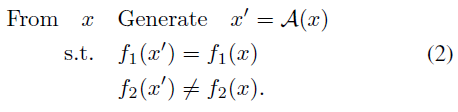
对抗攻击依赖于被攻击分类器和攻击者之间的不一致性。对于(1),从x到x'的微小变化(在f2视图中没有差异)导致f1的符号反转。而新的攻击(2)显示了另一个不一致性:f1对f2发生的显著变化没有响应。图1给出了一个直观的例子,攻击了一个在MNIST上训练的分类器,其测试精度达到98.64%。从正确识别的“3”开始,i)通过(1),我们稍微干扰它,使对抗数字仍然是“3”,但被识别为“8”;ii)通过(2),我们真的将其更改为“8”,但f1仍与以前一样:分类器将对抗数字视为“3”。

与II型攻击不同,II型攻击与原始样本的变体非常小,I型攻击需要进行重大更改才能转换真正的标签。一般来说,这是更困难的,因为增加噪音对于I型攻击不起作用。本文设计了一个有监督变分自编码器(SVAE)模型,它是原始的变分自编码器(VAE)[5]的有监督扩展。基于高斯分布的先验知识,在隐空间中嵌入信息,可以捕捉到特征。然后在隐空间上,采用梯度下降法对隐变量进行更新,并通过解码器进行前向传播,将修正后的隐变量恢复到图像中。利用隐空间中的高斯约束,并受对抗自编码器的启发[16],添加一个鉴别器估计流形在隐空间中的分布,然后成功地进行攻击。请注意,I型攻击不限于VAE结构。任何能将输入转移到可控隐空间的框架,也就是说样本被期望遵循已知分布编码,都有可能进行I型攻击。本文提供了AC-GAN[17]和StyleGAN[18]对隐空间的I型攻击(隐空间攻击在[15]中设计为II型攻击)的实验。其他自编码器方法和生成模型,包括[4][19][20][21][22],也很有希望产生I型对抗样本。
本文的其余部分安排如下。第二节提出了I型对抗攻击,并讨论了其与II型攻击的联系。I型对抗攻击的技术在第三节中给出。第四节评估了所提出的对数字和人脸识别任务的攻击,还报告了为II型攻击设计的防御性能,显示了I型和II型攻击之间的本质区别。在第五节中,对本文进行了总结。
II. TYPE I ATTACK AND ITS RELATIONSHIP TO TYPE II
深度神经网络在训练集上表现出强大的拟合能力。尽管f1和f2在已知数据上的性能非常相似,但它们仍然不同,并且这种不一致性可能会被对抗性攻击暴露出来。对于训练样本x,f1和f2具有相同的符号,例如f1(x)=f2(x)=1。当x变为x'时,在以下两种情况下发生不一致:i)攻击者f2保持不变,但被攻击的分类器f1过于敏感,即f2(x')=1但f1(x')=-1;ii)f2观察到差异,但f1过于稳定,即f2(x')=-1但f1(x')=1。
这两种对抗攻击分别用(1)和(2)来描述。II型攻击(1)在攻击方法、防御策略和理论分析方面进行了大量的研究。但I型攻击并没有被认真考虑。如[8]所述,到目前为止,只有[23]考虑了I型错误,然而,它仍然基于小的变化,并且很容易被发现。在本文中,我们将通过设计一个有监督的变分自动编码器和梯度更新来设计一个实用的I型攻击。
A. Toy Example on Feature Interpretation
在介绍详细的技术之前,我们在这里给出一个虚构示例来演示图2中I型和II型攻击的不同潜在原因,其中黄色圆圈和绿色十字代表正和负的训练样本。数据在三维空间中,oracle分类器f2(如人眼等)使用x(1)和x(2)来区分样本。但是在这些样本上训练,f1通过考虑x(1)和x(3)得到100%的准确度。因此,x(3)是一个不必要的特性,oracle不考虑它,而是在分类器中使用它。由于x(3)是一个不必要的特征,我们可以沿着x(3)移动一个真正的正数,而oracle无法观察到该变量,而是使f1发生变化(类型II攻击,蓝色箭头)。文献[10]从理论上讨论了不必要特征与II型对抗攻击之间的联系。
要生成(2)中描述的另一类对抗样本,我们需要攻击缺失特征,而不是不必要的功能。在图2中,x(2)在oracle中被考虑在内,但被f1省略。由于x(2)缺失,我们可以沿x(2)改变样本,直到它越过f2的判定边界,但对f1没有影响。这个变化由绿色箭头显示,通过这个箭头,我们成功地在oracle视图中生成了一个与x不同的样本,但是f1保持不变。这个虚拟的例子展示了I型和II型攻击的不同本质。为了寻找一个理想的能够模仿oracle的分类器,需要研究II型攻击中的不必要的特征和I型攻击中的缺失特征。
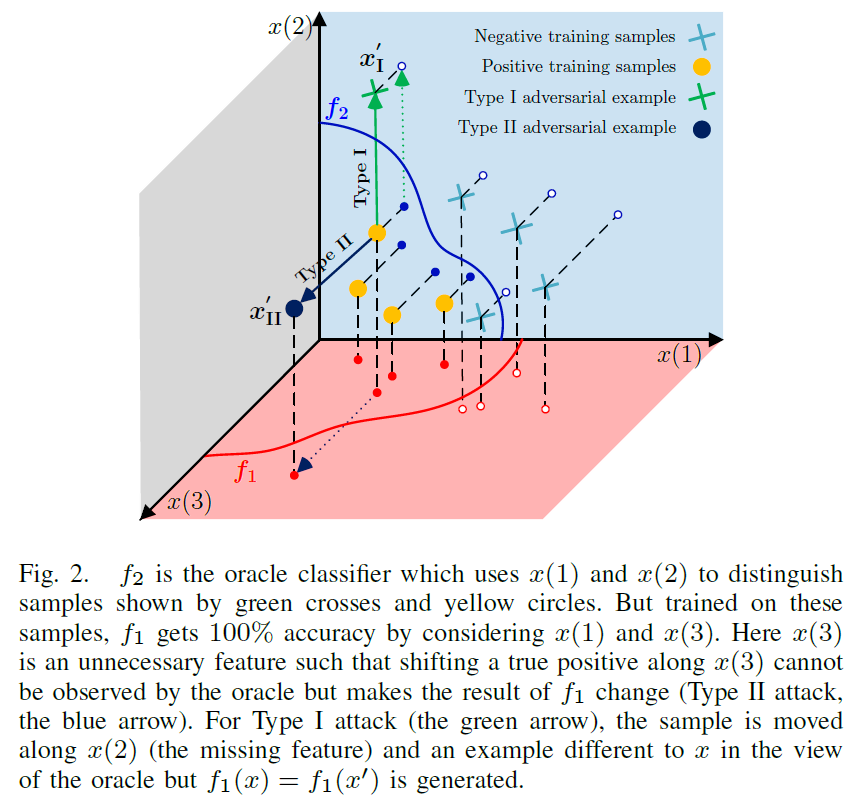
实际应用要比图2中的虚拟示例复杂得多,主要是因为这些特性并不是严格正交的。但上述特征空间解释表明,I型和II型对抗性攻击的根本原因是不同的,因此,针对一种类型设计的防御方法可能不适用于另一种类型。在数值实验中,我们将证明一些针对II型攻击设计的防御方法对I型攻击的鲁棒性没有帮助。更糟糕的是,如果某些方法旨在减少不必要的特征来防御II型攻击,则可能使分类器更容易受到I型攻击。
综上所述,现有的II型对抗攻击可以通过小扰动来欺骗分类器,使得分类器有不适当的改变。我们提出的I型对抗攻击通过显著的变化欺骗分类器,而分类器不适当地忽略了这些变化。II型的对抗样本和生成过程被认为是十分有趣的,对分析神经网络很重要。对于大多数这些主题,I型攻击是必不可少的。以基于对抗性攻击的分类器评估为例,不仅要考虑II型错误,还要考虑I型错误。另一种情况是通过重训练来增强分类器,对于这种情况,I型攻击生成的对抗样本(如图2中的x1')无法通过II型攻击找到。对于神经网络的解释,研究II型对抗攻击会导致不必要的特征,而缺失的特征只能通过I型攻击来捕获。一般来说,从I型和II型攻击中学习对抗样本是有帮助的。
为了研究对抗性攻击,文献[24]设计了一个有趣的例子来对来自两个不同半径同心球体的数据进行分类。对于这个简单的任务,下面的带有二次激活函数的单隐层网络实现了非常高的精度:
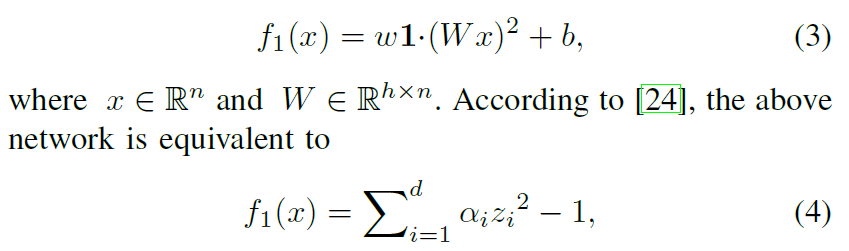
其中z是x的旋转,d是W的秩。基于这一等价性,文献[24]指出,当h>n时,很容易找到对抗样本,其结论仅限于II类对抗样本。事实上,当H<N时,仍然存在I型对抗样本。直观的解释是,当h<n时,分类器漏掉输入的n-h维,使得这些维上的值可以任意修改,同时保持f1的分类结果不变。
数值上,我们考虑了n=100,h=90且样本均匀分布在半径分别为0.8和1.0的同心球体上的实验。然后,训练表(3)中的网络共100万次迭代,批大小为64,这意味着总共使用6400万个i.i.d.训练样本。经过训练,对10万个随机样本进行了测试,错误率小于10-4,表明我们已经获得了一个非常好的分类器。对于所获得的分类器,很难生成如[24]所述的II型对抗样本。但是,从任何一个||x||2=0.8的样本中,我们可以首先把它转换成z-空间,设置
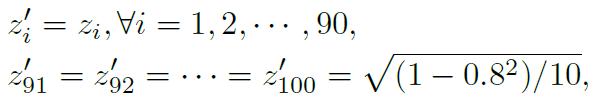
并从z'中得到x'。由于维度z91, ... , z100被f1忽略,生成的x'的函数值与x的函数值相同,但x'已移动到外球面。在实际中,当网络结构不清晰或(反)投影困难时,我们可以通过将径向矢量投影到曲面▽f1(x)=0来将x移到外球面。从x到x'的轨迹如图3所示,这也表明了我们将在下面几节讨论的I型对抗攻击的基本策略。
III. SUPERVISED VAE MODEL FOR TYPE I ATTACK
在图4中,我们展示了用于训练隐空间和生成I型对抗样本的设计框架。对于编码器,存在多条可能路径,本文提出了一种有监督变分自编码器(SVAE),即VAE的有监督扩展。对于攻击,f1的梯度不仅像传统方法那样反向传播到f1的输入x',而且通过解码器进一步反向传播到隐变量z。同时,利用攻击者的梯度修正z,通过解码器得到一个新的带有不同标签的图像x'。在这个过程中,f1和f2之间需要平衡,以保持f1的输出不变,以实现I型攻击。
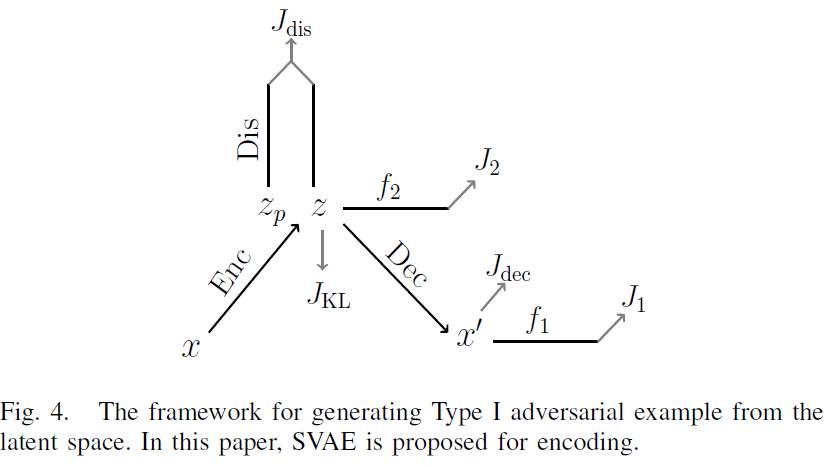
A. Supervised Variational Autoencoder
让我们先解释一下SVAE的细节。基于隐变量z在图像空间中生成x的VAE生成模型,该模型被建模为p(x) = ∫p(x|z)p(z)dz,监督VAE可以被描述为p(x,y) = ∫p(x,y|z)p(z)dz,其中y是来自攻击者的标签信息。
与VAE相似,为了优化有监督变分自编码器模型,我们得到了p(x,y)的下界。假设q(z)是隐空间中的任意分布,其到p(z|x,y)的距离可以用Kullback-Leibler(KL)散度来测量:
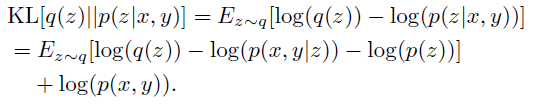
上述内容可以重写为:
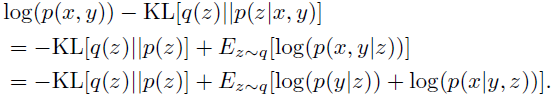
条件生成方法[16,27],它使用标签信息作为优先目标,以分离隐空间中的样式和内容。在我们的设置中,隐变量z应该包含[28]中的标签信息。这主要是由于两个原因:首先,隐空间的分布应该由攻击者根据其标签来限制,这使得攻击者能够使用梯度来修改生成的图像;其次,如[10]所述,分类器的判断是由隐空间中的伪度量决定的空间。因此,我们将p(x|y,z)替换为p(x|z),因为z包含标签信息y。然后,p(x,y)的下界可以以下式给出:
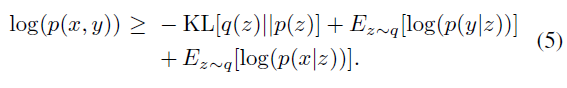
为了简化优化过程,我们选择q(z)为隐空间中依赖于x的高斯函数,这也是在[5]中假设的。具体而言,q(z|x) = N(μ(x; θenc), σ(x; θenc)),由此使SVAE最大化:
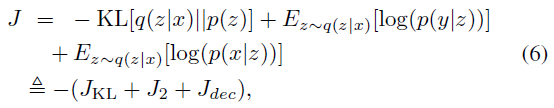
其中这三项分别对应于SVAE模型中的编码器、分类器和解码器。SVAE中的分类器对隐变量施加限制,通过解码器生成具有所需标签的图像。
一般来说,由数据训练的分类器只适合于数据隐空间中的流形,但可能在外部有较差表现[29]。由于我们直接根据攻击者和被攻击分类器的梯度对隐变量进行迭代操作,因此需要一个判别器来防止隐变量在攻击时位于隐空间的流形之外。因此,攻击者可以在鉴别器的约束下为隐变量的更新提供一个稳定有效的方向。在SVAE中,隐变量的分布是标准高斯分布,这使得基于样本的判别器成为可能。具体地,在输出层上设计具有sigmoid激活函数的二值鉴别器,以区分解码器从输入图像编码得到的真实隐变量值和从高斯分布随机采样的虚假隐变量值:
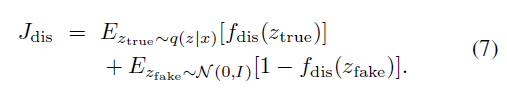
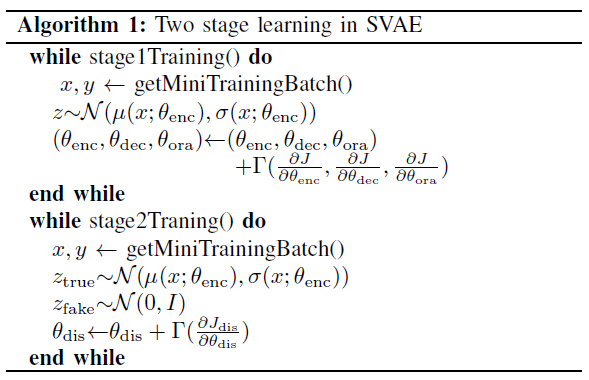
本文采用两阶段优化方法对SVAE进行训练。在第一阶段,我们同时训练编码器、解码器和分类器以最大化目标函数(6)。编码器函数fenc将输入x映射为高斯分布,其均值和方差分别为μ(x; θenc)和σ(x; θenc)。通过重参数化技巧[5],从这样的高斯分布中采样一个隐变量z,然后将其分别用于分类和重建为f2和fdec。采用梯度下降法Γ,如Adam,训练参数θenc,θ2和θdec,分别对应于fenc、f2和fdec。
在第二阶段中,我们在训练完第一阶段之后,基于良好定位的编码器,训练判别器fdis以最大化(7)。输入x首先被编码成在隐空间中具有均值μ(x)和方差σ(x)的高斯函数。然后正例从ztrue(服从N(μ(x; θenc), σ(x; θenc)))中采样,反例从标准高斯分布zfake中采样。采用梯度下降法只更新鉴别器fdis中的参数dis。算法1描述了这种两阶段优化算法。
基于经过训练的SVAE,我们将从(2)中描述的原始样本x生成一个I型对抗样本x',使得x'和x在f2视图中具有不同的标签,但被f1识别为同一类。第一步也是更简单的一步是将输入图像x转换为另一个具有不同标签的图像x',这是图像转换任务。在我们的框架中,类信息不是直接给出的,例如,在条件生成方法中,而是来自攻击者的监督项。隐变量根据f2的梯度进行迭代修正,并通过解码器恢复成图像。具体地说,生成目标样本的目标函数是:
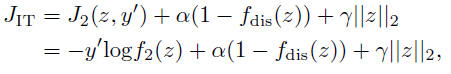
其中交叉熵损失被应用于f2,它是分类任务中的常见选择[1,2]。此外,为了防止z在隐空间中移动到流形的外部,还加入了一个具有来自鉴别器fdis的权重α的损失项。利用带权重γ的z上的l2正则化项,将z限制在标准高斯空间中作为流形的环境空间。
在这里,我们利用所建立的方法对MNIST的数字图像和CelebA的人脸图像进行图像转换。对于MNIST数据集,建立了一个测试精度为98.64%的分类器,并将其用于图像转换:从图像“i”到生成“i+1”。对于CelebA,建立了一个测试准确率为94.9%的性别分类器,用于改变图像的性别。图5展示了转换性能,其中左列表示原始图像,右列示出具有所需标签的生成图像,中间列是不同迭代中的临时图像。
注意,图像转换任务不同于特征转换,其典型路径是建立语义特征并更改所需的语义特征;参见,例如Fader Networks[30]和Deep Feature Interpolation[31]。这里的图像转换是在分类器f2的指导下实现的。对于视觉性,我们选择了f2作为性别分类器,但它不需要语义,而且可以是综合的。这种差异也可以从视觉上观察到:由于特征已被分离,由Fader Networks生成的面部看起来与原始面部非常相似;而在图5(b)中,生成的面部和原始面部可视为不同的人。

C. Generating Adversarial Examples for Type I Attack
在上面的图像转换任务中,我们成功地生成了带有所需标签的新样本。此外,如图4所示,结合被攻击的分类器f1,我们尝试保持f1的输出不变,即,生成如(2)所述的I型对抗样本。对于分类器f1,通过最小化以下函数生成具有原始标签y的输入x的目标标签为y'的对抗样本x',其中训练过的SVAE模型是攻击者,
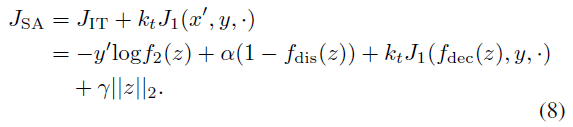
这里,J1(x',·)是被攻击分类器的损失函数,对于不同的任务可以采用不同的公式。在多类分类任务中,例如[1,2],f1(x)是每个类的概率向量。而在人脸识别任务[32]中,f1(x)是一个特征向量,其中小距离||f1(x') - f1(x)||2表示x和x'趋向于同一个人。对于这两个任务,可以将J1(x',·)设置如下:
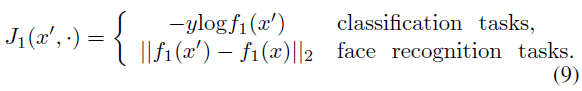
在(8)中,有一个正参数kt反映了我们为保持受到攻击的分类器f1不变而施加的压力。在我们的方法中,kt可以根据不同的迭代而变化。通常,在开始时,我们允许f1输出的变化来真正改变图像。稍后,kt增大以将图像拉回来,使得f1的输出与原始的一样。特别地,为kt设计了自适应权重策略以保持这种平衡:
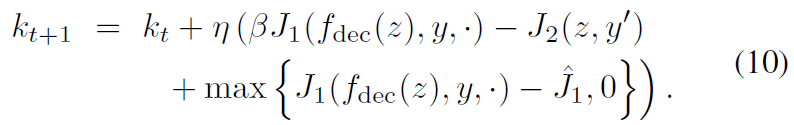
在我们的实验中,在多次迭代中增加平衡权重之后,kt被裁剪成[0,0.001]。受[33]的启发,超参数β控制损失J1和J2之间的平衡,(该平衡)设置为
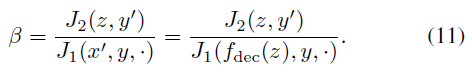
较低的β意味着生成的对抗性样本x'更可能属于目标标签y',然而认为f2中f2(x) ≠ f2(x')的概率较高。在(10)中,另一项^J1被用作被攻击分类器的目标值。在Hingo损失项中引入此项,以在f1中适当牺牲一点置信度,使输入图像更集中于f2,从而使输入图像真正成为具有不同类别的新图像。此项可提高I型攻击的图像质量和成功率。
在所有这些网络经过良好训练后,我们迭代更新隐变量z以最小化(8)中的目标函数。首先,我们根据给定的输入x,将z初始化为高斯分布zinit = μ(fenc(x))的均值。类似于训练网络,我们在这里使用Adam[34]迭代地优化隐变量z。算法2说明了生成I型对抗样本的总体算法(译者注:优化隐变量z中的+应该为-,因为最小化应该是沿负梯度方向移动;最后应该是通过解码器fdec而不是fenc得到最终的结果图)。显然,0在分类和识别任务中都是JSA的下界。因此,采用梯度下降法进行JSA优化时,保证了算法的收敛性。代码在补充材料(SM)中提供,并将在未来发布。

对抗性攻击揭示了神经网络的弱点,为分析神经网络提供了工具。虽然现有的大多数攻击都是针对图像输入的,但是攻击可能发生在非图像数据上。最近,[15]设计了一个对隐空间的有趣攻击。假设z是隐空间中的原始向量,攻击是生成z',使得||z - z'||很小,但是通过生成模型,例如AC-GAN[17]在[15]中使用,生成的图像G(z)和G(z')被攻击的分类器f1错误地识别为不同的类,即f1(G(z)) ≠ f1(G(z'))。原始z可以是给定的,也可以是随机生成的。这种攻击去掉了编码器,适用于非图像数据。
从上面的描述可以看出[15]中设计的攻击属于II型攻击。同时,我们也可以设计对隐空间的I型攻击,这在数学上被描述为以下问题,
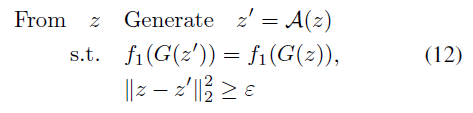
其中f1是被攻击的分类器,G是生成模型,且ε是用户定义的阈值。实际上,(12)是(2)的一个特例,我们使用一个基于简单距离的分类器作为攻击者。基本上,沿着流形中f1(G(z))保持恒定的方向,我们可以偏离z,在隐空间上找到I型对抗样本。具体来说,这些对抗样本可以通过最小化以下损失函数而产生,
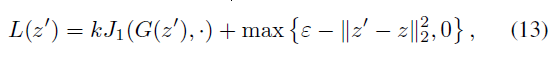
其中,J1定义为(9),G是一个事先经过训练的生成模型,k是一个权衡参数。(13)中的第一项迫使f1判断生成的两个样本G(z')和G(z)是同一类,而第二项鼓励z'偏离原始z。较小的k意味着我们允许f1有较大的变化,以便在隐空间中获得较大的距离。我们可以像(10)一样设计一个k的自适应策略,但在本文中,我们在整个过程中保持k不变。如果辅助分类器在G中建模,如AC-GAN[17]并用fG表示,那么我们也可以最小化fG(z')和ytarget的差异来分配目标标签,否则,攻击是非目标的。
在这一部分中,我们验证了针对这种新型对抗攻击提出的方法。主要有两个问题:①所提出的方法是否能显著地改变图像,但保持攻击的分类器不变;②是否存在与现有对抗攻击的本质区别。出于这两个目的,我们首先对MNIST数据集[35]和CelebA数据集[36]上的攻击进行验证,前者将新生成的数字识别为原始数字,后者将生成具有不同性别但被识别为同一个人的新人脸图像。之后,我们应用防御方法来防御攻击。I型和II型攻击的不同性能证实了它们的本质区别。最后,对隐空间上的I型攻击进行了评估,这也表明了对I型攻击使用不同生成模型的可能性。
对于SVAE训练,我们使用Adam[34],学习率为0.0002。在(8)中的超参数α和γ分别设置为0.01和0.0001。(10)中用于平衡的β是0.001。在攻击迭代过程中,利用Adam更新隐变量z,学习率为0.005。(10)中的目标损失^J1被设置为0.01,作为数字图像分类任务的交叉熵损失;^J1被设置为1.00,作为人脸识别任务的欧氏距离。SVAE结构的细节在SM中提供。对于数据集,MNIST包含60K个28x28大小的手写数字图像。在普通分割之后,我们使用50K个图像进行训练,然后利用剩余的图片进行测试。CelebA数据集包含超过20万张带有40个属性标注的人脸图像。我们只需根据性别标签将CelebA数据集分割为男性/女性子集,然后将其标准化并居中裁剪为64x64大小。本文的所有实验都是在一个12GB显存的NVIDIA TITAN X GPU上用Tensorflow[37]实现的。
A. Type I Attack on Digits Classifier
首先利用该方法攻击在MNIST数据集上训练的分类器。被攻击的分类器f1是一个包含128个隐藏单元的MLP,测试误差为2.73%。我们训练了一个SVAE模型,它有1.36%的测试误差,充当攻击者f2。然后,从一个已经被f1正确分类的给定图像中,我们应用算法2生成一个对抗样本。目标是将"i"改为"i+1",但f1仍错误地将其归类为"i"。

在图6中,我们展示的是当SVAE试图进行I型攻击以将图像从"4"转换为"5",而MLP仍将其分类为"4"时,攻击者f2、鉴别器fdis和多层感知机(MLP)f1的对数损失项。上面的图像是在相应的迭代中生成的对抗样本x'。注意,f2的损失是相对于y'=5的,而f1的损失是相对于y=4的。因此,在开始时,由于原始图像是数字"4",f2的损失远远高于f1。然后,通过最小化(8)中的JSA,当f1的损失增加时,图像逐渐转换为数字"5",因为目标损失^J1被设置为0.01,并且(10)中J1的权重被裁剪为0。同时,由于隐变量必须在隐空间中超越流形,因此鉴别器的损失也在增加。当J1增加超过^J1且J2低于(11)中描述的平衡时,J1的自适应权重kt增加以拉低J1直到收敛。尽管攻击者f2的损失在开始时迅速减少,但是来自攻击者的监督信息并不十分可靠,因为它的性能在隐空间的流形之外是不可预测的。因此,判别器在抑制隐变量进入流形中起着关键作用,使得SVAE中的分类器能够提供可信的梯度。
在图7(a)中,我们展示了对数字分类器的I型攻击的一些样例。原始图像绘制在左栏,生成的图像绘制在右栏,图像之间呈现出逐渐变化的过程。每个图像顶部标记的数字表示被攻击分类器f1给出的原始类的置信度。在攻击过程中,置信度将先下降后上升,这与我们在算法2中设置的k一致,如第III.C节所述。


B. Type I Attack on Face Recognizer
接下来,我们评估对人脸识别器FaceNet[32]的攻击。我们直接使用在CelebA上训练的FaceNet进行人脸识别,它在LFW[38]数据集上达到99.05%的准确率。在我们的实验中,同样的面部识别、白化和其他预处理程序都是按照[32]推荐的进行的。在CelebA数据集上训练SVAE,其性别分类f2的准确率为94.9%。我们的任务是改变一个形象的性别,但要让它被FaceNet识别为同一个人。这项任务和上一项任务有一个有趣的区别。在前面的任务中,攻击者比被攻击的分类器强。但对于这项任务,SVAE分类精度要低于被攻击的FaceNet。而且,同一性别是同一个人的必要条件,FaceNet的网络结构也更加复杂和深入。即使在f1强于f2的情况下,提出的I型攻击也可能成功。
图7(b)给出了一些典型的对抗样本。对于每一对,左边的脸在CelebA中,右边的脸由算法2生成。图像上方的数字是FaceNet给出的距离,对于该距离,由[32]建议相同人的阈值为1.242。
为了评估I型攻击的成功率,我们从CelebA中验证集的前1000个图像中生成对抗样本。当攻击成功时,我们的意思是图像对(x,x')满足三个条件:i)f1(x)=f1(x'),即两张脸被FaceNet识别为相同的人;ii)f2(x)≠f2(x'),即在f2看来,不同性别的人不是同一个人;iii)x'确实是一张脸。后两个标准由30名评论者评判,平均成功率为69.8%。所有生成的脸都在SM中有提供,以供参考。
C. Type I Attack Defenses by Detecting
以上两个实验验证了生成I型对抗样本的有效性。如前所述,II型攻击反映了过度敏感,I型攻击依赖于分类器的过度稳定性。由于潜在的原因是不同的,我们期望通过检测对手的输入来设计用于II型攻击的防御策略对I型攻击没有多大帮助。
为了验证这一推论,我们使用所提出的方法来攻击具有特征压缩防御策略的MLP[39],这是最有效的防御策略,并且显示了对抗许多现有II型攻击的巨大潜力。特征压缩防御策略是通过减少可用于对抗样本的输入特征的程度来检测对抗样本。具体地,它计算输入样本的分类器预测(例如,softmax层的输出)与其压缩样本之间的距离。如果距离大于给定的阈值,则防御方法将输入样本视为对抗样本,拒绝对该样本进行分类。防御策略概括如下:
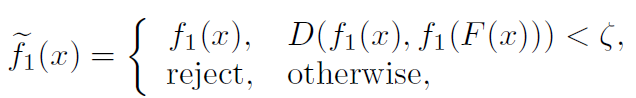
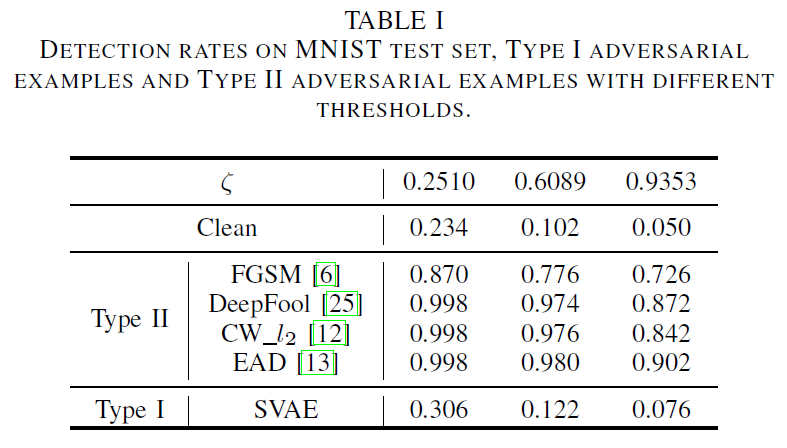
其中F(x)是特征压缩策略,D(·,·)是距离度量,ζ是一个超参数,用作判断输入x是否是对抗样本(然后拒绝它)的阈值。遵照在[39]中的公共设置,为特征压缩策略F设置了具有一位深度缩减和2×2中值平滑的联合压缩器,其呈现出如[39]中所示的最高检测率。选择欧氏距离作为距离度量D。在MNIST测试集上随机抽取500个样本,计算干净测试样本、I型对抗样本和II型对抗样本在不同阈值下的检测率。算法2(SVAE)、FGSM[6]、DeepFool[25]、CW[12]和EAD[13]分别生成了I型和II型的对抗样本。表I列出了干净样本、I型对抗样本和II型对抗样本的检测率,即检测器识别为对抗样本的比率。对于不同的ζ值,干净样本和I型对抗样本的检测率没有显著差异,这意味着I型对抗样本不能很好地与干净的数据区分开来。相比之下,II型对抗样本的检测率明显高于干净数据,说明特征压缩是一种很好的II型攻击检测方法,但对I型攻击不起作用。
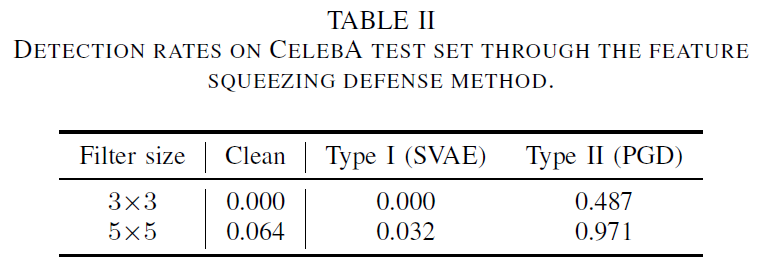
在攻击FaceNet中也可以观察到类似的特征压缩现象,如第IV.B节所述,生成1000个I型对抗样本。通过投影梯度下降(PGD,[14])生成相同数量的II型对抗样本。我们将ζ设为1.2,并考虑平滑核的不同大小。检测率见表II,表明特征压缩对I型攻击没有帮助,因为I型攻击不是建立在增加噪声的基础上的。
D. Type I Attack Defenses by Strengthening
反馈对抗样本对分类器进行重训练是提高网络鲁棒性的另一种方法。接下来,我们使用MNIST数据集测试了为II型对抗样本设计的Adversarial Logit Pairing[40]的防御性能。被攻击的分类器是LeNet[41]。在强化后,使用攻击原始网络生成的对抗样本进行验证。II型攻击的准确率提高到98.5%,因为最小化成对逻辑回归配对损失L(f(x),f(x')),这需要在原始样本x和对抗样本x'之间保持很小的距离。但是,此设置不适用于I型攻击:如果x'是由I型攻击生成的,则x和x'不属于同一类,并且L(f(x),f(x'))不应很小。在我们的实验中,I型攻击的准确率仅为14.2%,验证了逻辑回归配对技术不能直接用于I型对抗样本。
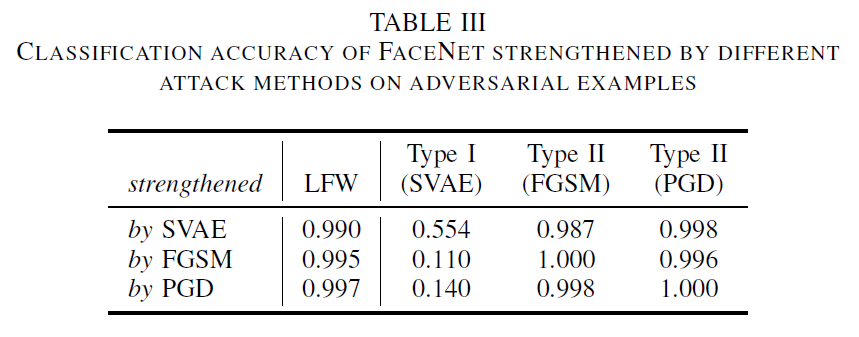
正如[42]所建议和数值验证的那样,根据不同模型和攻击方法之间的可迁移性,添加其他攻击产生的对抗样本是有帮助的。一个有趣的问题是,防御一种对抗攻击的能力是否有助于对抗另一种攻击。为了回答这个问题,我们分别用I型、II型(FGSM)和II型(PGD)对抗样本来加强FaceNet。对于II型攻击,我们使用对抗逻辑回归配对方法。对于I型攻击,对抗逻辑回归配对没有如前所示的帮助,因此我们转向普通的对抗训练。具体地说,通过攻击原始网络而产生的对抗样本被随机分成两部分,概率相等。其中一个子集与LFW数据集一起返回,用于对抗训练。然后在其余的对抗样本上对增强的FaceNets进行评估。分类准确率见表III。对角线表示在相同攻击方法下,通过对抗训练防御对抗性攻击的性能。其他因素显示了对抗训练的可迁移性。可以发现,通过FGSM增强FaceNet可以提高对PGD的鲁棒性,反之亦然。然而,通过II型对抗样本进行增强对防御I型攻击的效果很小,显示出它们的差异。
E. Type I Attack on Latent Space
在最后一个实验中,我们将考虑对隐空间的I型攻击。攻击可能发生在非图像数据上。但是为了使性能可视化,我们应用生成模型将隐向量传输到图像。攻击设计独立于生成模型。为了攻击MNIST上的LeNet[41],我们选择AC-GAN[17],这也在[15]中被使用。在CelebA上攻击FaceNet时,我们使用StyleGAN[18],这是最先进的生成模型之一。我们在MNIST上训练了一个具有128个隐特征的AC-GAN,并使用了由[18]提供的具有512个隐特征的StyleGAN。由于这些生成模型只影响视觉质量,而对攻击性能没有影响,因此我们在此不报告它们的结构和训练细节。基于训练的生成模型,我们通过最小化(13)来攻击分类器f1,其中攻击LeNet的超参数分别设置为k=10-2,ε=0.1,攻击FaceNet的超参数分别设置为k=10-3,ε=0.35。使用学习率为0.01的Adam。
在图8中,通过由AC-GAN绘制生成图像(在28x28中)来显示对隐空间的I型攻击。这些数字的每一对在视觉上是不同的,然而,它们被攻击的LeNet识别为同一类。由于AC-GAN有一个辅助分类器,我们可以利用这个分类器来设置目标标签。

在图9中,我们在StyleGAN的隐空间上显示了由I型对抗攻击生成的6个人脸序列。由于StyleGAN强大的生成能力,对抗图像的大小为1024x1024。从每排的左脸开始,攻击会显著改变外观。然而,被攻击的FaceNet仍然认为他们是同一个人。与图7(b)所示的攻击不同,基于StyleGAN的攻击不能控制改变方向,例如从男性到女性或相反。未来,基于StyleGAN或其他生成模型实现有针对性的I型攻击具有重要意义。

假阳性(FP)和假阴性(FN)的比率是衡量分类器性能的重要指标,因此,针对假阳性的对抗攻击(本文提出的I型攻击)和针对假阴性的对抗攻击(目前流行的II型攻击)都值得研究。特征空间的不一致性使得分类器容易受到攻击。但I型和II型攻击的根本原因是不同的:I型攻击依赖于攻击者利用被攻击分类器忽略的缺失特征,而II型攻击则修改了对攻击者没有意义但是被攻击分类器关注的不必要特征。
产生假阳性就是通过显著的变化欺骗分类器。生成目标是一个全新的样本,被攻击的分类器会错误地将其分类到原始样本的同一类中。针对I型对抗攻击,设计了一种有监督的变分自动编码框架。在这个框架中,攻击者被显式地建模以提供监督信息,从而生成一个新的有意义的对抗样本。然后根据攻击者和被攻击分类器的梯度信息,通过修正隐空间中的隐变量,建立了一种I型攻击的生成算法,而不是直接在图像空间中操作,最终导致噪声的产生,然后通过解码器将更新后的变量恢复成图像。为了从攻击者那里获得稳定且可信的梯度,设计了一个判别器,通过迭代生成算法限制隐变量在流形上的位置。
在数值实验中,该方法成功地生成了I型对抗样本来欺骗训练有素的分类器。这些样本中的大多数都能通过特征压缩检测,这是一种有效的II型攻击检测方法,暗示了I型和II型攻击的不同本质原因。由于这种差异,目前的强化方法不具备类型交叉能力,即通过II型对抗样本对神经网络进行再训练,对防御I型攻击没有好处。一般来说,I型对抗攻击是一种新的对抗攻击,对理解神经网络具有重要意义。该方法是一种生成I类对抗样本的方法,其它具有自动编码和生成能力的结构对I型攻击也有一定的应用前景,可用于分类器评估、分类器重训练和特征分析。
Adversarial Attack Type I: Cheat Classifiers by Significant Changes的更多相关文章
- Exploring Adversarial Attack in Spiking Neural Networks with Spike-Compatible Gradient
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! arXiv:2001.01587v1 [cs.NE] 1 Jan 2020 Abstract 脉冲神经网络(SNN)被广泛应用于神经形态设 ...
- Burp - Attack type
有时间不用难免忘记,做个总结 1. Sniper (狙击手) 它使用一组Payload集合,依次替换Payload位置上(一次攻击只能使用一个Payload位置)被§标志的文本(而没有被§标志的文本将 ...
- XSS (Cross Site Scripting) Prevention Cheat Sheet(XSS防护检查单)
本文是 XSS防御检查单的翻译版本 https://www.owasp.org/index.php/XSS_%28Cross_Site_Scripting%29_Prevention_Cheat_Sh ...
- 游戏编程技巧 - Type Object
Type Object 使用场景 你在制作一款和LOL类似的游戏,里面有许多英雄,因此你想建立一个英雄基类,然后把各种英雄都继承自该基类,这些英雄类都有生命值和攻击力等属性.每次策划想增加一个英雄,你 ...
- 生成对抗网络(Generative Adversarial Networks,GAN)初探
1. 从纳什均衡(Nash equilibrium)说起 我们先来看看纳什均衡的经济学定义: 所谓纳什均衡,指的是参与人的这样一种策略组合,在该策略组合上,任何参与人单独改变策略都不会得到好处.换句话 ...
- 《Attack ML Models - 李宏毅》视频笔记(完结)
Attack ML Models - 李宏毅 https://www.bilibili.com/video/av47022853 Training的Loss:固定x,修改θ,使y0接近ytrue. N ...
- Inherent Adversarial Robustness of Deep Spiking Neural Networks: Effects of Discrete Input Encoding and Non-Linear Activations
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! arXiv:2003.10399v2 [cs.CV] 23 Jul 2020 ECCV 2020 1 https://github.com ...
- One Pixel Attack for Fooling Deep Neural Networks
目录 概 主要内容 问题描述 Differential Evolution (DE) 实验 Su J, Vargas D V, Sakurai K, et al. One Pixel Attack f ...
- [C1] Andrew Ng - AI For Everyone
About this Course AI is not only for engineers. If you want your organization to become better at us ...
随机推荐
- Spring+hibernate+JSP实现Piano的数据库操作---4.配置文件
1.applicationContext.xml <?xml version="1.0" encoding="UTF-8"?> <beans ...
- 线程_FIFO队列实现生产者消费者
import threading # 导入线程库 import time from queue import Queue # 队列 class Producer(threading.Thread): ...
- 使用 MySQLi 和 PDO 向 MySQL 插入多条数据
PHP MySQL 插入多条数据 使用 MySQLi 和 PDO 向 MySQL 插入多条数据 mysqli_multi_query() 函数可用来执行多条SQL语句. 以下实例向 "MyG ...
- 经验分享:一个 30 岁的人是如何转行做程序员,进入IT行业的?
大约一年以前,我成为了一名全职开发者,我想要总结一下这一年的经验,并且和所有人分享,一个 30 多岁的人是如何进入科技行业的: 改变职业是一件吓人的事情,有时候还会成为一件危险的事情.年龄越大,危险就 ...
- 使用hibernate validate做参数校验
1.为什么使用hibernate validate 在开发http接口的时候,参数校验是必须有的一个环节,当参数校验较少的时候,一般是直接按照校验条件做校验,校验不通过,返回错误信息.比如以下校验 ...
- 使用Flask开发简单接口(4)--借助Redis实现token验证
前言 在之前我们已开发了几个接口,并且可以正常使用,那么今天我们将继续完善一下.我们注意到之前的接口,都是不需要进行任何验证就可以使用的,其实我们可以使用 token ,比如设置在修改或删除用户信息的 ...
- 【BZOJ4631】踩气球 题解(线段树)
题目链接 ---------------------- 题目大意:给定一个长度为$n$的序列${a_i}$.现在有$m$个区间$[l_i,r_i]$和$q$个操作,每次选取一个$x$使得$a_x--$ ...
- aria2使用ajax调用/页面浏览器RPC调用aria2
@ 目录 1. aria2使用ajax调用/页面浏览器RPC调用aria2 1.1. 总结: 1.2. ajax调用aria2-Demo 1.3. postMan命令测试 1.3.1. post基本使 ...
- Python3中,map()函数、filter()函数、reduce()函数的比较
1.map(function,iterable):function为函数,或者lambda表达式,iterable是可迭代的序列,即对iterable中的每个item执行一遍function或者lam ...
- Springboot常用的注解
1.@Controller主要用来修饰类,用来处理http请求 2.@ResponseBody主要用来修饰类和方法.返回字符串和json数据,不用来返回模板. 3.@RestController主要用 ...