pymongo 笔记(转)
1. 安装MongoDB并启动服务,安装PyMongo
2. 连接MongoDB,并指定连接数据库、集合
import pymongo client = pymongo.MongoClient(host='localhost', port=27017)
client = MongoClient('mongodb://localhost:27017/') db = client.test
db = client['test'] collection = db.students
collection = db['students']
3. 插入
student = {
'id': '20170101',
'name': 'Jordan',
'age': 20,
'gender': 'male'
}
'''
result = collection.insert(student)
print(result) #5932a68615c2606814c91f3d
result = collection.insert([student, student])
print(result) #[ObjectId('5932a80115c2606a59e8a048'), ObjectId('5932a80115c2606a59e8a049')]
'''
#PyMongo 3.x版本中推荐使用 insert_one、insert_many
result = collection.insert_one(student)
print(result.inserted_id)
result = collection.insert_many([student, student])
print(result.inserted_ids)
4. 查询
result = collection.find_one({'name': 'Mike'})
print(type(result)) #<class 'dict'>
print(result)
from bson.objectid import ObjectId
result = collection.find_one({'_id': ObjectId('593278c115c2602667ec6bae')}) #查询指定id结果
print(result)
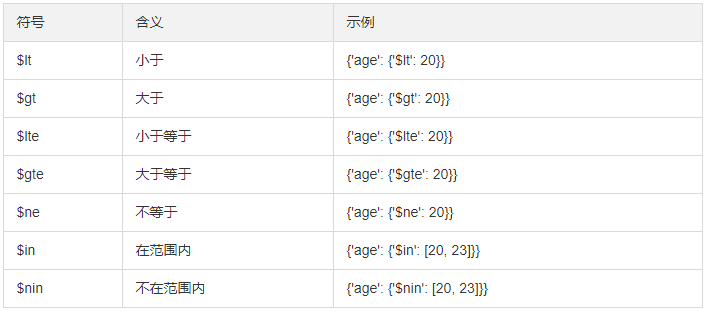
results = collection.find({'age': 20}) #等值查询
results = collection.find({'age': {'$gt': 20}}) #大于20
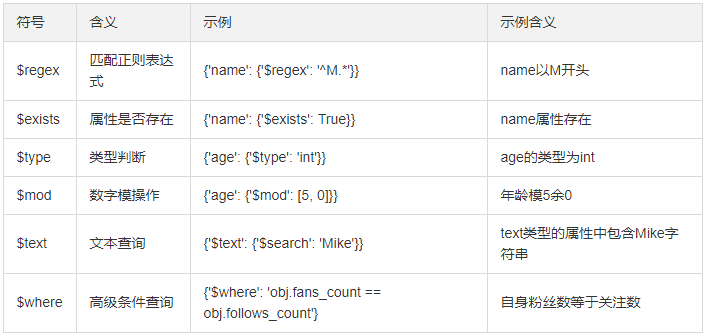
results = collection.find({'name': {'$regex': '^M.*'}}) #正则,M开头
print(results) #cursor对象,相当于生成器
for result in results:
print(result)
5. 计数
count = collection.find().count()
count = collection.find({'age': 20}).count()
print(count)
6. 排序
results = collection.find().sort('name', pymongo.ASCENDING) #DESCENDING
print([result['name'] for result in results])
7. 偏移
''' 忽略前N个元素,取几条
注意:在数据库数量非常庞大的时候,如千万、亿级别,最好不要使用大的偏移量来查询数据,
因为这样很可能导致内存溢出。最好记录上次_id用条件查询
'''
results = collection.find().sort('name', pymongo.ASCENDING).skip(2)
results = collection.find().sort('name', pymongo.ASCENDING).skip(2).limit(2)
print([result['name'] for result in results])
8. 更新
'''
首先指定查询条件,然后将数据查询出来,修改年龄后调用update()方法将原条件和修改后的数据传入。
condition = {'name': 'Kevin'}
student = collection.find_one(condition)
student['age'] = 25
result = collection.update(condition, student)
print(result) #{'ok': 1, 'nModified': 1, 'n': 1, 'updatedExisting': True} 这样可以只更新student字典内存在的字段。如果原先还有其他字段,则不会更新,也不会删除。
而如果不用$set的话,则会把之前的数据全部用student字典替换;如果原本存在其他字段,则会被删除。
result = collection.update(condition, {'$set': student})
''' # 推荐使用
condition = {'name': 'Kevin'}
student = collection.find_one(condition)
student['age'] = 26
result = collection.update_one(condition, {'$set': student}) condition = {'age': {'$gt': 20}}
result = collection.update_one(condition, {'$inc': {'age': 1}}) #年龄+1
#result = collection.update_many(condition, {'$inc': {'age': 1}})
print(result)
print(result.matched_count, result.modified_count)
9. 删除
'''result = collection.remove({'name': 'Kevin'}) #符合条件的所有记录'''
#推荐使用
result = collection.delete_one({'name': 'Kevin'})
result = collection.delete_many({'age': {'$lt': 25}})
print(result)
print(result.deleted_count)
10. 其他组合方法
create_index、create_indexes、drop_index
find_one_and_delete、find_one_and_replace、find_one_and_update
参考链接:
pymongo 笔记(转)的更多相关文章
- Pymongo 笔记
Pymongo 1.MongoDB概念 MongoDB是一种非关系型数据库(NoSQL),MongoDB数据存储于内存,内存不足则将热度低数据写回磁盘.存储的数据结构为文档.每个数据库包含若干集合(c ...
- pymongo 3.3 使用笔记
#首先安装pymongo sudo pip install pymongo || sudo easy_install pymongo #demo均在交互解释器下进行 from pymongo impo ...
- MongoDB学习笔记六:进阶指南
[数据库命令]『命令的工作原理』MongoDB中的命令其实是作为一种特殊类型的查询来实现的,这些查询针对$cmd集合来执行.runCommand仅仅是接受命令文档,执行等价查询,因此,> db. ...
- 《Python 数据科学实践指南》读书笔记
文章提纲 全书总评 C01.Python 介绍 Python 版本 Python 解释器 Python 之禅 C02.Python 基础知识 基础知识 流程控制: 函数及异常 函数: 异常 字符串 获 ...
- 学习笔记:python3,PIP安装第三方库(2017)
https://pip.pypa.io/en/latest/quickstart/ pip的使用文档 http://www.lfd.uci.edu/~gohlke/pythonlibs/ .whl ...
- python高级编程读书笔记(一)
python高级编程读书笔记(一) python 高级编程读书笔记,记录一下基础和高级用法 python2和python3兼容处理 使用sys模块使程序python2和python3兼容 import ...
- python学习笔记比较全
注:本笔记基于python2.6而编辑,尽量的偏向3.x的语法 Python的特色 1.简单 2.易学 3.免费.开源 4.高层语言: 封装内存管理等 5.可移植性: 程序如果避免使用依赖于系统的特性 ...
- 笔记-python lib-pymongo
笔记-python lib-pymongo 1. 开始 pymongo是python版的连接库,最新版为3.7.2. 文档地址:https://pypi.org/project/pymong ...
- Scrapy笔记06- Item Pipeline
Scrapy笔记06- Item Pipeline 当一个item被蜘蛛爬取到之后会被发送给Item Pipeline,然后多个组件按照顺序处理这个item. 每个Item Pipeline组件其实就 ...
随机推荐
- Linux:VIM编辑器的使用
打开vim编辑器 命令格式: vim 文件路径 vim编辑器的工作模式 进入编辑器后 默认为命令模式 进入输入模式 a 在光标后插入 o 换行插入 i 在光标前插入 返回命令模式 esc 键 进入末行 ...
- Ubuntu笔记本安装高级电源管理工具TLP
Ubuntu系统下的笔记本电脑电量总是下降的很快,尽管目前系统对电源管理的优化已经进步了不少,但还是需要一些工具来辅助. TLP是一款Linux下的高级电源管理工具,相信很多Linux用户会用到它. ...
- TensorFlow从1到2(十二)生成对抗网络GAN和图片自动生成
生成对抗网络的概念 上一篇中介绍的VAE自动编码器具备了一定程度的创造特征,能够"无中生有"的由一组随机数向量生成手写字符的图片. 这个"创造能力"我们在模型中 ...
- go语言设计模式之state
state.go package main import ( "fmt" "math/rand" "os" "time" ...
- Re-py交易
python在线反编译 https://tool.lu/pyc/ 获得源码 import base64 def encode(message): s = '' for i in message: x ...
- acwing 76. 和为S的连续正数序列
地址 https://www.acwing.com/problem/content/description/72/ 输入一个正数s,打印出所有和为s的连续正数序列(至少含有两个数). 例如输入15,由 ...
- 【LOJ2402】「THUPC 2017」天天爱射击 / Shooting(整体二分)
点此看题面 大致题意: 有\(n\)个区间,每个区间有一个权值,当权值变成\(0\)时消失.每个时刻将覆盖某一位置的所有区间权值减\(1\),求每个时刻有多少个区间在这一刻消失. 前言 整体二分裸题啊 ...
- Python程序中的进程操作-进程同步(multiprocess.Lock)
目录 一.多进程抢占输出资源 二.使用锁维护执行顺序 三.多进程同时抢购余票 四.使用锁来保证数据安全 通过刚刚的学习,我们千方百计实现了程序的异步,让多个任务可以同时在几个进程中并发处理,他们之间的 ...
- js 元素自动点击/执行问题
a标签对于一下两种方式是无效的: <a href="http://qq.com">QQ</a> $('.obj').click(); $('.obj').t ...
- Python 爬虫介绍,什么是爬虫,如何学习爬虫?
作为程序员,相信大家对“爬虫”这个词并不陌生,身边常常会有人提这个词,在不了解它的人眼中,会觉得这个技术很高端很神秘.不用着急,我们的爬虫系列就是带你去揭开它的神秘面纱,探寻它真实的面目. 爬虫是 ...