行业动态 | Apache Pulsar 对现代数据堆栈至关重要的四个原因
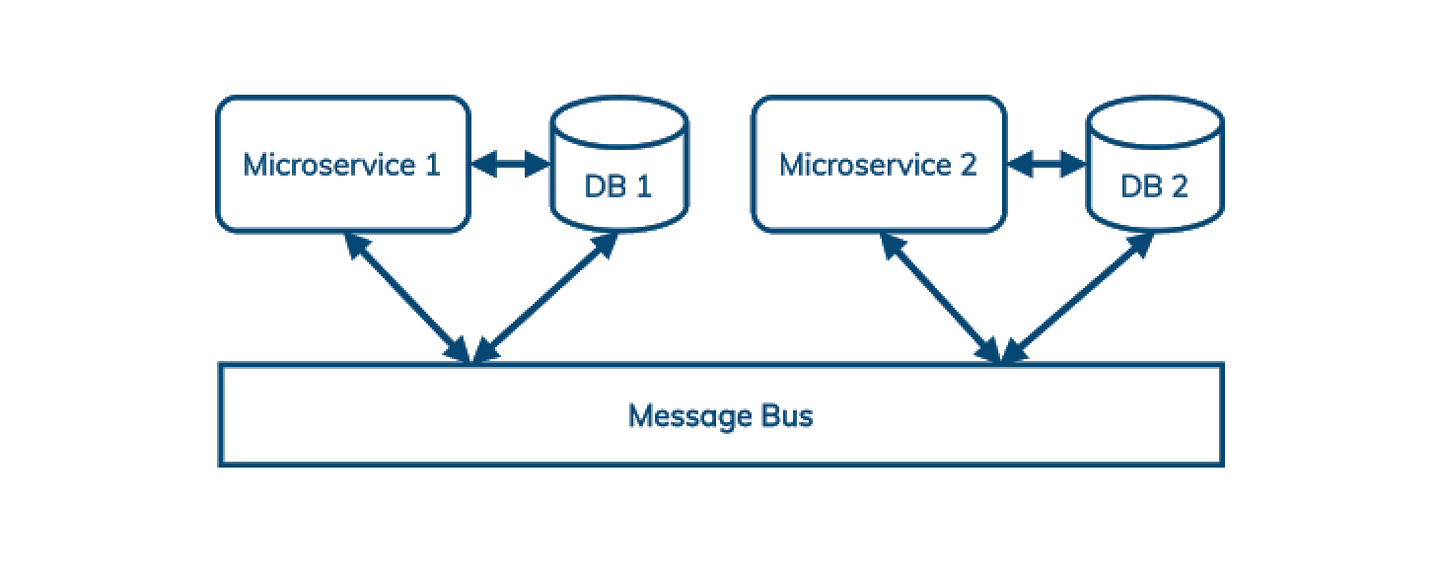
- 以开源为基础
- 非常适合混合云和多云部署
- 云原生,按消费计价
- 跨地域复制
- 扩展
- 多租户
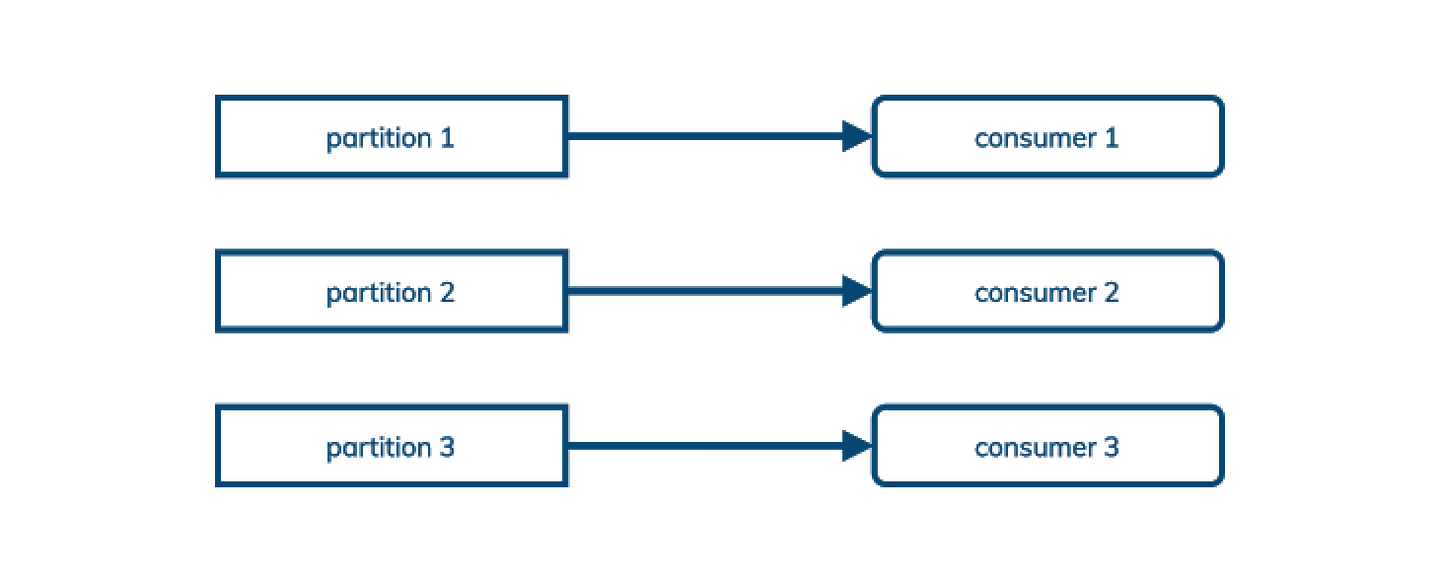
- 队列
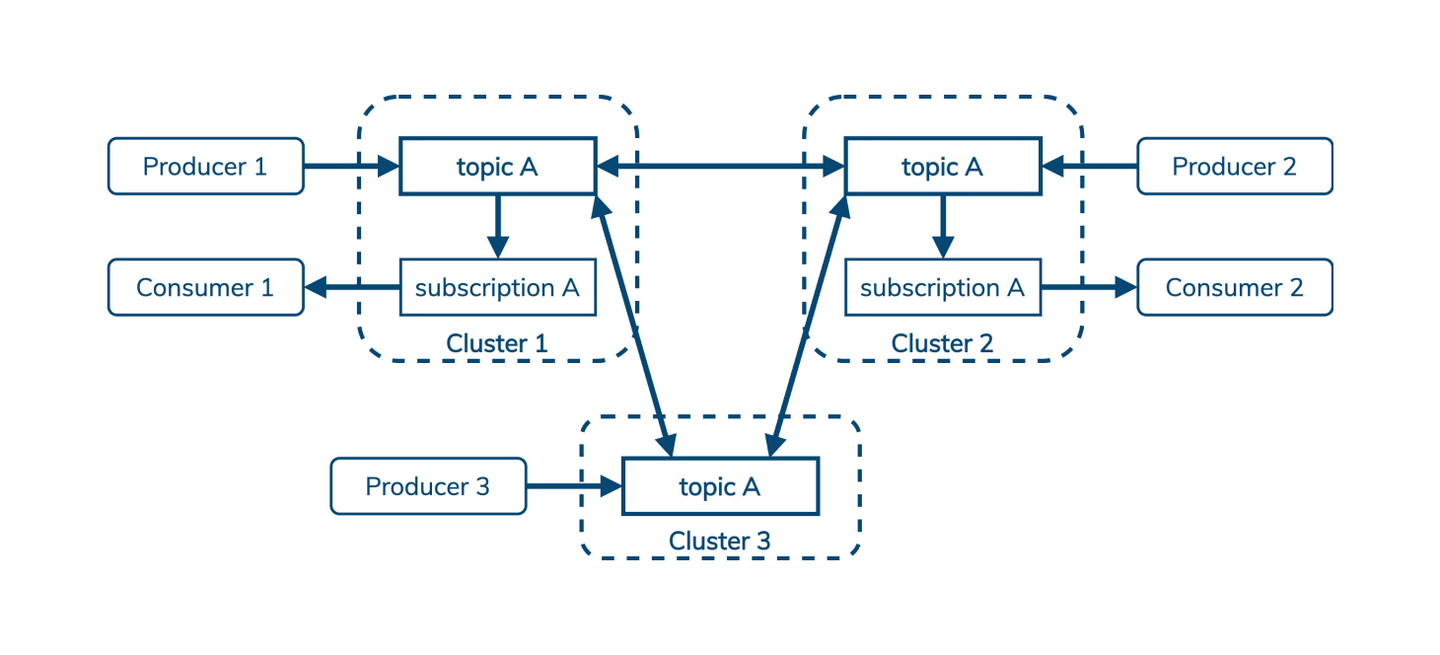
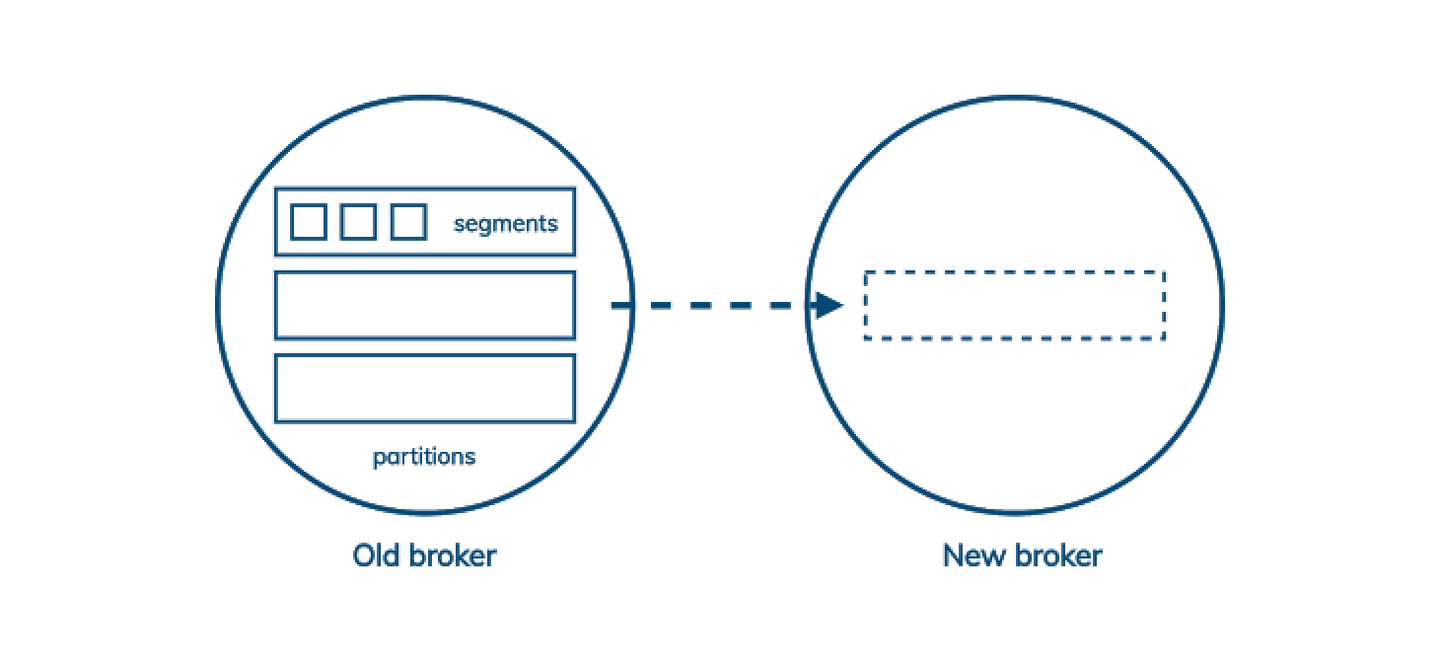
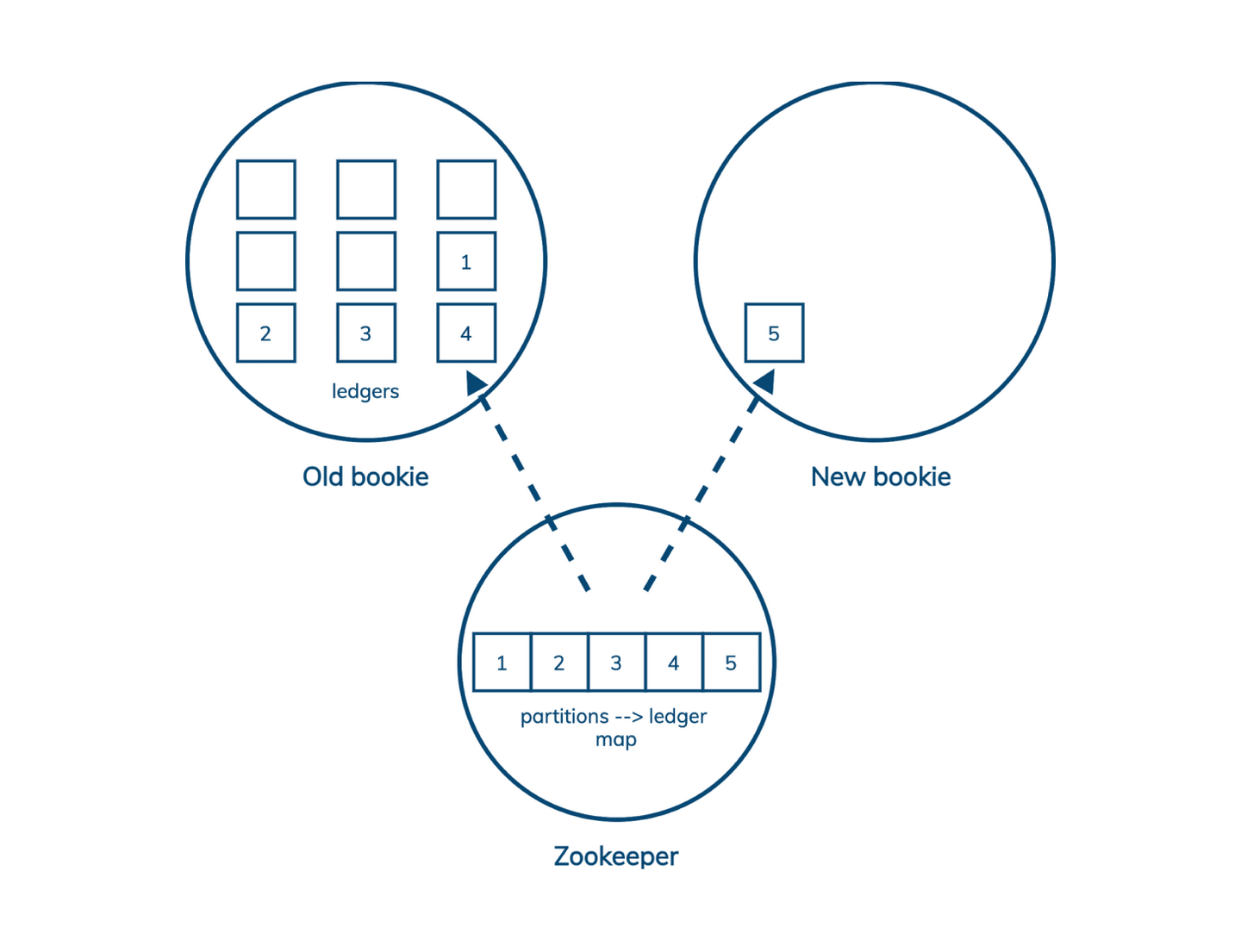


行业动态 | Apache Pulsar 对现代数据堆栈至关重要的四个原因的更多相关文章
- Apache Pulsar 在 BIGO 的性能调优实战(上)
背景 在人工智能技术的支持下,BIGO 基于视频的产品和服务受到广泛欢迎,在 150 多个国家/地区拥有用户,其中包括 Bigo Live(直播)和 Likee(短视频).Bigo Live 在 15 ...
- Apache Pulsar简介
Apache Pulsar What is Pulsar "Pulsar is a distributed pub-sub messaging platform with a very fl ...
- Apache Pulsar——企业级消息订阅系统介绍
Apache Pulsar是一款由雅虎开发的类似于Kafka的企业级消息订阅系统,在2016将其开源,由Apach基金会孵化,现在已经成长为Apache基金会的顶级项目.Pulsar在雅虎内部已经运行 ...
- 个推基于 Apache Pulsar 的优先级队列方案
作者:个推平台研发工程师 祥子 一.业务背景在个推的推送场景中,消息队列在整个系统中占有非常重要的位置.当 APP 有推送需求的时候, 会向个推发送一条推送命令,接到推送需求后,我们会把APP要求推送 ...
- [Apache Pulsar] 企业级分布式消息系统-Pulsar快速上手
Pulsar快速上手 前言 如果你还不了解Pulsar消息系统,可以先看上一篇文章 企业级分布式消息系统-Pulsar入门基础 Pulsar客户端支持多个语言,包括Java,Go,Pytho和C++, ...
- 分布式消息队列Apache Pulsar
Pulsar简介 Apache Pulsar是一个企业级的分布式消息系统,最初由Yahoo开发并在2016年开源,目前正在Apache基金会下孵化.Plusar已经在Yahoo的生产环境使用了三年多, ...
- Apache Pulsar 2.6.1 版本正式发布:2.6.0 功能增强版,新增 OAuth2 支持
在 Apache Pulsar 2.6.0 版本发布后的 2 个月,2020 年 8 月 21 日,Apache Pulsar 2.6.1 版本正式发布! Apache Pulsar 2.6.1 修复 ...
- Apache Pulsar 社区周报:08-15 ~ 08-21
关于 Apache Pulsar Apache Pulsar 是 Apache 软件基金会顶级项目,是下一代云原生分布式消息流平台,集消息.存储.轻量化函数式计算为一体,采用计算与存储分离架构设计,支 ...
- Apache Pulsar 社区周报:08-08 ~ 08-14
关于 Apache Pulsar Apache Pulsar 是 Apache 软件基金会顶级项目,是下一代云原生分布式消息流平台,集消息.存储.轻量化函数式计算为一体,采用计算与存储分离架构设计,支 ...
随机推荐
- vue项目中基于D3.js实现桑基图功能
前端实现数据可视化的方案有很多种,以前都是使用百度的echarts,使用起来很方便,直接按照特定的数据格式输入,就能实现相应的效果,虽然使用方便,但是缺点就是无法自定义一些事件操作,可自由发挥的功能很 ...
- Spring MVC参数处理
使用Servlet API作为参数 HttpServletRequest HttpServletResponse HttpSession 使用流作为参数 总结 Spring MVC通过分析处理处理方法 ...
- 提高效率的Linux命令
提高效率的Linux命令 一.fc 二.disown 三.Ctrl + x +e 四.!! 两个感叹号 五.一次创建多个目录或文件 六.tee 七.删除从开头到光标处的命令文本 八.删除从光标到结尾处 ...
- io流读写操作
/** * * DOC 将F盘下的test.jpg文件,读取后,再存到E盘下面. * * @param args * @throws Exception */ public static void m ...
- 删除无用docker镜像
docker images | grep none | grep -v grep | awk '{print $3}' | xargs docker rmi -f
- (13)Linux文件系统的优缺点
通过文件系统的方式来组织磁盘存储和数据管理.有以下几个方面的好处. 数据的读取.管理操作变得简单 文件系统给用户提供了一个简单的操作界面,用户可以通过对文件系统的简单操作,实现对磁盘的管理.虽然 Li ...
- Shiro权限项目
目录 环境配置 spring容器 springmvc freemarker mybatis shiro 工具类 TokenManager.java Result.java 功能实现 登录 注册 个人中 ...
- BZOJ 3675: 序列分割 (斜率优化dp)
Description 小H最近迷上了一个分隔序列的游戏.在这个游戏里,小H需要将一个长度为n的非负整数序列分割成k+1个非空的子序列.为了得到k+1个子序列,小H需要重复k次以下的步骤: 1.小H首 ...
- trie浅谈
关于trie 其实字典树和以上两种算法有很大不同,但是hash由于其优秀的应用,导致有些字符串查找用hash也是可行的. 字典树中支持添加,查找,区间查询(可持久化字典树),而且在异或操作上有 ...
- 【python接口自动化】- PyMySQL数据连接
什么是 PyMySQL? PyMySQL是在Python3.x版本中用于连接MySQL服务器的一个库,Python2中则使用mysqldb.它是一个遵循 Python数据库APIv2.0规范, ...