使用python做一个爬虫GUI程序
整体思路和之前的一篇博客爬虫豆瓣美女一致,这次加入了图片分类,同时利用tkinter模块做成GUI程序
效果如下:
整体代码如下:
# -*- coding:utf-8 -*- import requests
from requests.exceptions import RequestException
import tkinter as tk
from tkinter import ttk
from bs4 import BeautifulSoup
import bs4
from tkinter import *
from tkinter.filedialog import askdirectory
import os class DB():
def __init__(self):
self.window = tk.Tk() #创建window窗口
self.window.title("Crawler Pics") # 定义窗口名称
# self.window.resizable(0,0) # 禁止调整窗口大小
self.menu = ttk.Combobox(self.window,width=6)
self.path = StringVar()
self.lab1 = tk.Label(self.window, text = "目标路径:")
self.lab2 = tk.Label(self.window, text="选择分类:")
self.lab3 = tk.Label(self.window, text="爬取页数:")
self.page = tk.Entry(self.window, width=5)
self.input = tk.Entry(self.window, textvariable = self.path, width=80) # 创建一个输入框,显示图片存放路径
self.info = tk.Text(self.window, height=20) # 创建一个文本展示框,并设置尺寸 self.menu['value'] = ('大胸妹','小翘臀', '黑丝袜', '美腿控', '有颜值','大杂烩')
self.menu.current(0) # 添加一个按钮,用于选择图片保存路径
self.t_button = tk.Button(self.window, text='选择路径', relief=tk.RAISED, width=8, height=1, command=self.select_Path)
# 添加一个按钮,用于触发爬取功能
self.t_button1 = tk.Button(self.window, text='爬取', relief=tk.RAISED, width=8, height=1,command=self.download)
# 添加一个按钮,用于触发清空输出框功能
self.c_button2 = tk.Button(self.window, text='清空输出', relief=tk.RAISED,width=8, height=1, command=self.cle) def gui_arrang(self):
"""完成页面元素布局,设置各部件的位置"""
self.lab1.grid(row=0,column=0)
self.lab2.grid(row=1, column=0)
self.menu.grid(row=1, column=1,sticky=W)
self.lab3.grid(row=2, column=0,padx=5,pady=5,sticky=tk.W)
self.page.grid(row=2, column=1,sticky=W)
self.input.grid(row=0,column=1)
self.info.grid(row=3,rowspan=5,column=0,columnspan=3,padx=15,pady=15)
self.t_button.grid(row=0,column=2,padx=5,pady=5,sticky=tk.W)
self.t_button1.grid(row=1,column=2)
self.c_button2.grid(row=0,column=3,padx=5,pady=5,sticky=tk.W) def get_cid(self):
category = {
'DX': 2,
'XQT': 6,
'HSW': 7,
'MTK': 3,
'YYZ': 4,
'DZH': 5
}
cid = None
if self.menu.get() == "大胸妹":
cid = category["DX"]
elif self.menu.get() == "小翘臀":
cid = category["XQT"]
elif self.menu.get() == "黑丝袜":
cid = category["HSW"]
elif self.menu.get() == "美腿控":
cid = category["MTK"]
elif self.menu.get() == "有颜值":
cid = category["YYZ"]
elif self.menu.get() == "大杂烩":
cid = category["DZH"]
return cid def select_Path(self):
"""选取本地路径"""
path_ = askdirectory()
self.path.set(path_) def get_html(self, url, header=None):
"""请求初始url"""
response = requests.get(url, headers=header)
try:
if response.status_code == 200:
# print(response.status_code)
# print(response.text)
return response.text
return None
except RequestException:
print("请求失败")
return None def parse_html(self, html, list_data):
"""提取img的名称和图片url,并将名称和图片地址以字典形式返回"""
soup = BeautifulSoup(html, 'html.parser')
img = soup.find_all('img')
for t in img:
if isinstance(t, bs4.element.Tag):
# print(t)
name = t.get('alt')
img_src = t.get('src')
list_data.append([name, img_src])
dict_data = dict(list_data)
return dict_data def get_image_content(self, url):
"""请求图片url,返回二进制内容"""
print("正在下载", url)
self.info.insert('end',"正在下载:"+url+'\n')
try:
r = requests.get(url)
if r.status_code == 200:
return r.content
return None
except RequestException:
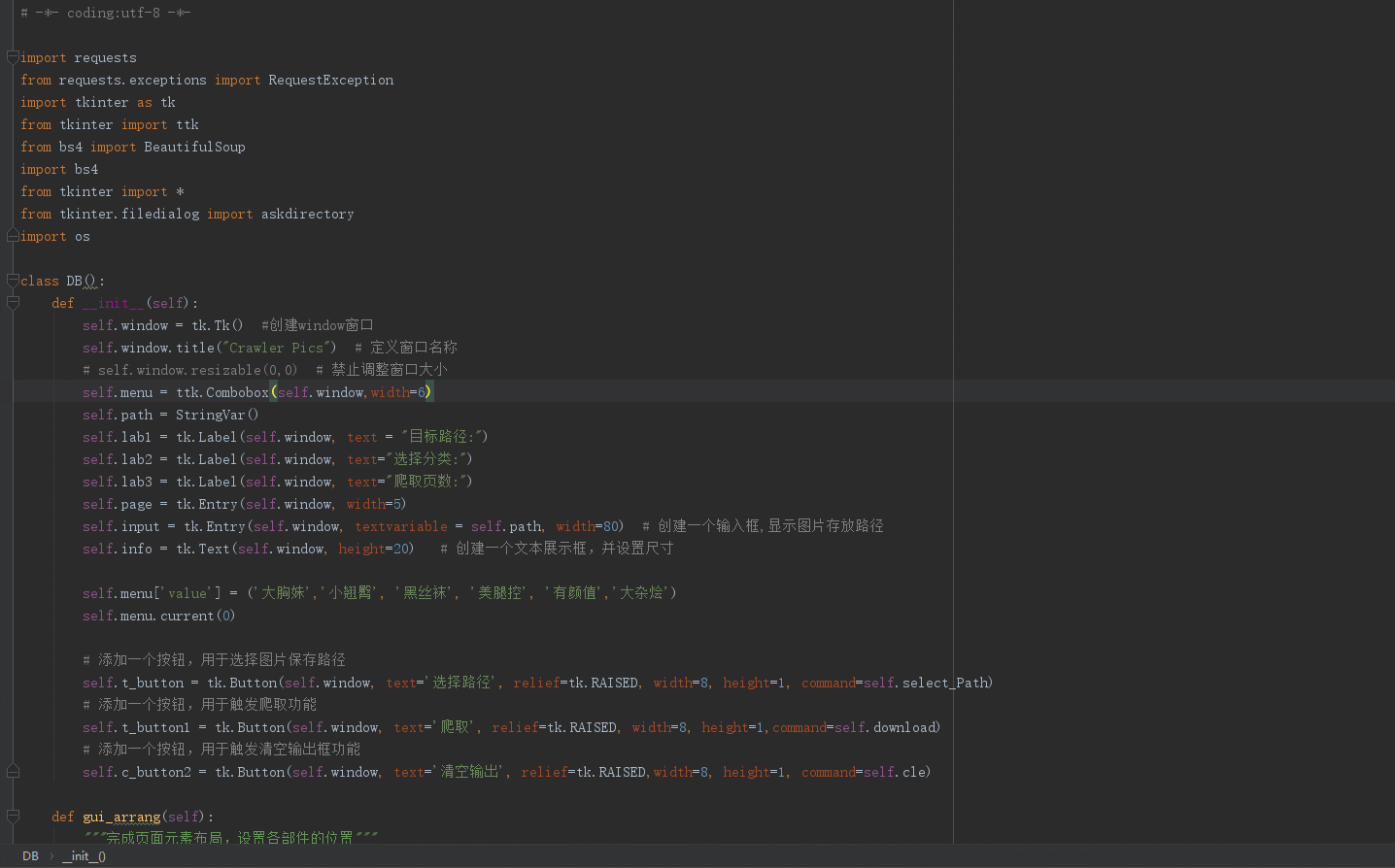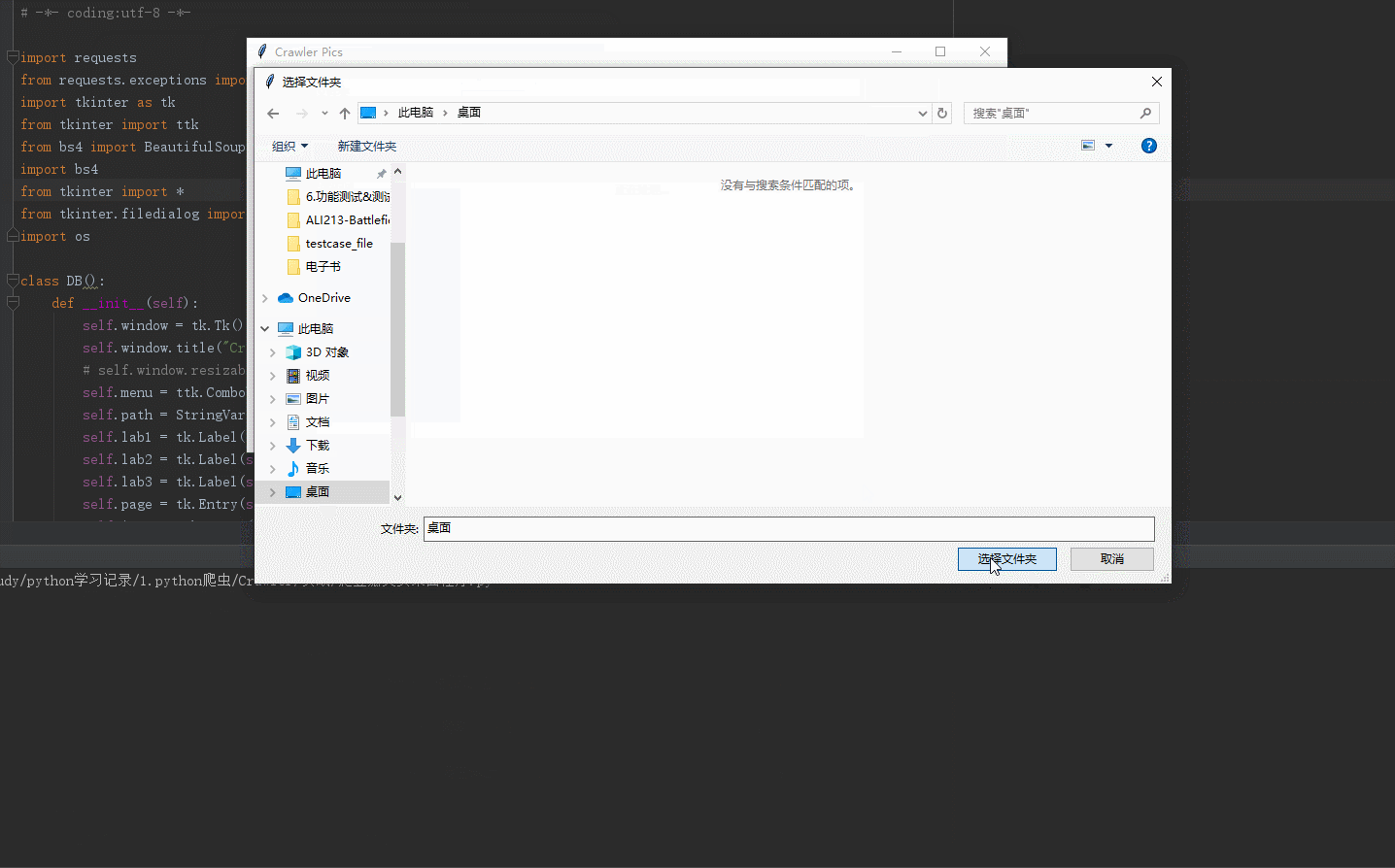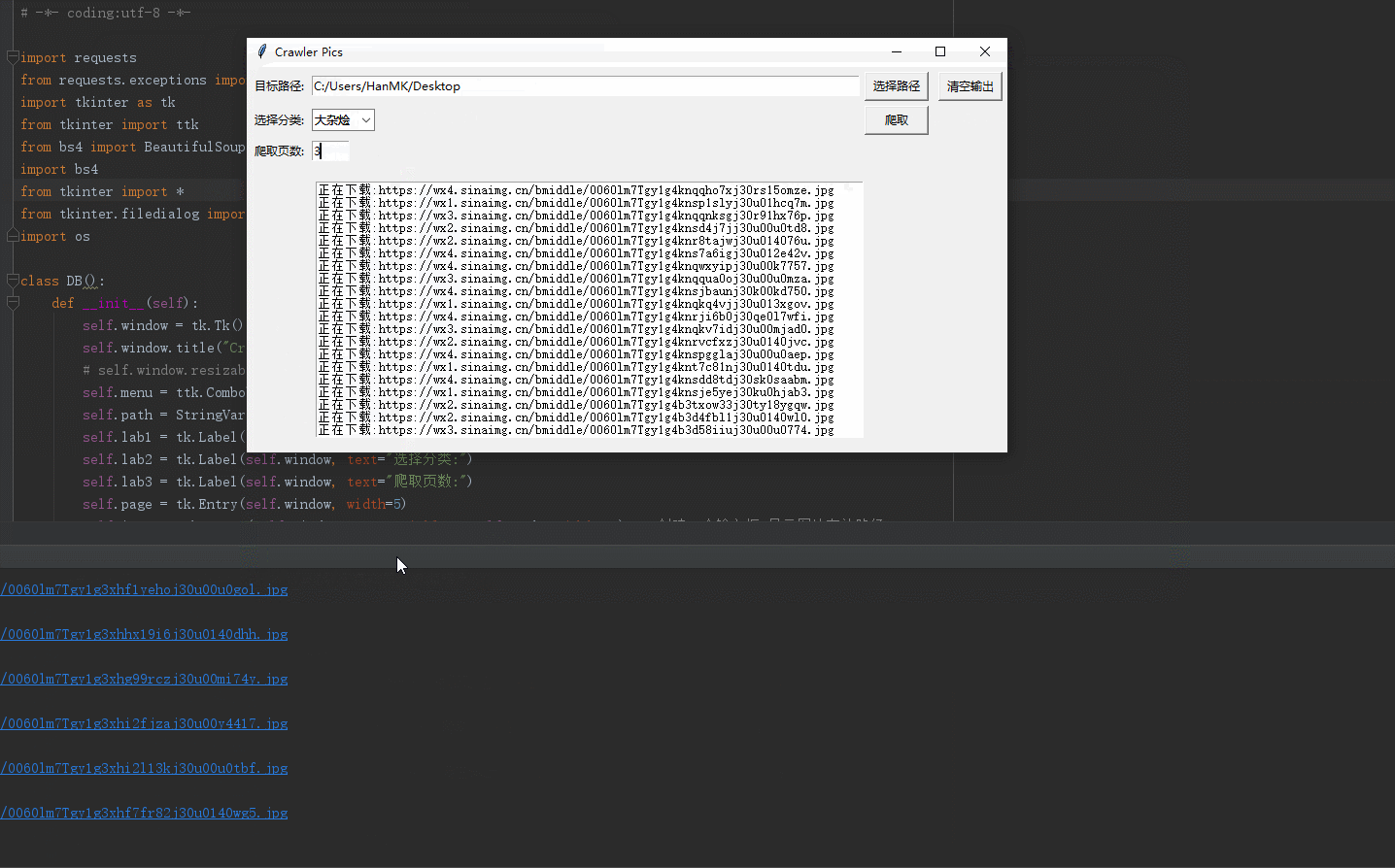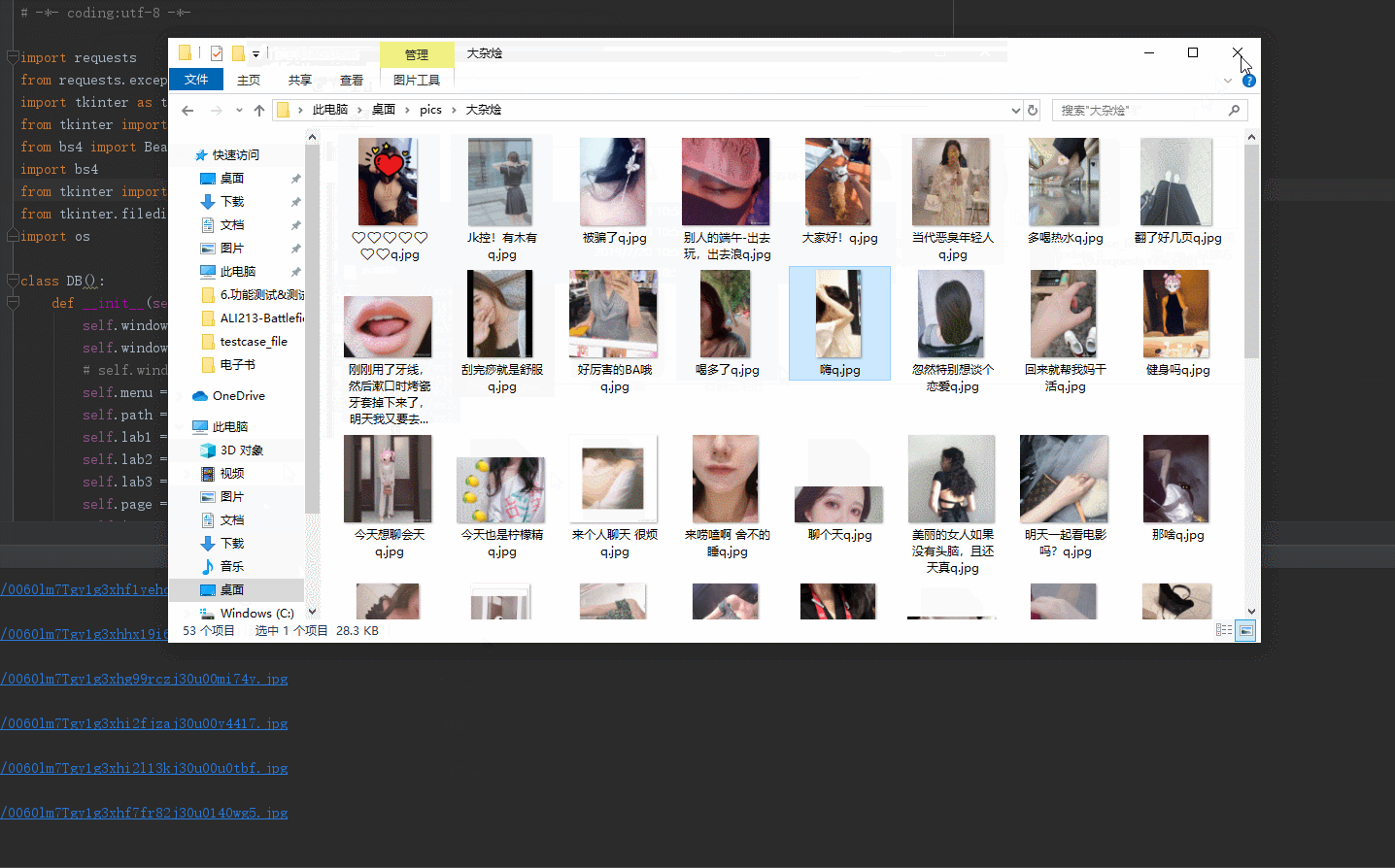
return None def download(self):
base_url = 'https://www.dbmeinv.com/index.htm?'
for i in range(1, int(self.page.get())+1):
url = base_url + 'cid=' + str(self.get_cid()) + '&' + 'pager_offset=' + str(i)
# print(url)
header = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q = 0.9, image/webp,image/apng,*/*;q='
'0.8',
'Accept-Encoding': 'gzip,deflate,br',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Host': 'www.dbmeinv.com',
'Upgrade-Insecure-Requests': '',
'User-Agent': 'Mozilla/5.0(WindowsNT6.1;Win64;x64) AppleWebKit/537.36(KHTML, likeGecko) Chrome/'
'70.0.3538.102Safari/537.36 '
}
list_data = []
html = self.get_html(url)
# print(html)
dictdata = self.parse_html(html, list_data) root_dir = self.input.get()
case_list = ["大胸妹", "小翘臀", "黑丝袜", "美腿控", "有颜值", "大杂烩"]
for t in case_list:
if not os.path.exists(root_dir + '/pics'):
os.makedirs(root_dir + '/pics')
if not os.path.exists(root_dir + '/pics/' + str(t)):
os.makedirs(root_dir + '/pics/' + str(t)) if self.menu.get() == "大胸妹":
save_path = root_dir + '/pics/' + '大胸妹'
for t in dictdata.items():
try:
# file_path = '{0}/{1}.{2}'.format(save_path, t[1], 'jpg')
file_path = save_path + '/' + t[0] + 'q' + '.jpg'
if not os.path.exists(file_path): # 判断是否存在文件,不存在则爬取
with open(file_path, 'wb') as f:
f.write(self.get_image_content(t[1]))
f.close()
print('文件保存成功')
except FileNotFoundError:
continue elif self.menu.get() == "小翘臀":
save_path = root_dir + '/pics/' + '小翘臀'
for t in dictdata.items():
try:
# file_path = '{0}/{1}.{2}'.format(save_path, t[1], 'jpg')
file_path = save_path + '/' + t[0] + 'q' + '.jpg'
if not os.path.exists(file_path): # 判断是否存在文件,不存在则爬取
with open(file_path, 'wb') as f:
f.write(self.get_image_content(t[1]))
f.close()
print('文件保存成功')
except FileNotFoundError:
continue elif self.menu.get() == "黑丝袜":
save_path = root_dir + '/pics/' + '黑丝袜'
for t in dictdata.items():
try:
# file_path = '{0}/{1}.{2}'.format(save_path, t[1], 'jpg')
file_path = save_path + '/' + t[0] + 'q' + '.jpg'
if not os.path.exists(file_path): # 判断是否存在文件,不存在则爬取
with open(file_path, 'wb') as f:
f.write(self.get_image_content(t[1]))
f.close()
print('文件保存成功')
except FileNotFoundError:
continue elif self.menu.get() == "美腿控":
save_path = root_dir + '/pics/' + '美腿控'
for t in dictdata.items():
try:
# file_path = '{0}/{1}.{2}'.format(save_path, t[1], 'jpg')
file_path = save_path + '/' + t[0] + 'q' + '.jpg'
if not os.path.exists(file_path): # 判断是否存在文件,不存在则爬取
with open(file_path, 'wb') as f:
f.write(self.get_image_content(t[1]))
f.close()
print('文件保存成功')
except FileNotFoundError:
continue elif self.menu.get() == "有颜值":
save_path = root_dir + '/pics/' + '有颜值'
for t in dictdata.items():
try:
# file_path = '{0}/{1}.{2}'.format(save_path, t[1], 'jpg')
file_path = save_path + '/' + t[0] + 'q' + '.jpg'
if not os.path.exists(file_path): # 判断是否存在文件,不存在则爬取
with open(file_path, 'wb') as f:
f.write(self.get_image_content(t[1]))
f.close()
print('文件保存成功')
except OSError:
continue elif self.menu.get() == "大杂烩":
save_path = root_dir + '/pics/' + '大杂烩'
for t in dictdata.items():
try:
# file_path = '{0}/{1}.{2}'.format(save_path, t[1], 'jpg')
file_path = save_path + '/' + t[0] + 'q' + '.jpg'
if not os.path.exists(file_path): # 判断是否存在文件,不存在则爬取
with open(file_path, 'wb') as f:
f.write(self.get_image_content(t[1]))
f.close()
print('文件保存成功')
except FileNotFoundError:
continue def cle(self):
"""定义一个函数,用于清空输出框的内容"""
self.info.delete(1.0,"end") # 从第一行清除到最后一行 def main():
t = DB()
t.gui_arrang()
tk.mainloop() if __name__ == '__main__':
main()
关键点:
1.如何使用tkinter调用系统路径
2.构造url,参数化图片分类、抓取页数
3.使用tkinter获取输入参数传给执行代码
下面是练习的时候写的简陋版,不包含tkinter,主要是理清思路:
import re
import requests
import os
from requests.exceptions import RequestException case = str(input("请输入你要下载的图片分类:"))
category = {
'DX': 2,
'XQT': 6,
'HSW': 7,
'MTK': 3,
'YYZ': 4,
'DZH': 5
}
def get_cid():
cid = None
if case == "大胸妹":
cid = category["DX"]
elif case == "小翘臀":
cid = category["XQT"]
elif case == "黑丝袜":
cid = category["HSW"]
elif case == "美腿控":
cid = category["MTK"]
elif case == "有颜值":
cid = category["YYZ"]
elif case == "大杂烩":
cid = category["DZH"]
return cid base_url = 'https://www.dbmeinv.com/index.htm?'
url = base_url + 'cid=' + str(get_cid())
r = requests.get(url)
# print(r.status_code)
html = r.text
# print(r.text)
# print(html) name_pattern = re.compile(r'<img class="height_min".*?title="(.*?)"', re.S)
src_pattern = re.compile(r'<img class="height_min".*?src="(.*?.jpg)"', re.S) name = name_pattern.findall(html) # 提取title
src = src_pattern.findall(html) # 提取src
data = [name,src]
# print(name)
# print(src)
d=[]
for i in range(len(name)):
d.append([name[i], src[i]]) dictdata = dict(d)
# for i in dictdata.items():
# print(i) def get_content(url):
try:
r = requests.get(url)
if r.status_code == 200:
return r.content
return None
except RequestException:
return None root_dir = os.path.dirname(os.path.abspath('.')) case_list = ["大胸妹","小翘臀","黑丝袜","美腿控","有颜值","大杂烩"]
for t in case_list:
if not os.path.exists(root_dir+'/pics'):
os.makedirs(root_dir+'/pics')
if not os.path.exists(root_dir+'/pics/'+str(t)):
os.makedirs(root_dir+'/pics/'+str(t)) def Type(type):
save_path = root_dir + '/pics/' + str(type)
# print(save_path)
for t in dictdata.items():
try:
#file_path = '{0}/{1}.{2}'.format(save_path, t[1], 'jpg')
file_path = save_path + '/' + t[0]+ 'q' +'.jpg'
print("正在下载: "+'"'+t[0]+'"'+t[1])
if not os.path.exists(file_path): # 判断是否存在文件,不存在则爬取
with open(file_path, 'wb') as f:
f.write(get_content(t[1]))
f.close()
except FileNotFoundError:
continue
if case == "大胸妹":
Type(case) elif case == "小翘臀":
Type(case) elif case == "黑丝袜":
Type(case) elif case == "美腿控":
Type(case) elif case == "有颜值":
Type(case) elif case == "大杂烩":
Type(case)
效果如下

使用python做一个爬虫GUI程序的更多相关文章
- 用python做一个搜索引擎(Pylucene)
什么是搜索引擎? 搜索引擎是“对网络信息资源进行搜集整理并提供信息查询服务的系统,包括信息搜集.信息整理和用户查询三部分”.如图1是搜索引擎的一般结构,信息搜集模块从网络采集信息到网络信息库之中(一般 ...
- fir.im Weekly - 如何做一个出色的程序员
做一个出色的程序员,困难而高尚.本期 fir.im Weekly 精选了一些实用的 iOS,Android 开发工具和源码分享,还有一些关于程序员的成长 Tips 和有意思有质量的线下活动~ How ...
- 做一个懒COCOS2D-X程序猿(一)停止手打所有cpp文件到android.mk
前言:”懒”在这里当然不是贬义词,而是追求高效,拒绝重复劳动的代名词!做一个懒COCOS2D-X程序猿的系列文章将教会大家在工作中如何偷懒,文章篇幅大多较短,有的甚至只是几行代码,争取把懒发挥到极致! ...
- 用Python做一个知乎沙雕问题总结
用Python做一个知乎沙雕问题总结 松鼠爱吃饼干2020-04-01 13:40 前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以 ...
- 使用python做一个IRC在线下载器
使用python做一个IRC在线下载器 1.开发流程 2.软件流程 3.开始 3.0 准备工作 3.1寻找API接口 3.2 文件模块 3.2.1 选择文件弹窗 3.2.2 提取文件名 3.2.2.1 ...
- 媳妇儿喜欢玩某音中的动漫特效,那我就用python做一个图片转化软件。
最近某音上的动漫特效特别火,很多人都玩着动漫肖像,我媳妇儿也不例外.看着她这么喜欢这个特效,我决定做一个图片处理工具,这样媳妇儿的动漫头像就有着落了.编码 为了快速实现我们的目标,我们 ...
- 用Python做一个简单的翻译工具
编程本身是跟年龄无关的一件事,不论你现在是十四五岁,还是四五十岁,如果你热爱它,并且愿意持续投入其中,必定会有所收获. 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过 ...
- NetAnalyzer笔记 之 三. 用C++做一个抓包程序
[创建时间:2015-08-27 22:15:17] NetAnalyzer下载地址 经过前两篇的瞎扯,你是不是已经厌倦了呢,那么这篇让我们来点有意思的吧,什么,用C#.不,这篇我们先来C++的 Wi ...
- 在树莓派上用 python 做一个炫酷的天气预报
教大家如何在树莓派上自己动手做一个天气预报.此次教程需要大家有一定的python 基础,没有也没关系,文末我会放出我已写好的代码供大家下载. 首先在开始之前 需要申请高德地图API,去高德地图官网注册 ...
随机推荐
- CF1244F Chips
题目链接 problem 有一个长度为\(n\)个点连成的环.每个点为黑色或白色.当一个点和与他相邻的两个点颜色不同时.该点的颜色就会改变. 问改变\(K\)次后每个点的颜色. solution 发现 ...
- Codeforces Round #599 (Div. 1) C. Sum Balance 图论 dp
C. Sum Balance Ujan has a lot of numbers in his boxes. He likes order and balance, so he decided to ...
- 新手入门:python的安装(一)
windows下python的安装 -----因为我是个真小白,网上的大多入门教程并不适合我这种超级超级小白,有时候还会遇到各种各样的问题,因此记录一下我的安装过程,希望大家都能入门愉快,欢迎指教 - ...
- 扎心一问!你凭什么成为top1%的Java工程师?
目录 1.解决生产环境里的突发故障 2.对棘手的线上性能问题进行优化 3.锻造区别于普通码农的核心竞争力 4.打磨架构设计能力 5.你凭什么成为 top1%? 你工作几年了? 是否天天CRUD到吐 ...
- appium应用切换以及toast弹出框处理
一.应用切换 应用切换的方法很简单,直接调用driver.start_activity()方法,传入app_package和app_activity参数,示例代码如下: from appium imp ...
- Linux 下编写一个 PHP 扩展
假设需求 开发一个叫做 helloWord 的扩展. 扩展里有一个函数,helloWord(). echo helloWord('Tom'); //返回:Hello World: Tom 本地 ...
- PageHelper使用以及PageInfo中分页对象的转化
在使用Mybatis查询数据库展示到前端的过程中不可避免的要考虑到分页问题,这时就引入了Mybatis的PageHelper插件,这个插件对分页功能进行了强有力的封装,只需要将查询出来的数据List集 ...
- SQL常用函数之STR()
使用str函数 :STR 函数由数字数据转换来的字符数据. 语法 STR ( float_expression [ , length [ , ...
- 备战双十一,腾讯WeTest有高招——小程序质量优化必读
WeTest 导读 2018年双十一战场小程序购物通道表现不俗,已逐渐成为各大品牌方角逐的新战场.数据显示,截止目前95%的电商平台都已经上线了小程序.除了电商企业外,许多传统线下商家也开始重视小程序 ...
- awk 输出前 N 列的最简单方法
最近遇到一种场景,需要输出一个文本信息的前 N 列. 众所周知 cut 可以指定分隔符并指定列的范围,如 cut -d' ' -f-4 就是以空格为分隔符输出前 4 列.但是 cut 的分隔符只能是一 ...