CMU数据库(15-445)实验2-B+树索引实现(下+课上笔记)
4. Index_Iterator实现
这里就是需要实现迭代器的一些操作,比如begin、end、isend等等
下面是对于IndexIterator的构造函数
template <typename KeyType, typename ValueType, typename KeyComparator>
IndexIterator<KeyType, ValueType, KeyComparator>::
IndexIterator(BPlusTreeLeafPage<KeyType, ValueType, KeyComparator> *leaf,
int index_, BufferPoolManager *buff_pool_manager):
leaf_(leaf), index_(index_), buff_pool_manager_(buff_pool_manager) {}
1. 首先我们来看begin函数的实现
- 利用key值找到叶子结点
- 然后获取当前key值的index就是begin的位置
INDEX_TEMPLATE_ARGUMENTS
INDEXITERATOR_TYPE BPLUSTREE_TYPE::Begin(const KeyType &key) {
auto leaf = reinterpret_cast<BPlusTreeLeafPage<KeyType, ValueType,KeyComparator> *>(FindLeafPage(key, false));
int index = 0;
if (leaf != nullptr) {
index = leaf->KeyIndex(key, comparator_);
}
return IndexIterator<KeyType, ValueType, KeyComparator>(leaf, index, buffer_pool_manager_);
}
2. end函数的实现
- 找到最开始的结点
- 然后一直向后遍历直到
nextPageId=-1结束 - 这里注意需要重载
!=和==
end函数
INDEX_TEMPLATE_ARGUMENTS
INDEXITERATOR_TYPE BPLUSTREE_TYPE::end() {
KeyType key{};
auto leaf= reinterpret_cast<BPlusTreeLeafPage<KeyType, ValueType,KeyComparator> *>( FindLeafPage(key, true));
page_id_t new_page;
while(leaf->GetNextPageId()!=INVALID_PAGE_ID){
new_page=leaf->GetNextPageId();
leaf=reinterpret_cast<BPlusTreeLeafPage<KeyType, ValueType,KeyComparator> *>(buffer_pool_manager_->FetchPage(new_page));
}
buffer_pool_manager_->UnpinPage(new_page,false);
return IndexIterator<KeyType, ValueType, KeyComparator>(leaf, leaf->GetSize(), buffer_pool_manager_);
}
==和 !=函数
bool operator==(const IndexIterator &itr) const {
return this->index_==itr.index_&&this->leaf_==itr.leaf_;
}
bool operator!=(const IndexIterator &itr) const {
return !this->operator==(itr);
}
3. 重载++和*(解引用符号)
- 重载++
简单的index++然后设置nextPageId即可
template <typename KeyType, typename ValueType, typename KeyComparator>
IndexIterator<KeyType, ValueType, KeyComparator> &IndexIterator<KeyType, ValueType, KeyComparator>::
operator++() {
//
// std::cout<<"++"<<std::endl;
++index_;
if (index_ == leaf_->GetSize() && leaf_->GetNextPageId() != INVALID_PAGE_ID) {
// first unpin leaf_, then get the next leaf
page_id_t next_page_id = leaf_->GetNextPageId();
auto *page = buff_pool_manager_->FetchPage(next_page_id);
if (page == nullptr) {
throw Exception("all page are pinned while IndexIterator(operator++)");
}
// first acquire next page, then release previous page
page->RLatch();
buff_pool_manager_->FetchPage(leaf_->GetPageId())->RUnlatch();
buff_pool_manager_->UnpinPage(leaf_->GetPageId(), false);
buff_pool_manager_->UnpinPage(leaf_->GetPageId(), false);
auto next_leaf =reinterpret_cast<BPlusTreeLeafPage<KeyType, ValueType,KeyComparator> *>(page->GetData());
assert(next_leaf->IsLeafPage());
index_ = 0;
leaf_ = next_leaf;
}
return *this;
};
- 重载*
return array[index]即可
template <typename KeyType, typename ValueType, typename KeyComparator>
const MappingType &IndexIterator<KeyType, ValueType, KeyComparator>::
operator*() {
if (isEnd()) {
throw "IndexIterator: out of range";
}
return leaf_->GetItem(index_);
}
5. 并发机制的实现
0. 首先复习一下读写机制
- 读操作是可以多个进程之间共享latch的而写操作则必须互斥
- 加入
MaxReader数就是为了防止等待的️写进程饥饿
首先来看如果没有机制多线程会发生什么问题
- 线程T1想要删除44。
- 线程T2 想要查找41
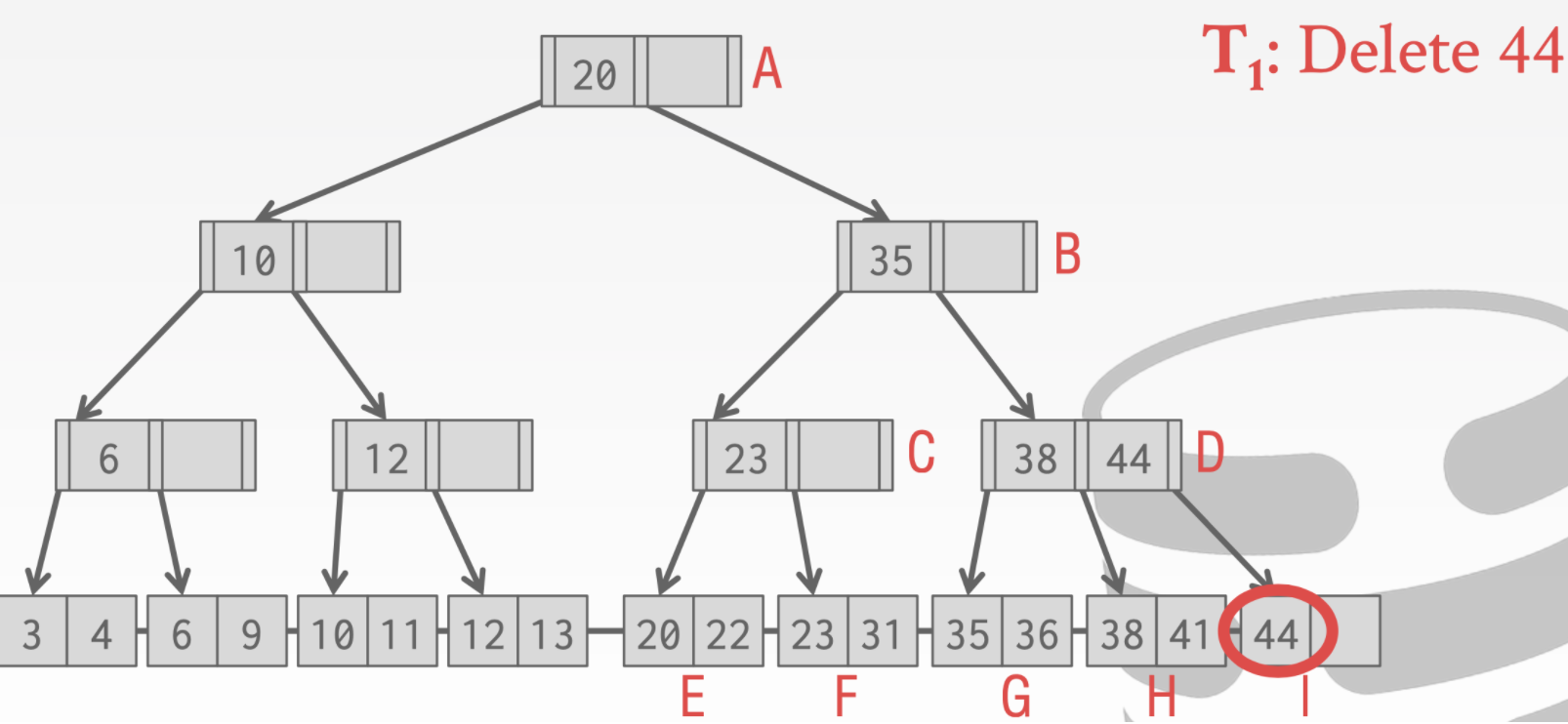
- 假设T2在执行到D位置的时候又切换到线程T1
- 这个时候T1进行重新分配,会把41借到I结点上
- T1执行完成切换回T2这时候T2再去原来的执行寻找41就会找不到
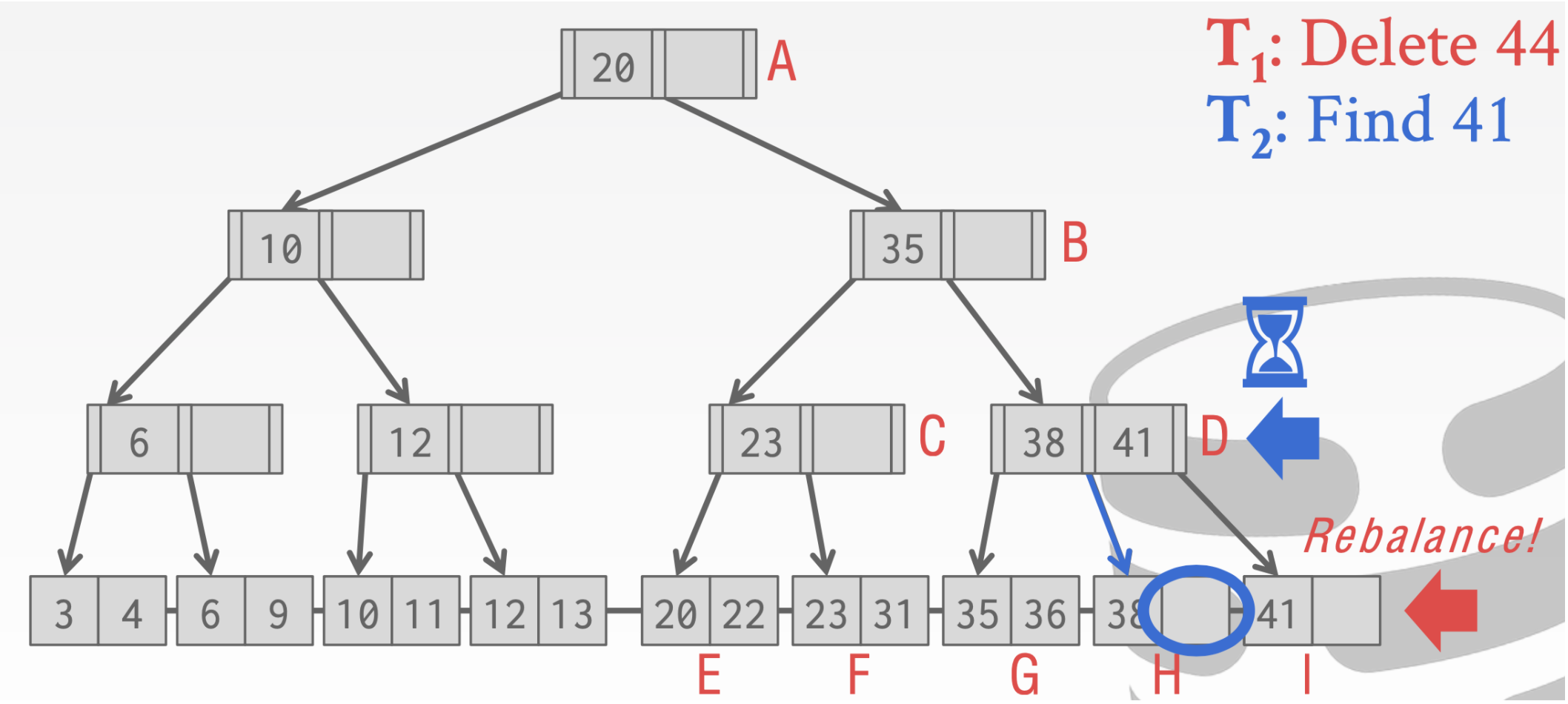
就会出现下面的情况。

由此我们需要读写的存在
- 对于find操作
由于我们是只读操作,所以我们到下一个结点的时候就可以释放上一个结点的Latch

剩下的操作都是一样的
- 对于
delete则不一样
因为我们需要写操作
这里我们不能释放结点A的Latch。因为我们的删除操作可能会合并根节点。

到D的时候。我们会发现D中的38删除之后不需要进行合并,所以对于A和B的写Write是可以安全释放了

- 对于
Insert操作
这里我们就可以安全的释放掉A的锁。因为B中还有空位,我们插入是不会对A造成影响的

当我们执行到D这里发现D中已经满了。所以此时我们不会释放B的锁,因为我们会对B进行写操作

上面的算法虽然是正确的但是有瓶颈问题。由于只有一个线程可以获得写Latch。而插入和删除的时候都需要对头结点加写Latch。所以多线程在有许多个插入或者删除操作的时候,性能就会大打折扣

这里要引入乐观
乐观的假设大部分操作是不需要进行合并和分裂的。因此在我们向下的时候都是读Latch而不是写Latch。只有在叶子结点才是write Latch
- 从上到下都是读Latch。而且逐步释放
- 到叶子结点需要修改的时候才为写Latch。这个删除是安全的所以直接结束

- 当我们到最后一步发现不安全的时候。则需要像上面我们没有引入乐观的时候一样。重新执行一遍

B-Link Tree简介
延迟更新父结点
这里用一个来标记这里需要被更新但是还没有执行

这个时候我们执行其他操作也是正确的比如查找31

这里我们执行insert 33
当执行到结点C的时候。因为这个时候有另一个线程持有了write Latch。所以这个时候操作要执行。随后在插入33

最后一点补充关于扫描操作的
- 线程1在C结点上持有write Latch
- 线程2已经扫描完了结点B想要获得结点C的read Latch
这时候会发生问题,因为线程2无法拿到read Latch
这里有几种解决方法
- 可以等到T1的写操作完成
- 可以重新执行T2
- 可以直接让线程T2停止抢得这个Latch。

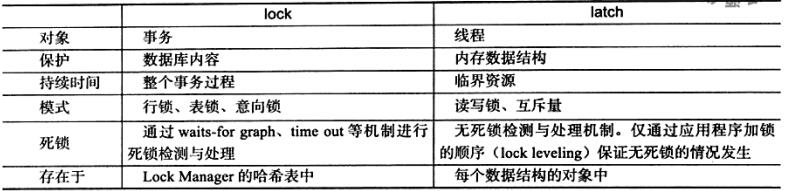
注意这里的Latch和Lock并不一样
1. 辅助函数UnlockUnpinPages的实现
- 如果是读操作则释放read锁
- 否则释放write锁
INDEX_TEMPLATE_ARGUMENTS
void BPLUSTREE_TYPE::
UnlockUnpinPages(Operation op, Transaction *transaction) {
if (transaction == nullptr) {
return;
}
for (auto page:*transaction->GetPageSet()) {
if (op == Operation::READ) {
page->RUnlatch();
buffer_pool_manager_->UnpinPage(page->GetPageId(), false);
} else {
page->WUnlatch();
buffer_pool_manager_->UnpinPage(page->GetPageId(), true);
}
}
transaction->GetPageSet()->clear();
for (const auto &page_id: *transaction->GetDeletedPageSet()) {
buffer_pool_manager_->DeletePage(page_id);
}
transaction->GetDeletedPageSet()->clear();
// if root is locked, unlock it
node_mutex_.unlock();
}
四个自带的解锁和上锁操作
/** Acquire the page write latch. */
inline void WLatch() { rwlatch_.WLock(); }
/** Release the page write latch. */
inline void WUnlatch() { rwlatch_.WUnlock(); }
/** Acquire the page read latch. */
inline void RLatch() { rwlatch_.RLock(); }
/** Release the page read latch. */
inline void RUnlatch() { rwlatch_.RUnlock(); }
这里的rwlatch是自己实现的读写锁类下面来探究一下这个类
由于c++ 并发编程我现在还不太会。。。所以就简单看一下啦后面学完并发编程再补充
WLock函数- 首先获取一个锁
- 用一个记号
writer_entered表示是否有写操作 - 如果之前已经有了现在的操作就需要等(这个线程处于阻塞状态)
- 当前如果有其他线程执行读操作。则仍需要阻塞(别人读的时候你不能写)
void WLock() {
std::unique_lock<mutex_t> latch(mutex_);
while (writer_entered_) {
reader_.wait(latch);
}
writer_entered_ = true;
while (reader_count_ > 0) {
writer_.wait(latch);
}
}
WunLock函数- 写标记置为false
- 然后通知所有的线程
void WUnlock() {
std::lock_guard<mutex_t> guard(mutex_);
writer_entered_ = false;
reader_.notify_all();
}
RLock函数- 如果当前有人在写或者已经有最多的人读了则阻塞
- 否则只需要让读的计数++
因为是允许多个线程一起读这样并不会出错
void RLock() {
std::unique_lock<mutex_t> latch(mutex_);
while (writer_entered_ || reader_count_ == MAX_READERS) {
reader_.wait(latch);
}
reader_count_++;
}
RUnLatch函数- 计数--
- 如果当前有人在写并且无人读的话需要通知所有其他线程
- 如果在计数--之前达到了最大读数,释放这个锁之后需要通知其他线程,现在又可以读了。
void RUnlock() {
std::lock_guard<mutex_t> guard(mutex_);
reader_count_--;
if (writer_entered_) {
if (reader_count_ == 0) {
writer_.notify_one();
}
} else {
if (reader_count_ == MAX_READERS - 1) {
reader_.notify_one();
}
}
}
6. Summary
好了终于磕磕绊绊的写完了Lab2.关于数据库的Lab2应该会停一段时间。这段时间要补一补深度学习(毕竟要毕业)然后赶工一下老师给的活。同时学一下c++并发编程和看一下侯捷老师的课程。
最后附上GitHub的
CMU数据库(15-445)实验2-B+树索引实现(下+课上笔记)的更多相关文章
- [已完结]CMU数据库(15-445)实验2-B+树索引实现(下)
4. Index_Iterator实现 这里就是需要实现迭代器的一些操作,比如begin.end.isend等等 下面是对于IndexIterator的构造函数 template <typena ...
- InnoDB的B+树索引使用
何时使用索引 并不是在所有的查询条件下出现的列都需要添加索引.对于什么时候添加B+树索引,我的经验是访问表中很少一部分行时,使用B+树索引才有意义.对于性别字段.地区字段.类型字段,它们可取值的范围很 ...
- 搞懂MySQL InnoDB B+树索引
一.InnoDB索引 InnoDB支持以下几种索引: B+树索引 全文索引 哈希索引 本文将着重介绍B+树索引.其他两个全文索引和哈希索引只是做简单介绍一笔带过. 哈希索引是自适应的,也就是说这个不能 ...
- MySQL InnoDB引擎B+树索引简单整理说明
本文出处:http://www.cnblogs.com/wy123/p/7211742.html (保留出处并非什么原创作品权利,本人拙作还远远达不到,仅仅是为了链接到原文,因为后续对可能存在的一些错 ...
- CMU数据库(15-445)实验2-b+树索引实现(上)
Lab2 在做实验2之前请确保实验1结果的正确性.不然你的实验2将无法正常进行 环境搭建地址如下 https://www.cnblogs.com/JayL-zxl/p/14307260.html 实验 ...
- CMU数据库(15-445)Lab3- QUERY EXECUTION
Lab3 - QUERY EXECUTION 实验三是添加对在数据库系统中执行查询的支持.您将实现负责获取查询计划节点并执行它们的executor.您将创建执行下列操作的executor Access ...
- CMU数据库(15-445)Lab0-环境搭建
0.写在前面 从这篇文章开始.开一个新坑,记录以下自己做cmu数据库实验的过程,同时会分析一下除了要求我们实现的代码之外的实验自带的一些代码.争取能够对实现一个数据库比较了解.也希望能写进简历.让自己 ...
- CMU数据库(15-445) Lab4-CONCURRENCY CONTROL
Lab4- CONCURRENCY CONTROL 拖了很久终于开始做实验4了.lab4有三个大任务1. Lock Manager.2. DEADLOCK DETECTION .3. CONCURRE ...
- B树索引最通俗易懂的介绍
先来一段有莫的对话: 前几天下班回到家后正在处理一个白天没解决的bug,厕所突然传来对象的声音: 对象:xx,你有<时间简史>吗? 我:我去!妹子,你这啥癖好啊,我有时间也不会去捡屎 ...
随机推荐
- angular8 大地老师学习笔记---第十课
import { Component,Input} from '@angular/core';@Component({ selector: 'app-lifecycle', templateUrl: ...
- 实验题目:python面向对象程序设计
1.定义并实现一个矩形类Rectangle,其私有实例成员为矩形的左下角与右上角两个点的坐标,能设置左下角和右上角两个点的位置,能根据左下角与右上角两个点的坐标计算矩形的长.宽.周长和面积,另外根据需 ...
- ASP.NET Core Web 支付功能接入 微信-扫码支付篇(转)
原文 https://www.cnblogs.com/essenroc/p/8630730.html // 随着版本更迭,新版本可能无法完全适用,请参考仓库内的示例. 这篇文章将介绍ASP.NET C ...
- 【升级版】如何使用阿里云云解析API实现动态域名解析,搭建私有服务器【含可执行文件和源码】
原文地址:http://www.yxxrui.cn/article/179.shtml 未经许可请勿转载,如有疑问,请联系作者:yxxrui@163.com 我遇到的问题:公司的网络没有固定的公网IP ...
- Kotlin 简单使用手册
在昨天和做android的前辈一番交谈后,觉得很惭愧,许多东西还只是知其然而不知其所以然,也深感自己的技术还太浅薄.以后要更加努力地学习,要着重学习原理.方法论,不能只停留在会用的阶段. 今天又要献丑 ...
- C# 9 新特性 —— 增强的模式匹配
C# 9 新特性 -- 增强的模式匹配 Intro C# 9 中进一步增强了模式匹配的用法,使得模式匹配更为强大,我们一起来了解一下吧 Sample C# 9 中增强了模式匹配的用法,增加了 and/ ...
- Kubernetes官方java客户端之二:序列化和反序列化问题
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- ElasticSearch--一、使用场景以及对应软件配置安装
废话不多说,直接来硬的!我在使用的时候使用的是mysql数据库. 一.ElasticSearch概念和使用场景 1.当我们需要搜索海量数据的时候,就可能会用到.以下使用的场景有哪些呢? 搜索海量数据 ...
- 面试官:Mysql 中主库跑太快,从库追不上怎么整?
写这篇文章是因为之前有一次删库操作,需要进行批量删除数据,当时没有控制好删除速度,导致产生了主从延迟,出现了一点小事故. 今天我们就来看看为什么会产生主从延迟以及主从延迟如何处理等相关问题. 坐好了, ...
- jupyter安装插件Nbextensions,实现代码提示功能(终极方法)
jupyter安装插件,实现代码提示功能 第一步 pip install jupyter_contrib_nbextensions -i https://mirrors.tuna.tsinghua.e ...