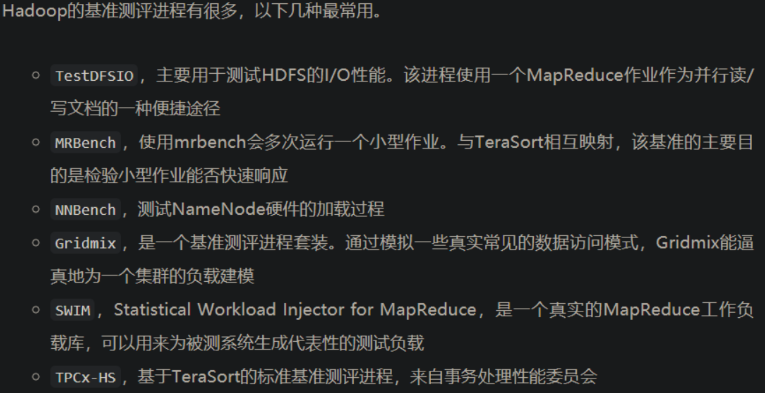
Hadoop理论基础
- namenode 50070
- datenode 50075
- secondarynamenode 50090
- yarn.resoucemanager 8088
- 历史服务器 19888
- MRAppMaster:负责整个程序的过程调度及状态协调
- MapTask:负责 map 阶段的整个数据处理流程
- ReduceTask:负责 reduce 阶段的整个数据处理流程
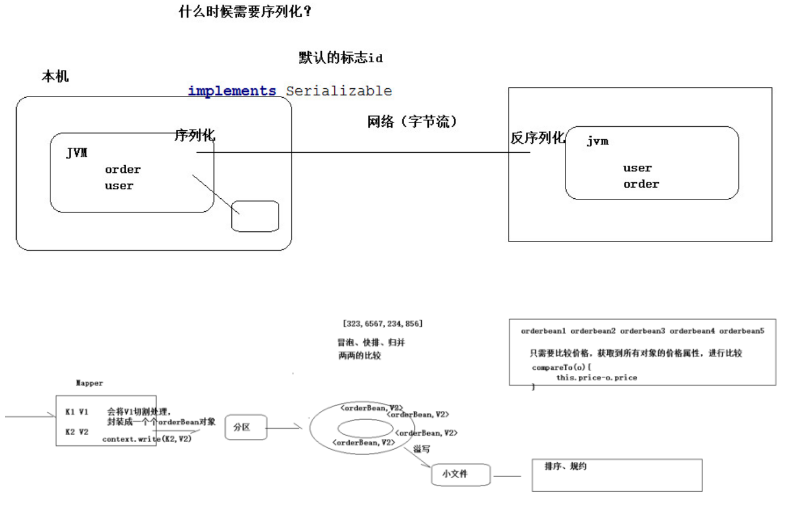
//反序列化的方法,反序列化时,
//从流中读取到的各个字段的顺序应该与序列化时
//写出去的顺序保持一致
@Override
public void readFields(DataInput in) throws IOException {
upflow = in.readLong();
dflow = in.readLong();
sumflow = in.readLong();
}
//序列化的方法
@Override
public void write(DataOutput out) throws IOException {
out.writeLong(upflow);
out.writeLong(dflow);
out.writeLong(sumflow);
}
@Override
public int compareTo(FlowBean o) {
//实现按照 sumflow 的大小倒序排序
return sumflow>o.getSumflow()?-1:1;
}
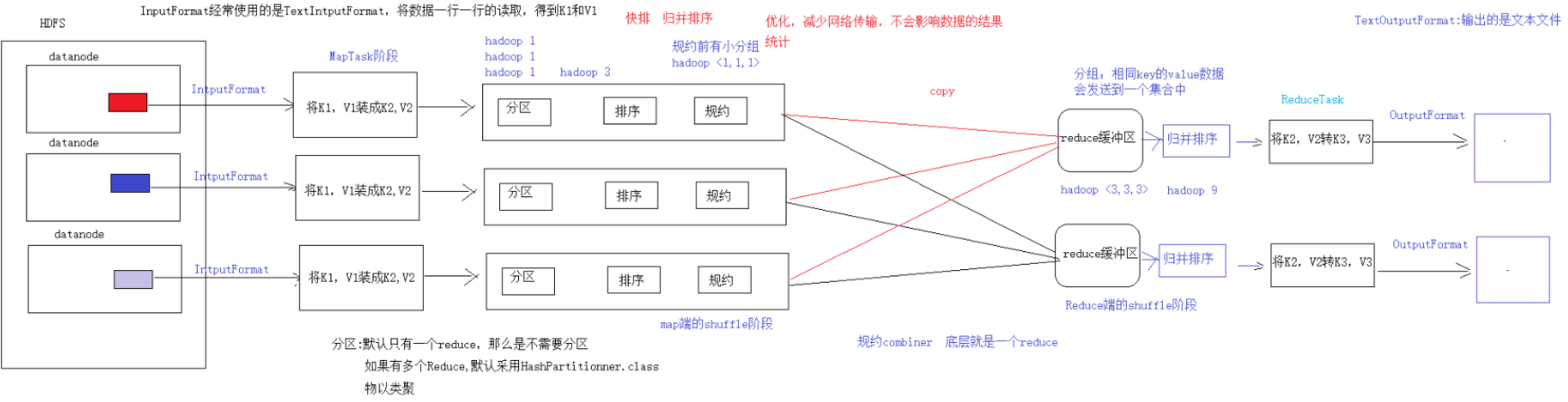
- combiner 是 MR 程序中 Mapper 和 Reducer 之外的一种组件
- combiner 组件的父类就是 Reducer
- combiner 和 reducer 的区别在于运行的位置:
- combiner 是在每一个 maptask 所在的节点运行
- reducer 是接收全局所有 Mapper 的输出结果;
- combiner 的意义就是对每一个 maptask 的输出进行局部汇总,以减小网络传输量
- 自定义一个 combiner 继承 Reducer,重写 reduce 方法
- 在 job 中设置: job.setCombinerClass(CustomCombiner.class)
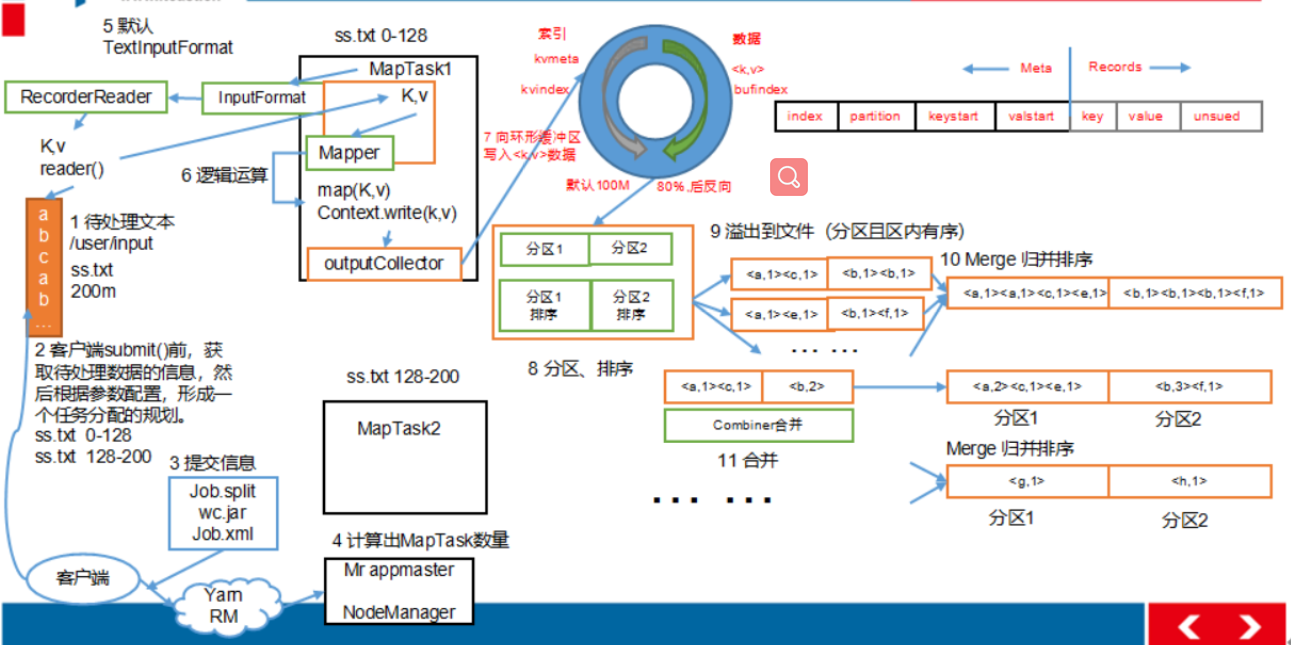
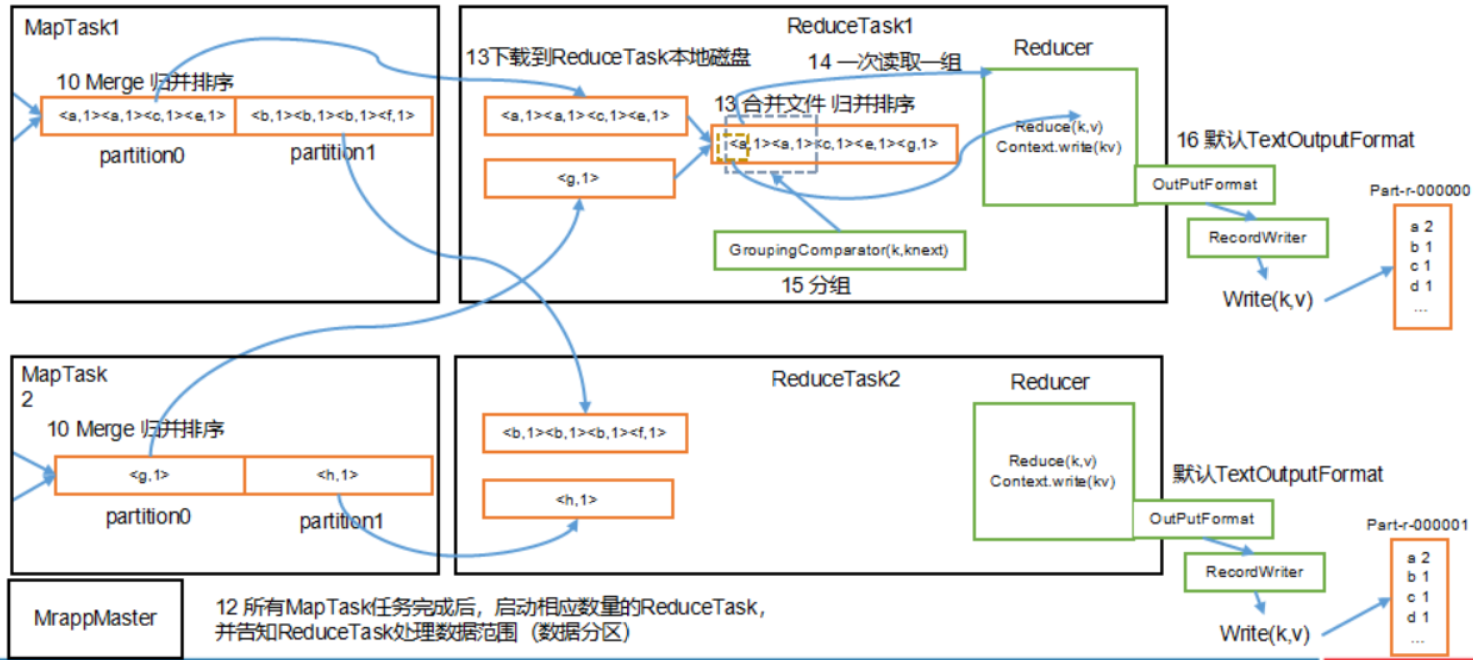

- 将map端结果输出到环形缓冲区, 默认为100M, 保存的是<key, value>和分区信息多个ReduceTask时才需要分区
- 当环形缓冲去到达80%时, 写入磁盘中, 在写入之前对数据进行快排, 如果配置了combiner, 还会对有相同分区号和key进行排序
- 将所有溢出的临时文件进行一次合并操作, 确保一个MapTask最终只生成一个文件
- Reduce复制一份数据, 默认保存在内存的缓冲区中, 到达阈值, 将数据写到磁盘
- Reduce复制数据同时, 开启两个线程对内存到本地的数据进行合并
- 进行合并数据同时, 进行排序, 因为Map端已进行局部排序, Reduce只需保证数据整体有效
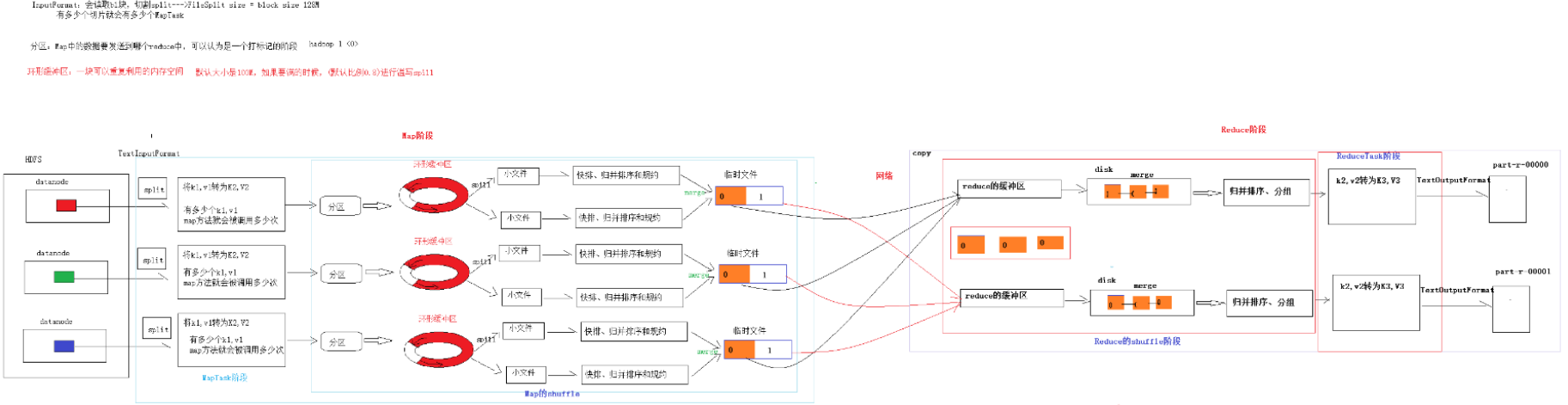
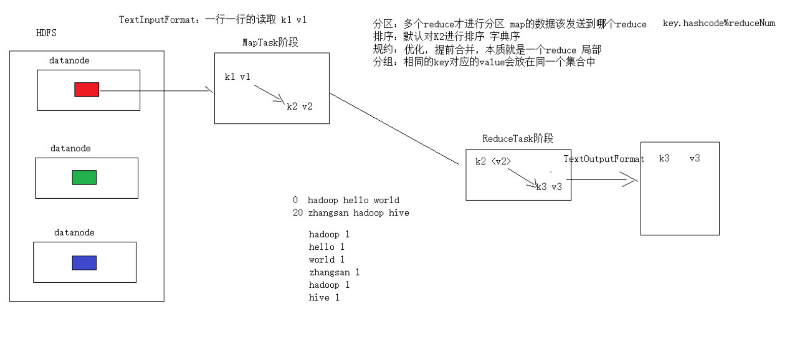
- 单纯按照文件内容切分
- 切片大小等于block块大小
- 不考虑数据集整体, 逐个针对文件切片
- 切片公式: max(0, min(Long_max, blockSize))
- 内存元数据:文件信息、块信息、datanode节点信息
- 文件元数据:只包含文件信息,其他信息是在datanode启动的时候进行上报
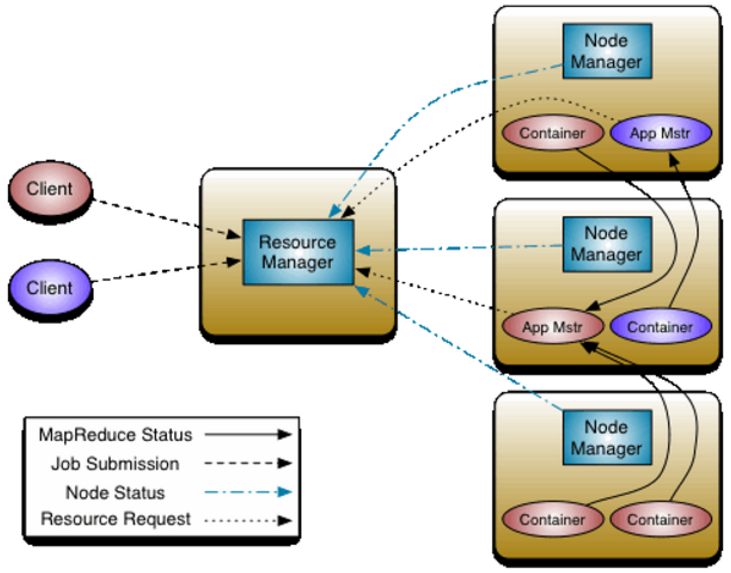
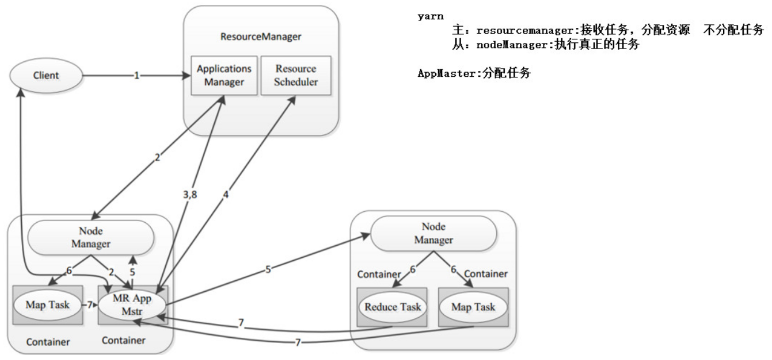
- 客户端向RM提交程序, 包括AppMaster的必须信息,例如 ApplicationMaster 程序、启动 ApplicationMaster 的命令、用户程序等。
- RM启动Container用来运行AppMaster
- 启动中的AppMaster向RM注册, 启动完成后与RM保持心跳
- AppMaster向RM申请相应数量的Container
- RM返回AppMaster申请的Container信息, 由AppMaster对其进行初始化
- AppMaster与NM进行通信, 要求NM启动Container, 两者保持心跳, 从而对NM运行的任务进行管理和监控
- AppMaster对运行中的Container进行监控, Container通过RPC协议对相应的NM汇报信息
- 客户端通过AppMaster获取运行状态进度等信息
- 结束后, AppMaster向RM进行注销, 并回收Container
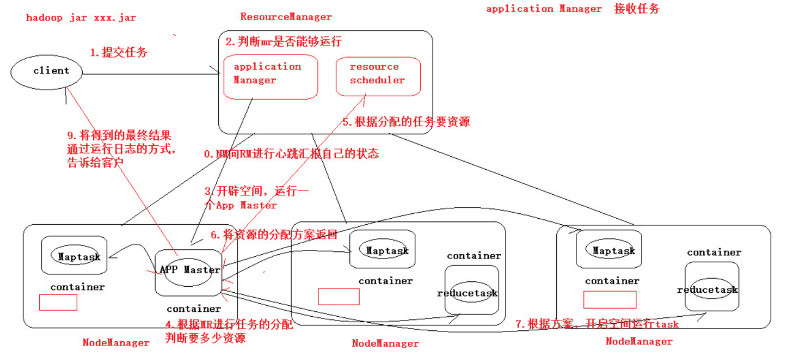
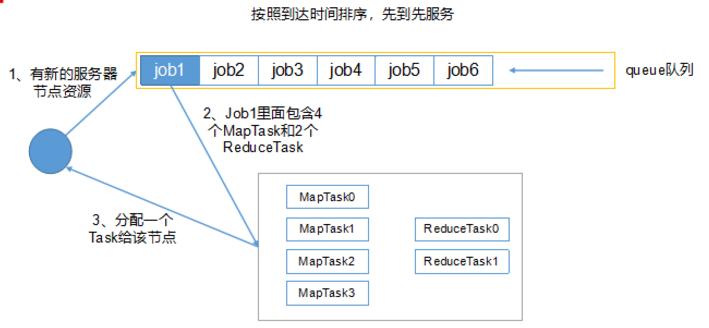
- 每个队列可配置资源
- 对同一用户提交的作业所占资源进行限定
- 首先, 计算每个队列中正在进行的任务与所分得资源的比值, 选出一个值最小的队列, 也就是最闲的
- 其次, 按照作业优先级和提交时间顺序, 同时考虑用户资源量限制和内存限制, 对队列中的任务排序
- 队列同时按照提交任务的顺序并行运行

- 每个队列的任务按照优先级分配资源, 优先级越高资源越多, 但是每个任务都可以分配到资源能保证公平
- 任务理想计算资源与实际计算资源的差值叫做缺额
- 同一队列中, 缺额越大, 任务优先级越高, 可多个作业同时运行


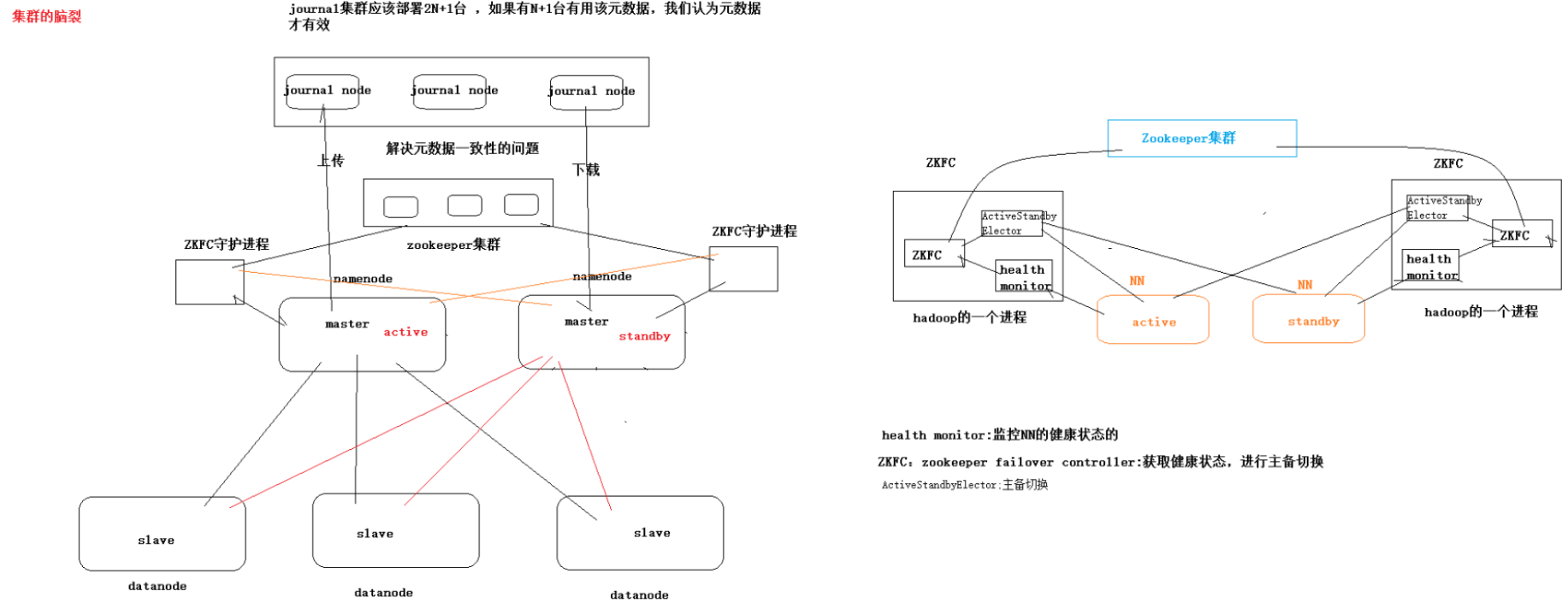
- 多个 NN 共用一个集群里的存储资源,每个 NN 都可以单独对外提供服务。
- 每个 NN 都会定义一个存储池,有单独的 id,每个 DN 都为所有存储池提供存储。
- DN 会按照存储池 id 向其对应的 NN 汇报块信息,同时,DN 会向所有 NN 汇报本地存储可用资源情况。
- 在hdfs-site.xml文件中配置多目录,最好提前配置好,否则更改目录需要重新启动集群
- NameNode有一个工作线程池,用来处理不同DataNode的并发心跳以及客户端并发的元数据操作。
- dfs.namenode.handler.count=20 * log2(Cluster Size),比如集群规模为10台时,此参数设置为60
- 编辑日志存储路径dfs.namenode.edits.dir设置与镜像文件存储路径dfs.namenode.name.dir尽量分开,达到最低写入延迟
- 服务器节点上YARN可使用的物理内存总量,默认是8192(MB),注意,如果你的节点内存资源不够8GB,则需要调减小这个值,而YARN不会智能的探测节点的物理内存总量。 yarn.nodemanager.resource.memory-mb
- 单个任务可申请的最多物理内存量,默认是8192(MB)。yarn.scheduler.maximum-allocation-mb
- 如果MR造成系统宕机。此时要控制Yarn同时运行的任务数,和每个任务申请的最大内存。调整参数:yarn.scheduler.maximum-allocation-mb(单个任务可申请的最多物理内存量,默认是8192MB)
- 如果写入文件过量造成NameNode宕机。那么调高Kafka的存储大小,控制从Kafka到HDFS的写入速度。高峰期的时候用Kafka进行缓存,高峰期过去数据同步会自动跟上。
Hadoop理论基础的更多相关文章
- 大数据-hdfs技术
hadoop 理论基础:GFS----HDFS:MapReduce---MapReduce:BigTable----HBase 项目网址:http://hadoop.apache.org/ 下载路径: ...
- hadoop入门(3)——hadoop2.0理论基础:安装部署方法
一.hadoop2.0安装部署流程 1.自动安装部署:Ambari.Minos(小米).Cloudera Manager(收费) 2.使用RPM包安装部署:Apache ...
- Hadoop生态圈学习-1(理论基础)
一.大数据技术产生的背景 1. 计算机和信息技术(尤其是移动互联网)的迅猛发展和普及,行业应用系统的规模迅速扩大(用户数量和应用场景,比如facebook.淘宝.微信.银联.12306等),行业应用所 ...
- Hadoop学习之路(一)理论基础和逻辑思维
三个题目 第一题 问题描述 统计出当前这个一行一个IP的文件中,到底哪个IP出现的次数最多 解决思路 //必须要能读取这个内容 BufferedReader br = new BuffedReader ...
- hadoop是什么
Hadoop一直是我想学习的技术,正巧最近项目组要做电子商城,我就开始研究Hadoop,虽然最后鉴定Hadoop不适用我们的项目,但是我会继续研究下去,技多不压身. <Hadoop基础教程> ...
- Hadoop基础学习框架
我们主要使用Hadoop的2个部分:分布式文件存储系统(HDFS)和MapReduce计算模型. 关于这2个部分,可以参考一下Google的论文:The Google File System 和 Ma ...
- 初识Hadoop入门介绍
初识hadoop入门介绍 Hadoop一直是我想学习的技术,正巧最近项目组要做电子商城,我就开始研究Hadoop,虽然最后鉴定Hadoop不适用我们的项目,但是我会继续研究下去,技多不压身. < ...
- [转]《Hadoop基础教程》之初识Hadoop
原文地址:http://blessht.iteye.com/blog/2095675 Hadoop一直是我想学习的技术,正巧最近项目组要做电子商城,我就开始研究Hadoop,虽然最后鉴定Hadoop不 ...
- hadoop初识
搞什么东西之前,第一步是要知道What(是什么),然后是Why(为什么),最后才是How(怎么做).但很多开发的朋友在做了多年项目以后,都习惯是先How,然后What,最后才是Why,这样只会让自己变 ...
随机推荐
- laravel5Eloquent模型与数据表的创建
下面是有关管理员模型与表的创建 生成模型时同时生成数据库迁移文件 在生成的迁移文件中添加字段 运行命令行生成数据表 命令进行混合运用 生成工厂文件,数据填充文件 工厂模型代码 数据填充文件代码 数据填 ...
- 故障:fork failed:Resource Temporarily Unavailable解决方案
故障:fork failed:Resource Temporarily Unavailable解决方案 AIX在一次crontab bkapp.txt导入N多定时任务时候,该用户无法执行任何命令,再s ...
- [Oracle/SQL]找出id为0的科目考试成绩及格的学生名单的四种等效SQL语句
本文是受网文 <一次非常有意思的SQL优化经历:从30248.271s到0.001s>启发而产生的. 网文没讲创建表的数据过程,我帮他给出. 创建科目表及数据: CREATE TABLE ...
- Fabric1.4 kafka共识的多orderer集群
https://www.cnblogs.com/zhangmingcheng/p/10556469.html#FeedBack https://yq.aliyun.com/articles/63746 ...
- 通俗理解线性回归(Linear Regression)
线性回归, 最简单的机器学习算法, 当你看完这篇文章, 你就会发现, 线性回归是多么的简单. 首先, 什么是线性回归. 简单的说, 就是在坐标系中有很多点, 线性回归的目的就是找到一条线使得这些点都在 ...
- 浅谈在win server2012 R2操作系统上安装mysql odbc数据源遇到的问题 -九五小庞
一,服务器系统 Windows Server 2012 R2 二,安装odbc数据源出现的问题 三,步骤二 中的问题,是因为缺少微软常用运行库.需要安装一下运行库 四,安装odbc数据源 安装MySQ ...
- js动画之轮播图
一. 使用Css3动画实现 <!DOCTYPE html> <html> <head> <meta charset="UTF-8"> ...
- Vue iview可收缩多级菜单的实现
递归组件实战 views/layout.vue <template> <div class="layout-wrapper"> <Layout cla ...
- nacos快速安装
一 什么是 Nacos 服务注册中心和配置中心. 二 使用 下载和启动 使用有两种方式 1.自己下载源码编译 2.下载编译好的压缩包 我比较懒选择了第二种方式. 最新稳定版本 下载地址:https:/ ...
- 使用vue-cli(vue脚手架)快速搭建项目
vue-cli 是一个官方发布 vue.js 项目脚手架,使用 vue-cli 可以快速创建 vue 项目.这篇文章将会从实操的角度,介绍整个搭建的过程. 1. 避坑前言 其实这次使用vue-cli的 ...