Buffer cache hit ratio性能计数器真的可以作为内存瓶颈的判断指标吗?
Buffer cache hit ratio官方是这么解释的:“指示在缓冲区高速缓存中找到而不需要从磁盘中读取的页的百分比。”
Buffer cache hit ratio被很多人当做判断内存的性能指标之一(我没说仅仅只看这个计数器的值,实际上我现在都不看这个值了),
也有不少给给出了具体的参数,诸如(OLTP)要大于95%,或者是大于98%之类的,我不知道给出具体参考值的人是不是真是地区测试过这个参数的值,是作为经验总结还是复制粘贴?
当我去服务器上观察这个值的时候,似乎发现一个规律,
不管服务器的负载如何,即便是存在较重的业务负载的时候,这个值一直是接近所谓的“理想值”(99%),难道这个值真的可以去作为衡量内存瓶颈的指标吗,
实际上被这个问题困惑了好多天,
我在测试的时候,尽管不断地去压缩SqlServer的最大内存限制,
然后做压力测试,
尽管Page life expectancy可以底到十几二十几毫秒,也就是内存已经存在很严重的瓶颈了,却发现Buffer cache hit ratio这个计数器的值是99%左右,
于是开始怀疑这个计数器的算法,如果说缓冲命中率达到99%左右,能否说明没有内存瓶颈呢?
其实如果做过实际测试,应该不难发现这个问题,对于这个值,早就有人怀疑过了,明明是存在内存的瓶颈,缓存命中率却显示为99%+
只是没发现有人提供满意的答案,具体问题可以参考这个 http://bbs.csdn.net/topics/330018239
下面演示一下测试步骤,测试过程可能比较粗粗略,说明其中原理即可
1,首先限制SqlServer的最大内存为1G,然后依次读取容量大于1G空间的不同的表,看看性能计数器给出的结果
 ,
,
2,创建一张测试表,往里面写入将近1G的数据量

然后再创建跟这个表一样大小的表,目前,这两个表的数据都接近于1G的空间
select * into DBTEST2.dbo.TestBufferCacheHitRatio_BAK from TestBufferCacheHitRatio
3,我们知道SqlServer读取数据的时候,粗略地讲,(如果数据不在缓存中)是现将数据读取到内存,然后再将数据返回给客户端,
测试是我在本机完成的,本机数据库服务器没有任何负载,测试的两个库也是新建的空数据库
造完测试数据之后,
测试之前我先清除所有缓存,dbcc dropcleanbuffers,
然而,由于限制了SqlServer的最大内存限制而1G,忽略SqlServer非数据缓存占用的内存空间,可以粗略地认为,
当对第一个表读取完后,这个表基本上占据满了SqlServer可用内存空间,
如果继续读取另外一张类似表的数据的时候,就要从磁盘上读取了
(实际上已经清除缓存了,主要是为了说明,第一次查询占满了内存,第二次查询必然要从磁盘读取到内存,内存中没有第二次查询的数据的缓存,即便是不清除缓存,也是一个效果),
此时观察Buffer cache hit ratio计数器的值,
理论上说,此时第二张表的数据是直接从磁盘上读取的,也就不存在所谓的缓存,缓存命中率应该是一个非常低的值,甚至是0,
如果实际来观察所谓的“缓存命中率”的值,看看是什么结果
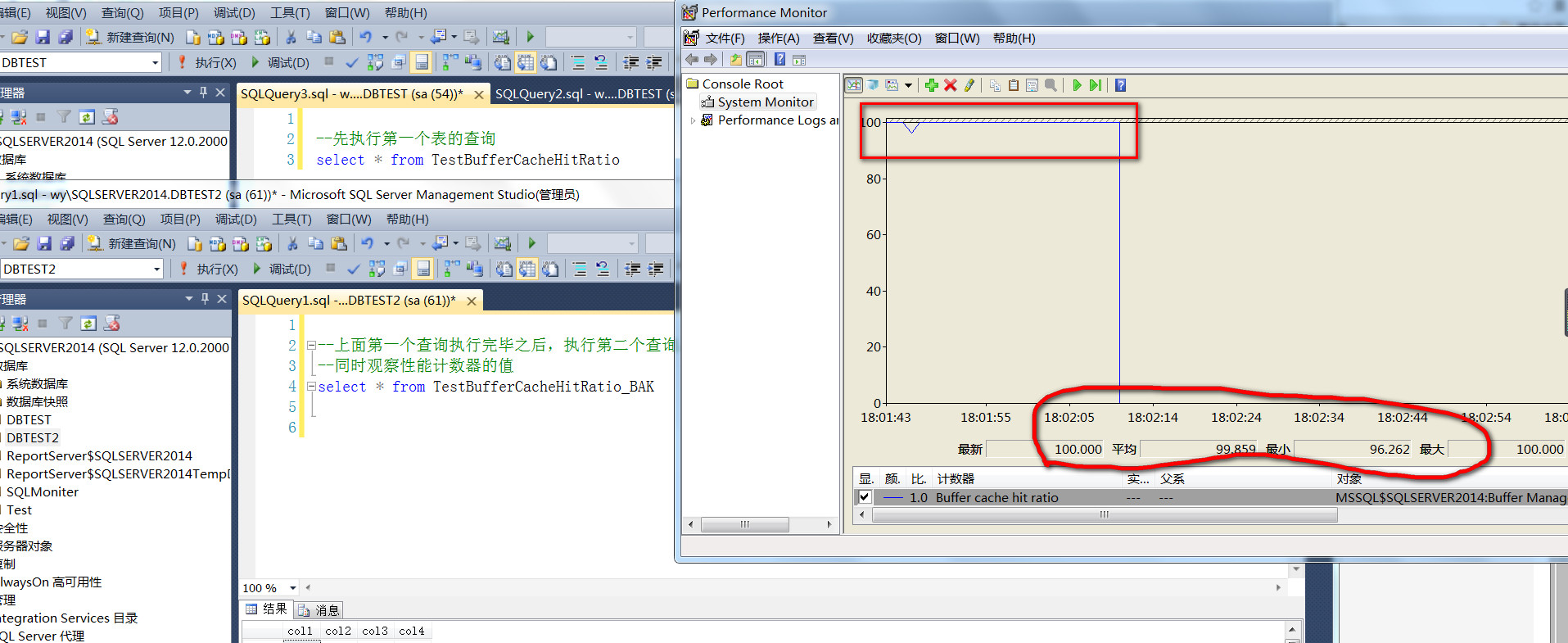
截图是第一个查询执行完成之后,执行第二个查询的时候,Buffer cache hit ratio性能计数器的情况,第二个查询执行完成之后,我暂停了计数器监控,
这个结果应该是不受外界因素影响的(再次说明,我本机数据库没有任何负载,纯粹本机做测试的一个实例,也不用反复测试,我反复测试了N次了,下面会说明原因所在)
从截图可以看到,在第一个查询执行完成之后,
第二个查询执行的过程中,缓存命中率竟然没有明显的下降,最小值也是96%,平均值高达99%,第二个表的数据命名是从磁盘读取的,当然通过IO也可以观察出来,纯粹的预读
这不扯淡吗,测试之前清空过缓存,并且,现有内存已经被第一个查询占据满了,
明明第二张表的数据纯粹第是从硬盘空间读取的,为什么缓存命中率Buffer cache hit ratio竟然高达99%,
难怪之前我观察任何一台服务器的缓存命中率(Buffer cache hit ratio),即便是业务高峰期,都是在99%以上,原因在哪里?
原来是Buffer cache hit ratio这个计数器在计算缓存命中率的时候,
把read ahead read,也即预读读取出来的数据,也算是“缓存”了,只有物理读也即physical read算作非缓存,难怪Buffer cache hit ratio总是有这个高的值
那么就来说说预读,实际上预读是什么?
预读是指在在查询执行之前,预估查询可能要用到的数据,在查询执行之前将数据读取到内存中,
所以,也不难理解,为什么没有把预读产生的数据作为缓存数据来处理。
真正在查询的时候,发现数据不在缓存中,再次去磁盘上读取数据,此时为物理读,而真正没有在“缓存”中命中的数据,就是这部分物理读,
所以缓存命中率中所谓“命中”的缓存的部分,是包含了已缓存的数据和预读的数据。
但是预读所读取出来的数据,虽然是从磁盘上读取出来的,但是在计算缓存的时候,是把这部分数据当做了缓存的
那么怎么证明呢?
可以通过652这个TRACE禁用预读(read ahead read),再同样的测试,看看现在的缓存命中率
执行DBCC TRACEON(652, -1)之后的测试截图
可以看到,本次同样的测试,第一个查询完成之后,第二查询开始,缓存命中率有一个断崖式的下跌,大多数时间是0 ,
平均值也不过是3%的样子(至于为什么存在瞬时缓存命中率的非0的高点,个人猜测是SqlServer缓存的一些进程读取到的元数据缓存)
如果观察IO的话,发现现在的第二个查询没有了预读(read ahead read),全部是物理读(physical read)
这也说明,对于Buffer cache hit ratio这个性能计数器的算法,是把预读读取出来的数据也算作是“缓存”了,如果拿这个值去判断内存瓶颈,是没有参考意义的,当然对于内存瓶颈的判断,可以用其他计数器

问题自己理解起来容易,但是是一边测试一边截图,要做到恰到好处,把问题说明清楚,表达出来真不容易。以后多写些东西锻炼,
总结:在进行内存瓶颈判断的时候,
Buffer cache hit ratio这计数器的值,是不具备参考意义的,即便是观察到Buffer cache hit ratio命中率很高,也不一定代表服务器上没有内存瓶颈,
如果Buffer cache hit ratio命中率很低,极有可能说明存在内存瓶颈,此时还要借助于其他计数器来判断是否存在内存瓶颈,单纯一个Buffer cache hit ratio无法判断内存瓶颈。
后记,对于自己写的东西,经常是诚惶诚恐,生怕误导了别人,同时发现网上有非常多的文章,提到Buffer cache hit ratio,说的似乎是言之凿凿,具体的参考值都给到了,不知道到底有没有去手动验证一下?
Buffer cache hit ratio性能计数器真的可以作为内存瓶颈的判断指标吗?的更多相关文章
- Buffer cache hit ratio性能计数器真的可以作为SQL Server 内存瓶颈的判断指标吗?
SQL Server中对于Buffer cache hit ratio的理解: Buffer cache hit ratio官方是这么解释的:“指示在缓冲区高速缓存中找到而不需要从磁盘中读取的页的百分 ...
- Oracle优化 -- 关于Database Buffer Cache相关参数DB_CACHE_SIZE的优化设置
select size_for_estimate, buffers_for_estimate ,ESTD_PHYSICAL_READ_factor,ESTD_PHYSICAL_READS from v ...
- Buffer cache 的调整与优化
Buffer cache 的调整与优化 -============================== -- Buffer cache 的调整与优化(一) --==================== ...
- [转载]Buffer cache的调整与优化
Buffer Cache是SGA的重要组成部分,主要用于缓存数据块,其大小也直接影响系统的性能.当Buffer Cache过小的时候,将会造成更多的free buffer waits事件.下面将具体描 ...
- buffer cache 深度解析
本文首先详细介绍了oracle中buffer cache的概念以及所包含的内存结构.然后结合各个后台进程(包括DBWRn.CKPT.LGWR等)深入介绍了oracle对于buffer cache的管理 ...
- ORACLE性能优化- Buffer cache 的调整与优化
Buffer Cache是SGA的重要组成部分,主要用于缓存数据块,其大小也直接影响系统的性能.当Buffer Cache过小的时候,将会造成更多的 free buffer waits事件. 下面将具 ...
- BUFFER CACHE之调整buffer cache的大小
Buffer Cache存放真正数据的缓冲区,shared Pool里面存放的是sql指令(LC中一次编译,多次运行,加快处理性能,cache hit ratio要高),而buffer cache里面 ...
- Tuning 04 Sizing the Buffer Cache
Buffer Cache 特性 The buffer cache holds copies of the data blocks from the data files. Because the bu ...
- Linux-内存管理机制、内存监控、buffer/cache异同
在Linux中经常发现空闲内存很少,似乎所有的内存都被系统占用了,表面感觉是内存不够用了,其实不然.这是Linux内存管理的一个优秀特性,主要特点是,无论物理内存有多大,Linux 都将其充份利用,将 ...
随机推荐
- 数据分析之Numpy基础:数组和适量计算
Numpy(Numerical Python)是高性能科学计算和数据分析的基础包. 1.Numpy的ndarray:一种多维数组对象 对于每个数组而言,都有shape和dtype这两个属性来获取数组的 ...
- centos执行yum出现Could not retrieve mirrorlist错误
具体错误见截图 刚开始以为是DNS配置错误,经检查发现DNS与物理机的DNS配置是一样的,物理机可以解析DNS 搜索资料发现是/etc/nsswitch.conf这个文件的问题 这个文件hosts标签 ...
- 解决 PowerDesigner 错误 The generation has been cancelled…
在Model Settings中按照如下图设置即可.
- Webix JavaScript UI 库可以帮你构建跨平台的HTML5 和 CSS3 程序
XB 软件公司最近发布了JavaScript UI 库Webix ,其中包含的组件超过45个,用这些组件可以构建跟HTML5 和 CSS3 兼容的程序,这些程序不仅能在个人电脑上运行,还能用在iOS. ...
- Hadoop学习笔记—14.ZooKeeper环境搭建
从字面上来看,ZooKeeper表示动物园管理员,这是一个十分奇妙的名字,我们又想起了Hadoop生态系统中,许多项目的Logo都采用了动物,比如Hadoop采用了大象的形象,所以我们可以猜测ZooK ...
- AngularJS 中的Promise --- $q服务详解
先说说什么是Promise,什么是$q吧.Promise是一种异步处理模式,有很多的实现方式,比如著名的Kris Kwal's Q还有JQuery的Deffered. 什么是Promise 以前了解过 ...
- 仅此一文让你明白ASP.NET MVC 之Model的呈现(仅此一文系列三)
本文目的 我们来看一个小例子,在一个ASP.NET MVC项目中创建一个控制器Home,只有一个Index: public class HomeController : Controller { pu ...
- 【Java并发编程实战】-----“J.U.C”:ReentrantLock之三unlock方法分析
前篇博客LZ已经分析了ReentrantLock的lock()实现过程,我们了解到lock实现机制有公平锁和非公平锁,两者的主要区别在于公平锁要按照CLH队列等待获取锁,而非公平锁无视CLH队列直接获 ...
- [转]各种移动GPU压缩纹理的使用方法
介绍了各种移动设备所使用的GPU,以及各个GPU所支持的压缩纹理的格式和使用方法.1. 移动GPU大全 目前移动市场的GPU主要有四大厂商系列:1)Imagination Technologies的P ...
- 东哥读书小记 之 《MacTalk人生元编程》
一直以来的自我感觉:自己是个记性偏弱的人.反正从小读书就喜欢做笔记(可自己的字写得巨丑无比,尼玛不科学呀),抄书这事儿真的就常发生俺的身上. 因为那时经常要背诵课文之类,反正为了怕自己忘记, ...