Spark Standalone模式 高可用部署
本文使用Spark的版本为:spark-2.4.0-bin-hadoop2.7.tgz。
spark的集群采用3台机器进行搭建,机器分别是server01,server02,server03。
其中:server01,server02设置为Master,server01,server02,server03为Worker。
1.Spark
下载地址:
http://spark.apache.org/downloads.html
选择对应的版本进行下载就好,我这里下载的版本是:spark-2.4.0-bin-hadoop2.7.tgz。
2.上传及解压
2.1 下载到本地后,上传到Linux的虚拟机上
scp spark-2.4.0-bin-hadoop2.7.tgz hadoop@server01:/hadoop
2.2 解压
tar -zxvf spark-2.4.0-bin-hadoop2.7.tgz
2.3 重命名
mv spark-2.4.0-bin-hadoop2.7 spark
3.配置环境
进入spark/conf目录
3.1 复制配置文件
cp slaves.template slaves cp spark-env.sh.template spark-env.sh
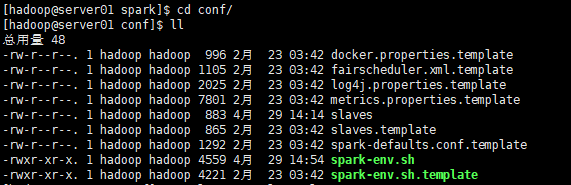
3.2 修改slaves配置文件
spark集群的worker conf配置 slaves
server01
server02
server03
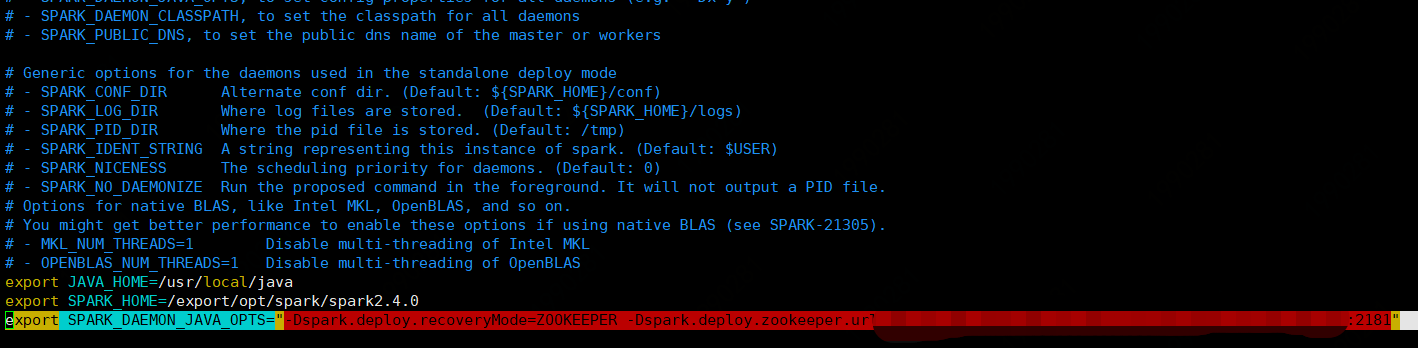
3.3 修改spark-env.sh配置文件
# java环境变量 export JAVA_HOME=/usr/local/java #spark home export SPARK_HOME=/export/opt/spark/spark2.4.0 # spark集群master进程主机host export SPARK_MASTER_HOST=server01 # 配置zk 此处可以独立配置zk list,逗号分隔 export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=xxx.xxx.xxx.xxx:2181, xxx.xxx.xxx.xxx:2181……"
如下图
3.4 下发到server02和server03机器上
scp -r /hadoop/spark hadoop@server02:/hadoop scp -r /hadoop/spark hadoop@server03:/hadoop
3.5 修改server02机器上的spark-env.sh的SPARK_MASTER_HOST参数信息
# 增加备用master主机,改为server02,将自己设置为master(备用) export SPARK_MASTER_HOST=server02

3.6 配置环境变量
给server01,server02,server03机器上配置spark的环境变量
export SPARK_HOME=/export/opt/spark/spark2.4.0
export PATH=$PATH:${SPARK_HOME}/bin:${SPARK_HOME}/sbin
#使配置环境生效
source /etc/profile
4. 启动Spark集群
在server01机器上,进入spark目录
4.1 分别启动master和slaves进程
# 启动master进程 sbin/start-master.sh # 启动3个worker进程,也可以每个机器独立启动需要输入两个master地址 sbin/start-slaves.sh
jps查看进程1有既有master又有Worker,2,3只有Worker

4.2 直接使用start-all.sh启动
sbin/start-all.sh

4.3 手动启动server02机器上的master进程
进入spark目录
sbin/start-master.sh
我们可以使用stop-all.sh杀死spark的进程
sbin/stop-all.sh
web页面展示
在浏览器中输入
server01:8080
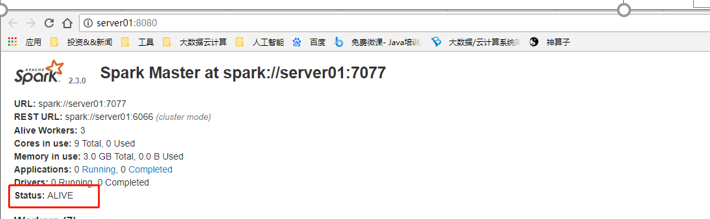
Status:ALIVE 说明master为主Master
server02:8080

总结
部署完成后可以尝试kill掉1的master,然后需要等几分钟后会重启备用master,此时备用切换为主。
另外如果application被杀掉或者jvm出现问题,还可以通过增加参数 --supervise(需要安装,pip install supervise)可以重新启动application。
Spark Standalone模式 高可用部署的更多相关文章
- Redis哨兵模式高可用部署和配置
一.Redis 安装配置 1.下载redis安装包 wget http://download.redis.io/releases/redis-4.0.9.tar.gz 2.解压安装包 tar -zxv ...
- Spark入门:第2节 Spark集群安装:1 - 3;第3节 Spark HA高可用部署:1 - 2
三. Spark集群安装 3.1 下载spark安装包 下载地址spark官网:http://spark.apache.org/downloads.html 这里我们使用 spark-2.1.3-bi ...
- 【原】Spark Standalone模式
Spark Standalone模式 安装Spark Standalone集群 手动启动集群 集群创建脚本 提交应用到集群 创建Spark应用 资源调度及分配 监控与日志 与Hadoop共存 配置网络 ...
- Spark Standalone模式HA环境搭建
Spark Standalone模式常见的HA部署方式有两种:基于文件系统的HA和基于ZK的HA 本篇只介绍基于ZK的HA环境搭建: $SPARK_HOME/conf/spark-env.sh 添加S ...
- eql高可用部署方案
运行环境 服务器两台(后面的所有配置案例都是以10.96.0.64和10.96.0.66为例) 操作系统CentOS release 6.2 必须要有共同的局域网网段 两台服务器都要安装keepali ...
- Spark standalone模式的安装(spark-1.6.1-bin-hadoop2.6.tgz)(master、slave1和slave2)
前期博客 Spark运行模式概述 Spark standalone简介与运行wordcount(master.slave1和slave2) 开篇要明白 (1)spark-env.sh 是环境变量配 ...
- Redis高可用部署及监控
Redis高可用部署及监控 目录 一.Redis Sentinel简介 二.硬件需求 三.拓扑结构 .单M-S结构 .双M-S结构 .优劣对比 四.配置部 ...
- 006.SQLServer AlwaysOn可用性组高可用部署
一 数据库镜像部署准备 1.1 数据库镜像支持 有关对 SQL Server 2012 中的数据库镜像的支持的信息,请参考:https://docs.microsoft.com/zh-cn/previ ...
- kubernetes 1.15.1 高可用部署 -- 从零开始
这是一本书!!! 一本写我在容器生态圈的所学!!! 重点先知: 1. centos 7.6安装优化 2. k8s 1.15.1 高可用部署 3. 网络插件calico 4. dashboard 插件 ...
随机推荐
- 使用响应扩展的响应面(Rx)
下载demo - 196 KB 下载source - 98 KB 表的内容 系统要求反应面一个简单的计时器从事件中收集数据序列使用更复杂的查询订阅您希望完成的面最终考虑历史 介绍 "Rx&q ...
- mysql任意文件读取漏洞复现
前言 第一次得知该漏洞后找了一些文章去看. 一开始不明白这个漏洞是怎么来的,只知道通过在服务端运行poc脚本就可以读取客户端的任意文件,直接找到网上准备好的靶机进行测试,发现可行,然后就拿别人的poc ...
- docker 升级后或者重装后,启动容器提示:Error response from daemon: Unknown runtime specified docker-runc
之前安装的版本是docker 1.3,并运行了容器jenkins 现在把docker升级版本为docker-ce 19.03 再使用docker ps发现之前的jenkins容器已经退出了 启动容器: ...
- day16 Pyhton学习
1.range(起始位置) range(终止位置) range(起始,终止位置) range(起始,终止,步长) 2.next(迭代器) 是内置函数 __next__是迭代器的方法 g.__next_ ...
- golang 爬取百度贴吧绝地求生页面
package main import ( "github.com/antchfx/htmlquery" "io" "net/http" & ...
- phpexcel导出数据 出现Formula Error的解决方案
phpexcel导出数据报错 Uncaught exception 'Exception' with message 'Sheet1!A1364 -> Formula Error: Unexpe ...
- APP打开(一)—以亲身经历谈APP注册登录
如果不是自己接手过这样的产品,我可能也很难相信,会有公司能够做出十四个注册页面的APP,将选站点.输账号.输密码.用户协议.用户权限等全部拆解成一个一个单独的页面来做,用户在注册的时候仿佛在攀登一座云 ...
- 19. [链表][双指针]删除链表的倒数第N个节点
19. 删除链表的倒数第N个节点 方法一:哨兵节点+快慢指针 在本题中,快慢指针的用法为:让快指针先走几步,步数由 \(n\) 决定. 使用哨兵节点的理由是为了避免删除节点为头结点引发的空指针异常. ...
- # ThreeJS学习7_裁剪平面(clipping)
ThreeJS学习7_裁剪平面(clipping) 目录 ThreeJS学习7_裁剪平面(clipping) 1. 裁剪平面简介 2. 全局裁剪和局部裁剪 3. 被多个裁剪平面裁剪后 4. 被多个裁剪 ...
- CyclicBarrier(循环栅栏)
CyclicBarrier public class CyclicBarrierDemo { public static void main(String[] args) { CyclicBarrie ...