浅析Redis与IO多路复用器原理
为什么Redis使用多路复用I/O
Redis 是跑在单线程中的,所有的操作都是按照顺序线性执行的,但是由于读写操作等待用户输入或输出都是阻塞的,所以 I/O 操作在一般情况下往往不能直接返回,这会导致某一文件的 I/O 阻塞导致整个进程无法对其它客户提供服务,而 I/O 多路复用就是为了解决这个问题而出现的。
多路复用与传统阻塞IO的区别
在传统阻塞 I/O 模型中,如果对某一个文件描述符(File Descriptor ,FD)进行 read 或 write 时,如果当前 FD 不可读或不可写,那么就会一直等待着Kernel进行数据准备,通常是从磁盘后者网卡读入到内核态,然后Redis进行读取,这整个过程中, Redis 服务就不会对其它的操作作出响应,一直在等待Kernel准备数据,导致整个服务不可用。

I/O 多路复用
阻塞式的 I/O 模型并不能满足这里的需求,寻思寻思,Redis就一个线程,要是使用阻塞IO,那效率得多低,我们需要一种效率更高的 I/O 模型来支撑 Redis 的单线程应对多个客户(redis-cli),这里涉及的就是 I/O 多路复用模型了:
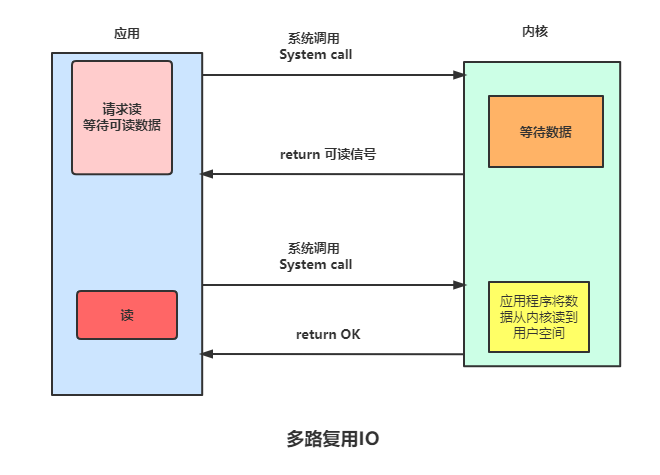
在 I/O 多路复用模型中,最重要的函数调用就是 select,该方法的能够同时监控多个文件描述符的可读可写情况,当其中的某些文件描述符可读或者可写时,select 方法就会返回可读以及可写的文件描述符个数。
在后期,有一些其他的多路复用函数,例如Poll、Epoll。
关于Select、Poll、Epoll的区别,可以参考:多路复用器Select、Poll、Epoll区别梳理
I/O 多路复用模块
I/O 多路复用模块封装了底层的 select、Poll、epoll、avport 以及 kqueue 这些 I/O 多路复用函数,为上层提供了相同的接口。

在这里我们简单介绍 Redis 是如何包装 select 和 epoll 的,简要了解该模块的功能,整个 I/O 多路复用模块抹平了不同平台上 I/O 多路复用函数的差异性,提供了相同的接口:
static int aeApiCreate(aeEventLoop *eventLoop)static int aeApiResize(aeEventLoop *eventLoop, int setsize)static void aeApiFree(aeEventLoop *eventLoop)static int aeApiAddEvent(aeEventLoop *eventLoop, int fd, int mask)static void aeApiDelEvent(aeEventLoop *eventLoop, int fd, int mask)static int aeApiPoll(aeEventLoop *eventLoop, struct timeval *tvp)
同时,因为各个函数所需要的参数不同,我们在每一个子模块内部通过一个 aeApiState 来存储需要的上下文信息:
// select
typedef struct aeApiState {
fd_set rfds, wfds;
fd_set _rfds, _wfds;
} aeApiState;
// epoll
typedef struct aeApiState {
int epfd;
struct epoll_event *events;
} aeApiState;
这些上下文信息会存储在 eventLoop 的 void *state 中,不会暴露到上层,只在当前子模块中使用。
封装 select 函数
select可以监控 FD 的可读、可写以及出现错误的情况。
在介绍 I/O 多路复用模块如何对 select 函数封装之前,先来看一下 select 函数使用的大致流程:
int fd = /* file descriptor */
fd_set rfds;
FD_ZERO(&rfds);
FD_SET(fd, &rfds)
for ( ; ; ) {
select(fd+1, &rfds, NULL, NULL, NULL);
if (FD_ISSET(fd, &rfds)) {
/* file descriptor `fd` becomes readable */
}
}
- 初始化一个可读的
fd_set集合,保存需要监控可读性的 FD; - 使用
FD_SET将fd加入rfds; - 调用
select方法监控rfds中的 FD 是否可读; - 当
select返回时,检查 FD 的状态并完成对应的操作。
而在 Redis 的 ae_select 文件中代码的组织顺序也是差不多的,首先在 aeApiCreate 函数中初始化 rfds 和 wfds:
static int aeApiCreate(aeEventLoop *eventLoop) {
aeApiState *state = zmalloc(sizeof(aeApiState));
if (!state) return -1;
FD_ZERO(&state->rfds);
FD_ZERO(&state->wfds);
eventLoop->apidata = state;
return 0;
}
而 aeApiAddEvent 和 aeApiDelEvent 会通过 FD_SET 和 FD_CLR 修改 fd_set 中对应 FD 的标志位:
static int aeApiAddEvent(aeEventLoop *eventLoop, int fd, int mask) {
aeApiState *state = eventLoop->apidata;
if (mask & AE_READABLE) FD_SET(fd,&state->rfds);
if (mask & AE_WRITABLE) FD_SET(fd,&state->wfds);
return 0;
}
整个 ae_select 子模块中最重要的函数就是 aeApiPoll,它是实际调用 select 函数的部分,其作用就是在 I/O 多路复用函数返回时,将对应的 FD 加入 aeEventLoop 的 fired 数组中,并返回事件的个数:
static int aeApiPoll(aeEventLoop *eventLoop, struct timeval *tvp) {
aeApiState *state = eventLoop->apidata;
int retval, j, numevents = 0;
memcpy(&state->_rfds,&state->rfds,sizeof(fd_set));
memcpy(&state->_wfds,&state->wfds,sizeof(fd_set));
retval = select(eventLoop->maxfd+1,
&state->_rfds,&state->_wfds,NULL,tvp);
if (retval > 0) {
for (j = 0; j <= eventLoop->maxfd; j++) {
int mask = 0;
aeFileEvent *fe = &eventLoop->events[j];
if (fe->mask == AE_NONE) continue;
if (fe->mask & AE_READABLE && FD_ISSET(j,&state->_rfds))
mask |= AE_READABLE;
if (fe->mask & AE_WRITABLE && FD_ISSET(j,&state->_wfds))
mask |= AE_WRITABLE;
eventLoop->fired[numevents].fd = j;
eventLoop->fired[numevents].mask = mask;
numevents++;
}
}
return numevents;
}
封装 epoll 函数
Redis 对 epoll 的封装其实也是类似的,使用 epoll_create 创建 epoll 中使用的 epfd:
static int aeApiCreate(aeEventLoop *eventLoop) {
aeApiState *state = zmalloc(sizeof(aeApiState));
if (!state) return -1;
state->events = zmalloc(sizeof(struct epoll_event)*eventLoop->setsize);
if (!state->events) {
zfree(state);
return -1;
}
state->epfd = epoll_create(1024); /* 1024 is just a hint for the kernel */
if (state->epfd == -1) {
zfree(state->events);
zfree(state);
return -1;
}
eventLoop->apidata = state;
return 0;
}
在 aeApiAddEvent 中使用 epoll_ctl 向 epfd 中添加需要监控的 FD 以及监听的事件:
static int aeApiAddEvent(aeEventLoop *eventLoop, int fd, int mask) {
aeApiState *state = eventLoop->apidata;
struct epoll_event ee = {0}; /* avoid valgrind warning */
/* If the fd was already monitored for some event, we need a MOD
* operation. Otherwise we need an ADD operation. */
int op = eventLoop->events[fd].mask == AE_NONE ?
EPOLL_CTL_ADD : EPOLL_CTL_MOD;
ee.events = 0;
mask |= eventLoop->events[fd].mask; /* Merge old events */
if (mask & AE_READABLE) ee.events |= EPOLLIN;
if (mask & AE_WRITABLE) ee.events |= EPOLLOUT;
ee.data.fd = fd;
if (epoll_ctl(state->epfd,op,fd,&ee) == -1) return -1;
return 0;
}
由于 epoll 相比 select 机制略有不同,在 epoll_wait 函数返回时并不需要遍历所有的 FD 查看读写情况;在 epoll_wait 函数返回时会提供一个 epoll_event 数组:
typedef union epoll_data {
void *ptr;
int fd; /* 文件描述符 */
uint32_t u32;
uint64_t u64;
} epoll_data_t;
struct epoll_event {
uint32_t events; /* Epoll 事件 */
epoll_data_t data;
};
其中保存了发生的
epoll事件(EPOLLIN、EPOLLOUT、EPOLLERR和EPOLLHUP)以及发生该事件的 FD。
aeApiPoll 函数只需要将 epoll_event 数组中存储的信息加入 eventLoop 的 fired 数组中,将信息传递给上层模块:
static int aeApiPoll(aeEventLoop *eventLoop, struct timeval *tvp) {
aeApiState *state = eventLoop->apidata;
int retval, numevents = 0;
retval = epoll_wait(state->epfd,state->events,eventLoop->setsize,
tvp ? (tvp->tv_sec*1000 + tvp->tv_usec/1000) : -1);
if (retval > 0) {
int j;
numevents = retval;
for (j = 0; j < numevents; j++) {
int mask = 0;
struct epoll_event *e = state->events+j;
if (e->events & EPOLLIN) mask |= AE_READABLE;
if (e->events & EPOLLOUT) mask |= AE_WRITABLE;
if (e->events & EPOLLERR) mask |= AE_WRITABLE;
if (e->events & EPOLLHUP) mask |= AE_WRITABLE;
eventLoop->fired[j].fd = e->data.fd;
eventLoop->fired[j].mask = mask;
}
}
return numevents;
}
子模块的选择
因为 Redis 需要在多个平台上运行,同时为了最大化执行的效率与性能,所以会根据编译平台的不同选择不同的 I/O 多路复用函数作为子模块,提供给上层统一的接口;在 Redis 中,我们通过宏定义的使用,合理的选择不同的子模块:
#ifdef HAVE_EVPORT
#include "ae_evport.c"
#else
#ifdef HAVE_EPOLL
#include "ae_epoll.c"
#else
#ifdef HAVE_KQUEUE
#include "ae_kqueue.c"
#else
#include "ae_select.c"
#endif
#endif
#endif
因为 select 函数是作为 POSIX 标准中的系统调用,在不同版本的操作系统上都会实现,所以将其作为保底方案:
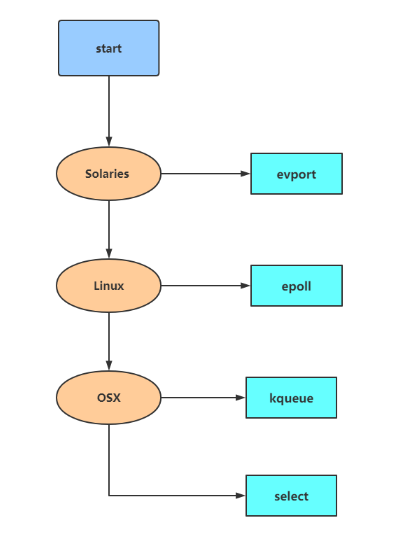
Redis 会优先选择时间复杂度为 \(O(1)\) 的 I/O 多路复用函数作为底层实现,包括 Solaries 10 中的 evport、Linux 中的 epoll 和 macOS/FreeBSD 中的 kqueue,上述的这些函数都使用了内核内部的结构,并且能够服务几十万的文件描述符。
但是如果当前编译环境没有上述函数,就会选择 select 作为备选方案,由于其在使用时会扫描全部监听的描述符,所以其时间复杂度较差 \(O(n)\),并且只能同时服务 1024 个文件描述符,所以一般并不会以 select 作为第一方案使用。
总结
Redis 对于 I/O 多路复用模块的设计非常简洁,通过宏保证了 I/O 多路复用模块在不同平台上都有着优异的性能,将不同的 I/O 多路复用函数封装成相同的 API 提供给上层使用。
整个模块使 Redis 能以单进程运行的同时服务成千上万个文件描述符,避免了由于多进程应用的引入导致代码实现复杂度的提升,减少了出错的可能性。
浅析Redis与IO多路复用器原理的更多相关文章
- 深入理解Redis主键失效原理及实现机制(转)
原文:深入理解Redis主键失效原理及实现机制 作为一种定期清理无效数据的重要机制,主键失效存在于大多数缓存系统中,Redis 也不例外.在 Redis 提供的诸多命令中,EXPIRE.EXPIREA ...
- Redis集群的原理和搭建(转载)
转载来源:https://www.jianshu.com/p/c869feb5581d Redis集群的原理和搭建 前言 Redis 是我们目前大规模使用的缓存中间件,由于它强大高效而又便捷的功能,得 ...
- IO多路复用原理&场景
目录 IO多路复用的历史 阻塞 IO 非阻塞 IO IO 多路复用 select poll epoll IO多路复用高效的原因 IO多路复用解决的什么问题 epoll比selector性能一定更好吗 ...
- Redis Cluster 分区实现原理
Redis Cluster本身提供了自动将数据分散到Redis Cluster不同节点的能力,分区实现的关键点问题包括:如何将数据自动地打散到不同的节点,使得不同节点的存储数据相对均匀:如何保证客户端 ...
- 利用多写Redis实现分布式锁原理与实现分析(转)
利用多写Redis实现分布式锁原理与实现分析 一.关于分布式锁 关于分布式锁,可能绝大部分人都会或多或少涉及到. 我举二个例子:场景一:从前端界面发起一笔支付请求,如果前端没有做防重处理,那么可能 ...
- Redis有序集内部实现原理分析(二)
Redis技术交流群481804090 Redis:https://github.com/zwjlpeng/Redis_Deep_Read 本篇博文紧随上篇Redis有序集内部实现原理分析,在这篇博文 ...
- 单片机小白学步系列(二十) IO口原理
IO口操作是单片机实践中最基本最重要的一个知识,本篇花了比較长的篇幅介绍IO口的原理. 也是查阅了不少资料,确保内容正确无误,花了非常长时间写的. IO口原理原本须要涉及非常多深入的知识,而这里尽最大 ...
- IO多路复用原理
(1)IO multiplexing(2)用在什么地方?多路非阻塞式IO.(3)select和poll(4)外部阻塞式,内部非阻塞式自动轮询多路阻塞式IO IO多路复用原理:其实就是整个函数对外表现为 ...
- redis实现cache系统原理(五)
1. 介绍 cache就是人们所说的缓存.我们这里所说的cache是web上的.对用户来说,衡量一个网站是否具有良好的体验,其中一个标准就是响应速度的快慢.可能网站刚上线,功能还较少,数据库的记录也不 ...
随机推荐
- C#未能找到路径“\bin\roslyn\csc.exe”的一部分。
主要原因是因为两个库存在,需要生成一个 roslyn文件,但是这个项目是从 vs2017中,打开的,所以,没有必要存在它. 那么就删除这两个关联的库,就可以达到目的 S2017 打开 程序包管理控制 ...
- Tomcat如何使用线程池处理远程并发请求
Tomcat如何使用线程池处理远程并发请求 通过了解学习tomcat如何处理并发请求,了解到线程池,锁,队列,unsafe类,下面的主要代码来自 java-jre: sun.misc.Unsafe j ...
- vue+element对常用表格的简单封装
在后台管理和中台项目中, table是使用率是特别的高的, 虽然element已经有table组件, 但是分页和其他各项操作还是要写一堆的代码, 所以就在原有的基础上做了进一步的封装 所涵盖的功能有: ...
- Oracle dd-m月-yy转yyyy-mm-dd
表名称:TEST_LP 字段:PROD_DATE 1 SELECT '20' || SUBSTR(T.PROD_DATE, INSTR(T.PROD_DATE, '-', 1, 2) + 1, 2) ...
- Thread通信与唤醒笔记1
synchronized if判断标记,只有一次,会导致不该信息的线程运行了,出现了数据错误的情况 while判断标记,解决了线程获取执行权之后,是否要运行! notify 只能唤醒一个任意线程,如果 ...
- 阿里云对象存储OSS及CDN加速配置
目录 十大云存储服务商 1. 登陆阿里云官网,开通对象存储服务 OSS 2. 创建存储空间 3. 绑定自定义域名 4. 配置阿里云CDN加速 5. 购买阿里云免费SSL证书 6. 阿里云CDN配置HT ...
- 入门Kubernetes -基础概念
一.Kubernetes概述 Kubernetes ,又称为 k8s(首字母为 k.首字母与尾字母之间有 8 个字符.尾字母为 s,所以简称 k8s)或者简称为 "kube" ,是 ...
- 附录 A ES6附加特性
目录 模板字符串 解构 对象的解构 数组的解构 增强版对象字面量 模板字符串 const student = { name: "Wango", age: 24, } // 普通字符 ...
- Java实现RS485串口通信
前言 前段时间赶项目的过程中,遇到一个调用RS485串口通信的需求,赶完项目因为楼主处理私事,没来得及完成文章的更新,现在终于可以整理一下当时的demo,记录下来. 首先说一下大概需求:这个项目是机器 ...
- C#处理医学图像(二):基于Hessian矩阵的医学图像增强与窗宽窗位
根据本系列教程文章上一篇说到,在完成C++和Opencv对Hessian矩阵滤波算法的实现和封装后, 再由C#调用C++ 的DLL,(参考:C#处理医学图像(一):基于Hessian矩阵的血管肺纹理骨 ...