必须掌握的分布式文件存储系统—HDFS
HDFS(Hadoop Distributed File System)分布式文件存储系统,主要为各类分布式计算框架如Spark、MapReduce等提供海量数据存储服务,同时HBase、Hive底层存储也依赖于HDFS。HDFS提供一个统一的抽象目录树,客户端可通过路径来访问文件,如hdfs://namenode:port/dir-a/a.data。HDFS集群分为两大角色:Namenode、Datanode(非HA模式会存在Secondary Namenode)
Namenode
Namenode是HDFS集群主节点,负责管理整个文件系统的元数据,所有的读写请求都要经过Namenode。
元数据管理
Namenode对元数据的管理采用了三种形式:
1) 内存元数据:基于内存存储元数据,元数据比较完整
2) fsimage文件:磁盘元数据镜像文件,在NameNode工作目录中,它不包含block所在的Datanode 信息
3) edits文件:数据操作日志文件,用于衔接内存元数据和fsimage之间的操作日志,可通过日志运算出元数据
fsimage + edits = 内存元数据
注意:当客户端对hdfs中的文件进行新增或修改时,操作记录首先被记入edit日志文件,当客户端操作成功后,相应的元数据会更新到内存元数据中
|
可以通过hdfs的一个工具来查看edits中的信息 bin/hdfs oev -i edits -o edits.xml 查看fsimage bin/hdfs oiv -i fsimage_0000000000000000087 -p XML -o fsimage.xml |
元数据的checkpoint(非HA模式)
Secondary Namenode每隔一段时间会检查Namenode上的fsimage和edits文件是否需要合并,如触发设置的条件就开始下载最新的fsimage和所有的edits文件到本地,并加载到内存中进行合并,然后将合并之后获得的新的fsimage上传到Namenode。checkpoint操作的触发条件主要配置参数:
|
dfs.namenode.checkpoint.check.period=60 #检查触发条件是否满足的频率,单位秒 dfs.namenode.checkpoint.dir=file://${hadoop.tmp.dir}/dfs/namesecondary dfs.namenode.checkpoint.edits.dir=${dfs.namenode.checkpoint.dir} #以上两个参数做checkpoint操作时,secondary namenode的本地工作目录,主要处理fsimage和edits文件的 dfs.namenode.checkpoint.max-retries=3 #最大重试次数 dfs.namenode.checkpoint.period=3600 #两次checkpoint之间的时间间隔3600秒 dfs.namenode.checkpoint.txns=1000000 #两次checkpoint之间最大的操作记录 |
checkpoint作用
1. 加快Namenode启动Namenode启动时,会合并磁盘上的fsimage文件和edits文件,得到完整的元数据信息,但如果fsimage和edits文件非常大,这个合并过程就会非常慢,导致HDFS长时间处于安全模式中而无法正常提供服务。SecondaryNamenode的checkpoint机制可以缓解这一问题
2. 数据恢复Namenode和SecondaryNamenode的工作目录存储结构完全相同,当Namenode故障退出需要重新恢复时,可以从SecondaryNamenode的工作目录中将fsimage拷贝到Namenode的工作目录,以恢复Namenode的元数据。但是SecondaryNamenode最后一次合并之后的更新操作的元数据将会丢失,最好Namenode元数据的文件夹放在多个磁盘上面进行冗余,降低数据丢失的可能性。
注意事项:
1. SecondaryNamenode只有在第一次进行元数据合并时需要从Namenode下载fsimage到本地。SecondaryNamenode在第一次元数据合并完成并上传到Namenode后,所持有的fsimage已是最新的fsimage,无需再从Namenode处获取,而只需要获取edits文件即可。
2. SecondaryNamenode从Namenode上将要合并的edits和fsimage拷贝到自己当前服务器上,然后将fsimage和edits反序列化到SecondaryNamenode的内存中,进行计算合并。因此一般需要把Namenode和SecondaryNamenode分别部署到不同的机器上面,且SecondaryNamenode服务器配置要求一般不低于Namenode。
3. SecondaryNamenode不是充当Namenode的“备服务器”,它的主要作用是进行元数据的checkpoint
Datanode
Datanode作为HDFS集群从节点,负责存储管理用户的文件块数据,并定期向Namenode汇报自身所持有的block信息(这点很重要,因为,当集群中发生某些block副本失效时,集群如何恢复block初始副本数量的问题)。
关于Datanode两个重要的参数:
1. 通过心跳信息上报参数
|
<property> <name>dfs.blockreport.intervalMsec</name> <value>3600000</value> <description>Determines block reporting interval in milliseconds.</description> </property> |
2. Datanode掉线判断时限参数
Datanode进程死亡或者网络故障造成Datanode无法与Namenode通信时,Namenode不会立即把该Datanode判定为死亡,要经过一段时间,这段时间称作超时时长。HDFS默认的超时时长为10分钟30秒。如果定义超时时间为timeout,则超时时长的计算公式为:
timeout = 2 * heartbeat.recheck.interval(默认5分钟) + 10 * dfs.heartbeat.interval(默认3秒)。
|
<property> <name>heartbeat.recheck.interval</name> # 单位毫秒 <value>2000</value> </property> <property> <name>dfs.heartbeat.interval</name> # 单位秒 <value>1</value> </property> |
HDFS读写数据流程
了解了Namenode和Datanode的作用后,就很容易理解HDFS读写数据流程,这个也是面试中经常问的问题。
HDFS写数据流程

注意:
1.文件block块切分和上传是在客户端进行的操作
2.Datanode之间本身是建立了一个RPC通信建立pipeline
3.客户端先从磁盘读取数据放到一个本地内存缓存,开始往Datanode1上传第一个block,以packet为单位,Datanode1收到一个packet就会传给Datanode2,Datanode2传给Datanode3;Datanode1每传一个packet会放入一个应答队列等待应答
4.当一个block传输完成之后,客户端会通知Namenode存储块完毕,Namenode将元数据同步到内存中
5. Datanode之间pipeline传输文件时,一般按照就近可用原则
a) 首先就近挑选一台机器
b) 优先选择另一个机架上的Datanode
c) 在本机架上再随机挑选一台
HDFS读数据流程
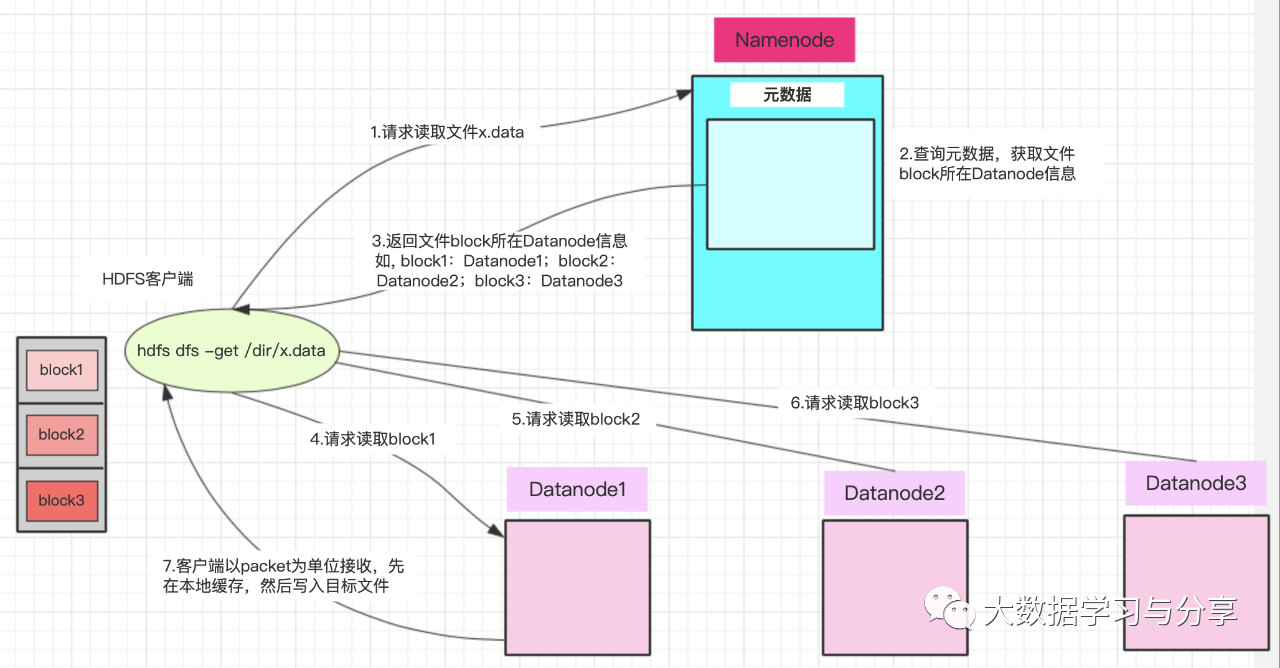
注意:
1. Datanode发送数据,是从磁盘里面读取数据放入流,以packet为单位来做校验
2. 客户端以packet为单位接收,先在本地缓存,然后写入目标文件
客户端将要读取的文件路径发送给namenode,namenode获取文件的元信息(主要是block的存放位置信息)返回给客户端,客户端根据返回的信息找到相应datanode逐个获取文件的block并在客户端本地进行数据追加合并从而获得整个文件
HDFS HA机制
HA:高可用,通过双Namenode消除单点故障。
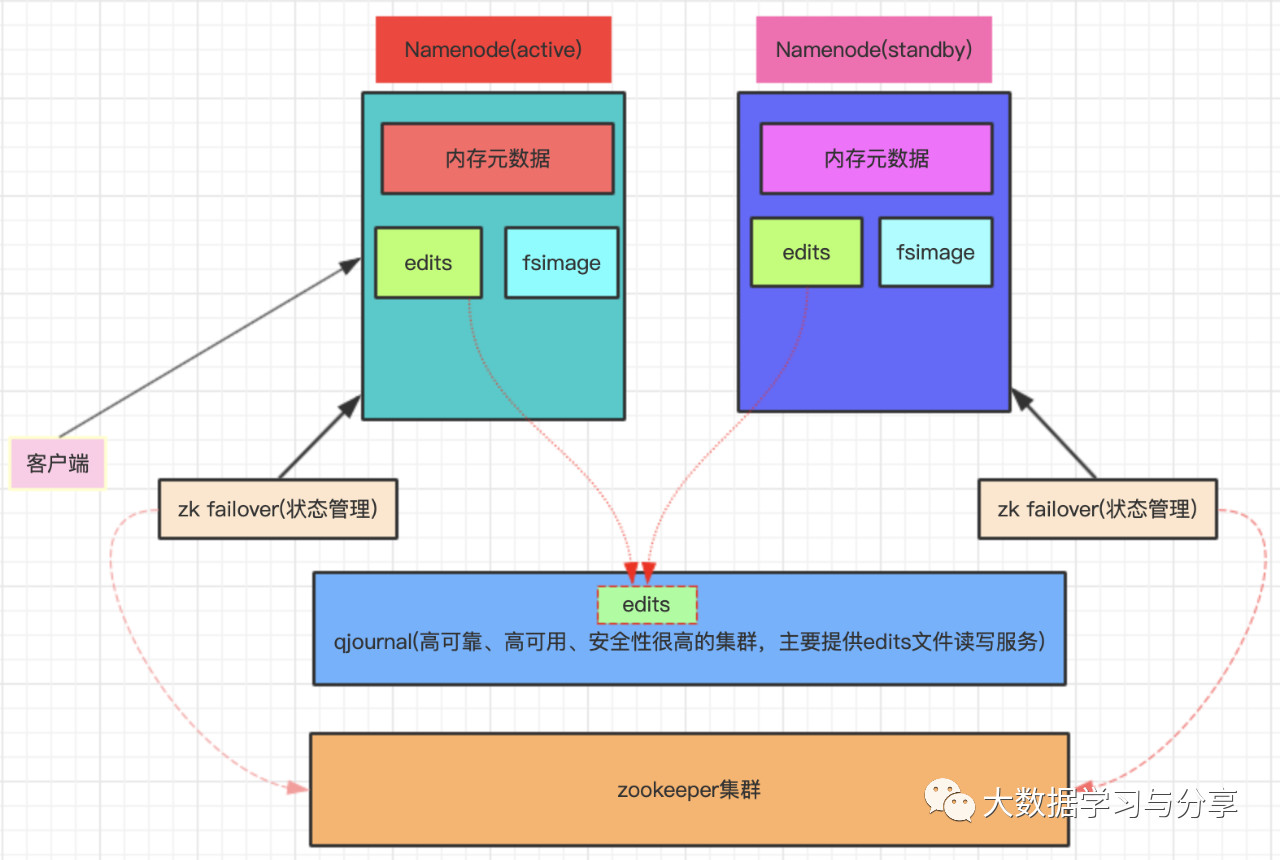
双Namenode协调工作的要点:
1. 元数据管理方式需要改变
a) 内存中各自保存一份元数据
b) edits日志只能有一份,只有active状态的Namenode节点可以做写操作
c) 两个Namenode都可以读取edits
d) 共享的edits放在一个共享存储中管理(qjournal和NFS两个主流实现,图中以放在一个共享存储中管理(qjournal和为例)
2. 需要一个状态管理功能模块
a) 实现了一个zk failover,常驻在每一个Namenode所在的节点
b) 每一个zk failover负责监控自己所在Namenode节点,利用zk进行状态标识,当需要进行状态切换时,由zk failover来负责切换,切换时需要防止brain split现象的发生
关注微信公众号:大数据学习与分享,获取更对技术干货
必须掌握的分布式文件存储系统—HDFS的更多相关文章
- 一图看懂hadoop分布式文件存储系统HDFS工作原理
一图看懂hadoop分布式文件存储系统HDFS工作原理
- Hadoop 三剑客之 —— 分布式文件存储系统 HDFS
一.介绍 二.HDFS 设计原理 2.1 HDFS 架构 2.2 文件系统命名空间 2.3 数据复制 2.4 数据复制的实现原理 2.5 副本的选择 2 ...
- 淘宝分布式文件存储系统:TFS
TFS ——分布式文件存储系统 TFS(Taobao File System)是淘宝针对海量非结构化数据存储设计的分布式系统,构筑在普通的Linux机器集群上,可为外部提供高可靠和高并发的存储访问. ...
- 分布式文件管理系统HDFS
Hadoop 分布式文件管理系统HDFS可以部署在廉价硬件之上,能够高容错. 可靠地存储海量数据(可以达到TB甚至PB级),它还可以和Yam中的MapReduce 编程模型很好地结合,为应用程序提供高 ...
- 用asp.net core结合fastdfs打造分布式文件存储系统
最近被安排开发文件存储微服务,要求是能够通过配置来无缝切换我们公司内部研发的文件存储系统,FastDFS,MongDb GridFS,阿里云OSS,腾讯云OSS等.根据任务紧急度暂时先完成了通过配置来 ...
- redis/分布式文件存储系统/数据库 存储session,解决负载均衡集群中session不一致问题
先来说下session和cookie的异同 session和cookie不仅仅是一个存放在服务器端,一个存放在客户端那么笼统 session虽然存放在服务器端,但是也需要和客户端相互匹配,试想一个浏览 ...
- mogilefs分布式文件存储
MogileFS是一个开源的分布式文件存储系统,由LiveJournal旗下的Danga Interactive公司开发.Danga团队开发了包括 Memcached.MogileFS.Perlbal ...
- 分布式存储系统-HDFS
1 HDFS 架构 HDFS作为分布式文件管理系统,Hadoop的基础.HDFS整体架构包括:NameNode.DataNode.Secondary NameNode,如图: HDFS采用主从式的分布 ...
- Hadoop HDFS概念学习系列之分布式文件管理系统(二十五)
数据量越来越多,在一个操作系统管辖的范围存在不了,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,因此迫切需要一种系统来 管理多台机器上的文件,这就是分布式文件管理系统. 是一种允许文件 ...
随机推荐
- golang开发:select多路选择
select 是 Golang 中的一个控制结构,语法上类似于switch 语句,只不过select是用于 goroutine 间通信的 ,每个 case 必须是一个通信操作,要么是发送要么是接收,s ...
- XSS基础笔记 from 《Web安全攻防 渗透测试实战指南》
XSS漏洞介绍 跨站脚本(Cross Site Scripting, 简称为XSS或跨站脚本或跨站脚本攻击)是一种针对网站应用程序的安全漏洞攻击技术,是代码注入的一种.它允许恶意用户将代码注入网页,其 ...
- 3、JVM中的对象
1.对象的创建 A a = new A() A:引用的类型 a::引用的名称 new A():创建一个A类对象 当创建一个对象时,具体创建过程是什么呢? (1)JVM遇到new的字节码指令后,检查类 ...
- Java 常用类-程序员头大的日期时间API
第二节.日期时间API 一.JDK8之前日期时间API 1.1 java.lang.System类 System类提供的public static long currentTimeMillis()用来 ...
- Python练习题 039:Project Euler 011:网格中4个数字的最大乘积
本题来自 Project Euler 第11题:https://projecteuler.net/problem=11 # Project Euler: Problem 10: Largest pro ...
- 如何设置UITextField的焦点?
需要一进VIEW就显示键盘. 在viewDidLoad函数中调用:[yourUITextField becomeFirstResponder];
- 引用类型之Array(一)
Array类型 除了Object之外,Array类型在ECMAScript中也很常用.ECMAScript中的数组与其他多数语言中的数组有着相当大的区别.ECMAScript数组的每一项可以保存任何类 ...
- JavaScript筛选数组
要求: 从一个数组中,筛选出符合条件的元素,放到新数组中. 有一数组[1, 19, 2, 8, 9, 15, 11, 7, 6, 4, 18, 10],将超过10的元素删除. 代码实现: var ar ...
- 动态枢轴网格使用MVC, AngularJS和WEB API 2
下载shanuAngularMVCPivotGridS.zip - 2.7 MB 介绍 在本文中,我们将详细介绍如何使用AngularJS创建一个简单的MVC Pivot HTML网格.在我之前的文章 ...
- 唯品会Java开发手册》1.0.2版阅读
<唯品会Java开发手册>1.0.2版阅读 1. 概述 <阿里巴巴Java开发手册>,是首个对外公布的企业级Java开发手册,对整个业界都有重要的意义. 我们结合唯品会的内部经 ...