Hive 窗口函数sum() over()求当前行和前面n条数据的和
前几天遇到一个这样的需求:销售总占比加起来超过75%的top分类。具体需求是这样的:商品一级分类标签下面有许多商品标签,例如运动户外一级标签,下面可能存在361°,CBA,Nike,Adidas...等这些商品标签。我们需要统计在一级标签下面占总销售比超过75%的商品标签有哪些,从而让我们了解一级品牌标签下面哪些商品比较收用户喜欢。有以下样例数据(amount_precnt为这类商品在一级标签当中销售占比)。

按照我们的业务需求我们要得到男装->(优衣库,七匹狼) 箱包->(coach) 运动户外->(361°,Nike,CBA)这样的结果就是符合我们的要求。amount_precnt占比在75%的top分类数据。
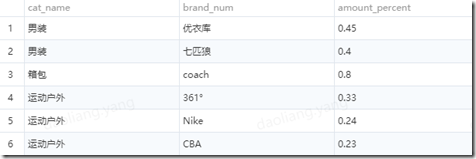
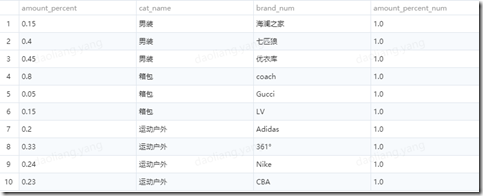
拿到这样的需求以后,思路如下。按照cat_name分组求和。然后在利用lag函数取前一条求和值作为另外一个字段。最后过滤条件为求和值小于0.5或者当前求和值大于0.5并且前一个求和值小于0.5的数据。得到思路以后主要是卡在了怎么按照cat_name依次求和。就是如何将第一条数据的amount_precnt + 第二条数据的amount_precnt。然后前面两条数据的和在加第三条数据的amount_precnt值。依次这样类推….后面翻看hive 窗口函数的官网得到资料。在sum() over 里面加上 rows between unbounded preceding and current 可以求当前行和前面n条数据的和。我们先看一下sum() over()得到的效果。amount_percent_num的值都是1.就是求和的值。
select amount_percent, cat_name,brand_num,
sum(amount_percent) over(partition by cat_name ) as amount_percent_num
from
(SELECT * FROM hive_temp_bad.dlyang_1234 order by cat_name) t
然后我们加上rows between unbounded preceding and current
select amount_percent, cat_name,brand_num,
sum(amount_percent) over(partition by cat_name ) as amount_percent_num
from
(SELECT * FROM hive_temp_bad.dlyang_1234 order by cat_name) t
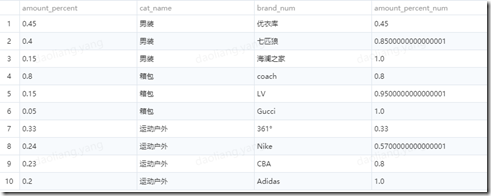
得到了我们想要的结果了。最后我们贴上完整的sql代码实现上面功能。
1 select cat_name,brand_num,amount_percent from
2 (select *,lag(amount_percent_num,1,0) over(partition by cat_name order by amount_percent_num) as lag1 from
3 (select amount_percent, cat_name,brand_num,
4 sum(amount_percent) over(partition by cat_name order by amount_percent desc rows between unbounded preceding and current row) as amount_percent_num
5 from
6 (SELECT * FROM hive_temp_bad.dlyang_1234 order by cat_name) t ) t2 ) t3 where lag1 < 0.75 or (amount_percent_num > 0.75 and lag1 < 0.75) ORDER BY
7 cat_name,amount_percent desc;

不得不说sql天花板可能真的是窗口函数了。看来以后得要多多学习了。
Hive 窗口函数sum() over()求当前行和前面n条数据的和的更多相关文章
- Hive窗口函数保姆级教程
在SQL中有一类函数叫做聚合函数,例如sum().avg().max()等等,这类函数可以将多行数据按照规则聚集为一行,一般来讲聚集后的行数是要少于聚集前的行数的.但是有时我们想要既显示聚集前的数据, ...
- hive窗口函数/分析函数详细剖析
hive窗口函数/分析函数 在sql中有一类函数叫做聚合函数,例如sum().avg().max()等等,这类函数可以将多行数据按照规则聚集为一行,一般来讲聚集后的行数是要少于聚集前的行数的.但是有时 ...
- Hive窗口函数最全案例详解
语法: 分析函数 over(partition by 列名 order by 列名 rows between 开始位置 and 结束位置) 常用分析函数: 聚合类 avg().sum().max(). ...
- Hive窗口函数案例详解
语法: 分析函数 over(partition by 列名 order by 列名 rows between 开始位置 and 结束位置) 常用分析函数: 聚合类 avg().sum().max(). ...
- Sqoop是一款开源的工具,主要用于在HADOOP(Hive)与传统的数据库(mysql、oracle...)间进行数据的传递
http://niuzhenxin.iteye.com/blog/1706203 Sqoop是一款开源的工具,主要用于在HADOOP(Hive)与传统的数据库(mysql.postgresql.. ...
- Hive 组内计无重复数,追加每条记录后面
今天无意中碰到一个很简单的计算逻辑,但是用hive想了一大会才实现. 示例表数据: 需求逻辑: 给每条记录追加一个字段,用于统计按照p1和p2字段分组后,每个组中的num的数目(去重后的count). ...
- nvl(sum(字段),0) 的时候,能展示数据0,但是group by 下某个伪列的时候,查不到数据(转载)
今天碰到一个比较有疑惑的问题,就是在统计和的时候,我们往往有时候查不到数据,都会再加个 nvl(sum(字段),0) 来显示这个字段,但是如果我们再加个group by ,就算有加入这个 nvl(nu ...
- JS求多个数组的重复数据
今天朋友问了我这个问题:JS求多个数组的重复数据 注: 1.更准确的说是只要多个数组中有两个以上的重复数据,那么这个数据就是我需要的 2.单个数组内的数据不存在重复值(当然如果有的话,你可以去重) 3 ...
- Hive 窗口函数、分析函数
1 分析函数:用于等级.百分点.n分片等 Ntile 是Hive很强大的一个分析函数. 可以看成是:它把有序的数据集合 平均分配 到 指定的数量(num)个桶中, 将桶号分配给每一行.如果不能平均分配 ...
随机推荐
- CocosCreator游戏开发(四)实现摇杆控制角色功能
时隔3年,我又开始继续写这个系列的帖子了,也不知道是会写完全系列,还是再次夭折. 废话不多.直接开始主题了 主要实现的功能点包含这些内容:通过摇杆控制角色进行八方位移动,并按照各方位播放对应移动动画 ...
- 计算机网络-应用层(2)FTP协议
文件传输协议(FTP,File Transfer Protocol)是Internet上使用最广泛的文件传送协议.FTP提供交互式的访问,允许客户指明文件的类型与格式,并允许文件具有存取权限.它屏蔽了 ...
- Open MPI 4.0 编译安装
电脑上目前使用的mpi环境是2.1.1版本的openmpi,是我之前直接使用系统的包管理工具安装的.但是系统包版本一般都比较老旧,现在openmpi最新版已经出到了4.0,即将出4.1了,所以我打算升 ...
- HTML5实战与剖析之媒体元素
随着HTML5的到来,flash在手机端全部不能得到支持,这就使一项以flash制作的音乐播放和视频播放只能用HTML5中的媒体标签video标签和audio标签来制作了.很恰巧的是,移动端对HTML ...
- 区块链入门到实战(12)之区块链 – 默克尔树(Merkle Tree)
目的:解决由于区块链过长,导致节点硬盘存不下的问题. 方法:只需保留交易的哈希值. 区块链作为分布式账本,原则上网络中的每个节点都应包含整个区块链中全部区块,随着区块链越来越长,节点的硬盘有可能放不下 ...
- 作为一个Java程序员连简单的分页功能都会写,你好意思嘛!
今天想说的就是能够在我们操作数据库的时候更简单的更高效的实现,现成的CRUD接口直接调用,方便快捷,不用再写复杂的sql,带吗简单易懂,话不多说上方法 1.Utils.java工具类中的方法 1 /* ...
- element UI dialog 固定高度 且关闭时清空数据
解决方法:在dialog里写一个div ,div的大小设置为相对视窗的大小就行 <el-dialog title="xxx" :visible.sync="dial ...
- 深度优先搜索(DFS)解题总结
定义 深度优先搜索算法(Depth-First-Search),是搜索算法的一种.它沿着树的深度遍历树的节点,尽可能深的搜索树的分支. 例如下图,其深度优先遍历顺序为 1->2->4-&g ...
- web自动化多次打开浏览器嫌烦?打开一次浏览器,pytest有个招
最近系统前端组件做了更新,我就把之前做的web自动化的代码做了一些修改,顺便优化了下用例,只保留少量的测试用例了,大头还是在接口自动化上.然后发现关于pytest的还有一个点应该比较常用,这里再介绍一 ...
- 搭建lnmp环境,nginx的配置文件/etc/nginx/nginx.conf
#user nobody; worker_processes 1; #error_log logs/error.log; #error_log logs/error.log notice; #erro ...