Flink是如何实现exactly-once语义的
转自:https://blog.csdn.net/xianpanjia4616/article/details/86375224
最少一次:断了之后 重新执行 再去重
严格一次:根据检查点,再执行一次
-------------------------------------------------------------------------------------------
Flink跟其他的流计算引擎相比,最突出或者做的最好的就是状态的管理.什么是状态呢?比如我们在平时的开发中,需要对数据进行count,sum,max等操作,这些中间的结果(即是状态)是需要保存的,因为要不断的更新,这些值或者变量就可以理解为是一种状态,拿读取kafka为例,我们需要记录数据读取的位置(即是偏移量),并保存offest,这时offest也可以理解为是一种状态.
Flink是怎么保证容错恢复的时候保证数据没有丢失也没有数据的冗余呢?checkpoint是使Flink 能从故障恢复的一种内部机制。检查点是 Flink 应用状态的一个一致性副本,包括了输入的读取位点。在发生故障时,Flink 通过从检查点加载应用程序状态来恢复,并从恢复的读取位点继续处理,就好像什么事情都没发生一样。Flink的状态存储在Flink的内部,这样做的好处就是不再依赖外部系统,降低了对外部系统的依赖,在Flink的内部,通过自身的进程去访问状态变量.同时会定期的做checkpoint持久化,把checkpoint存储在一个分布式的持久化系统中,如果发生故障,就会从最近的一次checkpoint中将整个流的状态进行恢复.
下面就来介绍一下Flink从Kafka中获取数据,怎么管理offest实现exactly-once的.
Apache Flink 中实现的 Kafka 消费者是一个有状态的算子(operator),它集成了 Flink 的检查点机制,它的状态是所有 Kafka 分区的读取偏移量。当一个检查点被触发时,每一个分区的偏移量都被存到了这个检查点中。Flink 的检查点机制保证了所有 operator task 的存储状态都是一致的。这里的“一致的”是什么意思呢?意思是它们存储的状态都是基于相同的输入数据。当所有的 operator task 成功存储了它们的状态,一个检查点才算完成。因此,当从潜在的系统故障中恢复时,系统提供了 excatly-once 的状态更新语义。
下面我们将一步步地介绍 Apache Flink 中的 Kafka 消费位点是如何做检查点的。在本文的例子中,数据被存在了 Flink 的 JobMaster 中。值得注意的是,在 POC 或生产用例下,这些数据最好是能存到一个外部文件系统(如HDFS或S3)中。
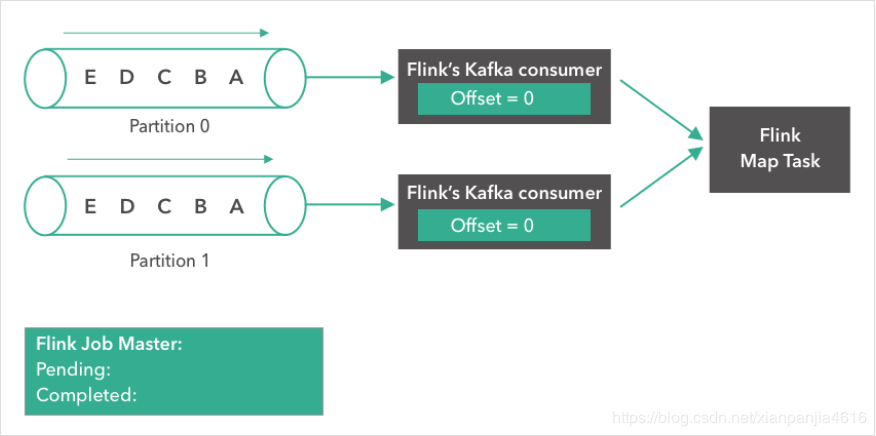
第一步:
如下所示,一个 Kafka topic,有两个partition,每个partition都含有 “A”, “B”, “C”, ”D”, “E” 5条消息。我们将两个partition的偏移量(offset)都设置为0.
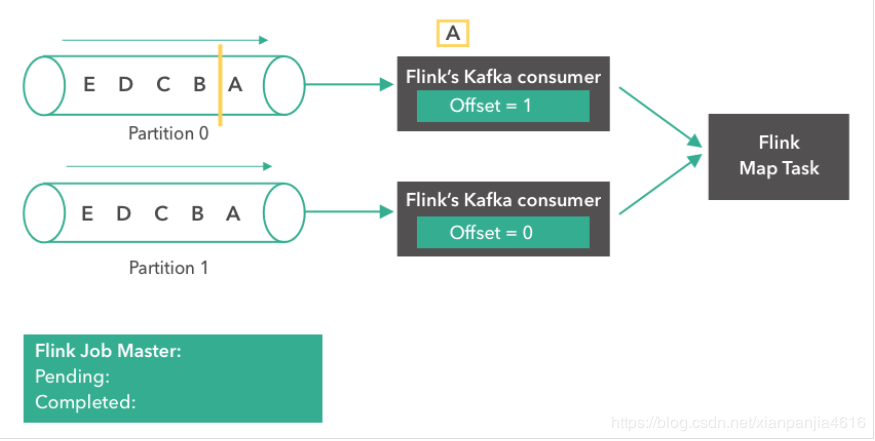
第二步:
Kafka comsumer(消费者)开始从 partition 0 读取消息。消息“A”正在被处理,第一个 consumer 的 offset 变成了1。
第三步:
消息“A”到达了 Flink Map Task。两个 consumer 都开始读取他们下一条消息(partition 0 读取“B”,partition 1 读取“A”)。各自将 offset 更新成 2 和 1 。同时,Flink 的 JobMaster 开始在 source 触发了一个检查点。

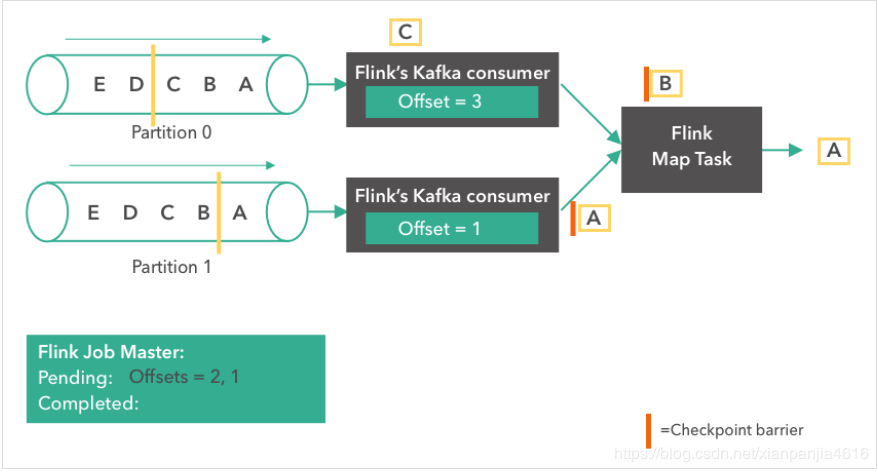
第四步:
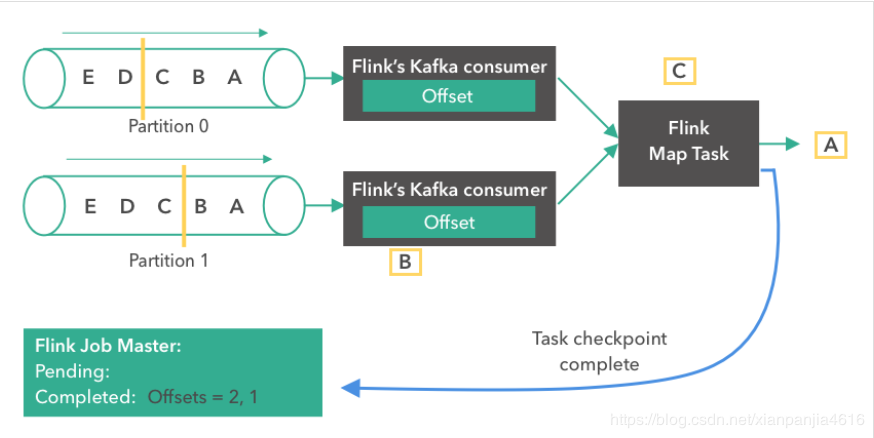
接下来,由于 source 触发了检查点,Kafka consumer 创建了它们状态的第一个快照(”offset = 2, 1”),并将快照存到了 Flink 的 JobMaster 中。Source 在消息“B”和“A”从partition 0 和 1 发出后,发了一个 checkpoint barrier。Checkopint barrier 用于各个 operator task 之间对齐检查点,保证了整个检查点的一致性。消息“A”到达了 Flink Map Task,而上面的 consumer 继续读取下一条消息(消息“C”)。
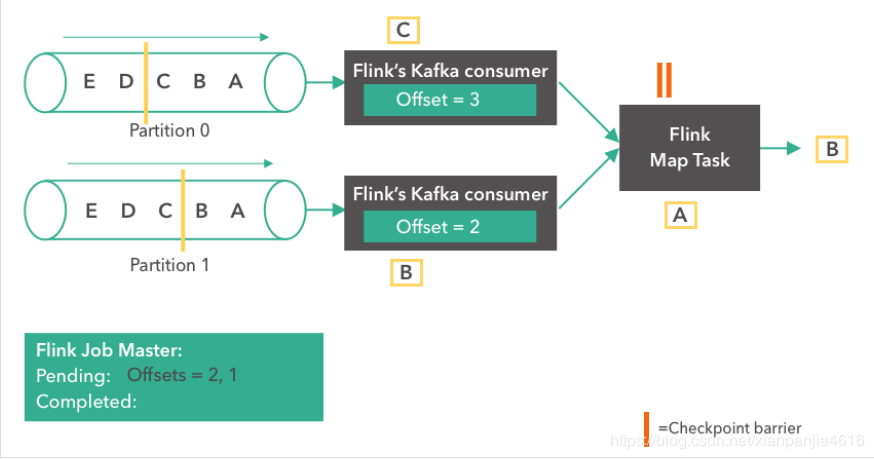
第五步:
Flink Map Task 收齐了同一版本的全部 checkpoint barrier 后,那么就会将它自己的状态也存储到 JobMaster。同时,consumer 会继续从 Kafka 读取消息。
第六步:
Flink Map Task 完成了它自己状态的快照流程后,会向 Flink JobMaster 汇报它已经完成了这个 checkpoint。当所有的 task 都报告完成了它们的状态 checkpoint 后,JobMaster 就会将这个 checkpoint 标记为成功。从此刻开始,这个 checkpoint 就可以用于故障恢复了。值得一提的是,Flink 并不依赖 Kafka offset 从系统故障中恢复。
故障恢复
在发生故障时(比如,某个 worker 挂了),所有的 operator task 会被重启,而他们的状态会被重置到最近一次成功的 checkpoint。Kafka source 分别从 offset 2 和 1 重新开始读取消息(因为这是完成的 checkpoint 中存的 offset)。当作业重启后,我们可以期待正常的系统操作,就好像之前没有发生故障一样。如下图所示:

Flink的checkpoint是基于Chandy-Lamport算法的分布式一致性快照,如果想更加深入的了解Flink的checkpoint可以去了解一下这个算法.
原文地址:https://www.da-platform.com/blog/how-apache-flink-manages-kafka-consumer-offsets
Flink是如何实现exactly-once语义的的更多相关文章
- Flink 如何通过2PC实现Exactly-once语义 (源码分析)
Flink通过全局快照能保证内部处理的Exactly-once语义 但是端到端的Exactly-once还需要下游数据源配合,常见的通过幂等或者二阶段提交这两种方式保证 这里就来分析一下Sink二阶段 ...
- Flink+kafka实现Wordcount实时计算
1. Flink Flink介绍: Flink 是一个针对流数据和批数据的分布式处理引擎.它主要是由 Java 代码实现.目前主要还是依靠开源社区的贡献而发展.对 Flink 而言,其所要处理的主要场 ...
- Apache Flink 漫谈系列 - JOIN 算子
聊什么 在<Apache Flink 漫谈系列 - SQL概览>中我们介绍了JOIN算子的语义和基本的使用方式,介绍过程中大家发现Apache Flink在语法语义上是遵循ANSI-SQL ...
- Apache Flink SQL
本篇核心目标是让大家概要了解一个完整的 Apache Flink SQL Job 的组成部分,以及 Apache Flink SQL 所提供的核心算子的语义,最后会应用 TumbleWindow 编写 ...
- Flink初探-为什么选择Flink
本文主要记录一些关于Flink与storm,spark的区别, 优势, 劣势, 以及为什么这么多公司都转向Flink. What Is Flink 一个通俗易懂的概念: Apache Flink 是近 ...
- Flink Kafka Connector 与 Exactly Once 剖析
Flink Kafka Connector 是 Flink 内置的 Kafka 连接器,它包含了从 Kafka Topic 读入数据的 Flink Kafka Consumer 以及向 Kafka T ...
- flink实时数仓从入门到实战
第一章.flink实时数仓入门 一.依赖 <!--Licensed to the Apache Software Foundation (ASF) under oneor more contri ...
- 不一样的Flink入门教程
前言 微信搜[Java3y]关注这个朴实无华的男人,点赞关注是对我最大的支持! 文本已收录至我的GitHub:https://github.com/ZhongFuCheng3y/3y,有300多篇原创 ...
- Flink Exactly-once 实现原理解析
关注公众号:大数据技术派,回复"资料",领取1024G资料. 这一课时我们将讲解 Flink "精确一次"的语义实现原理,同时这也是面试的必考点. Flink ...
- 浅谈一下流式处理平台Flink
浅谈一下流式处理平台(Flink) 大数据框架听过很多,比如 Hadoop,HDFS...不过自己的项目都没有上过 为什么突然提到 Flink,因为最近一个项目需要用到,所以学习最好的方式就是项目驱动 ...
随机推荐
- SpringBoot系列之@PropertySource用法简介
SpringBoot系列之@PropertySource用法简介 继上篇博客:SpringBoot系列之@Value和@ConfigurationProperties用法对比之后,本博客继续介绍一下@ ...
- 14-认识DjangoRESTframework
了解DjangoRESTframework 现在流行的前后端分离Web应用模式,然而在开发Web应用中,有两种应用模式:1.前后端不分离 2.前后端分离. 1.前后端不分离 在前后端不分离中,前端看见 ...
- C++入门到理解阶段二基础篇(1)——简介与环境安装
1.C++ 简介 C++ 是一种静态类型的.编译式的.通用的.大小写敏感的.不规则的编程语言,支持过程化编程.面向对象编程和泛型编程. C++ 被认为是一种中级语言,它综合了高级语言和低级语言的特点. ...
- Spring MVC整合FreeMarker
什么是Freemarker? FreeMarker是一个用Java语言编写的模板引擎,它基于模板来生成文本输出.FreeMarker与Web容器无关,即在Web运行时,它并不知道Servlet或 ...
- jQuery 源码分析(十五) 数据操作模块 val详解
jQuery的属性操作模块总共有4个部分,本篇说一下最后一个部分:val值的操作,也是属性操作里最简单的吧,只有一个API,如下: val(vlaue) ;获取匹配元素集合中第一个元素的 ...
- CAT 默认密码修改
修改操作 1.按照如下路径,打开SessionManager类,cat-home目录下:com.dianping.cat.system.page.login.service.SessionManage ...
- Junit单元测试数据生成工具类
在Junit单元测试中,经常需要对一些领域模型的属性赋值,以便传递给业务类测试,常见的场景如下: com.enation.javashop.Goods goods = new com.enation. ...
- 按需动态加载js
有些时间我们希望能按需动态加载js文件,而不是直接在HTML中写script标签. 以下为示例代码: var js = document.createElement('script'); js.asy ...
- jqgrid后台处理搜索
jqgrid后台处理搜索, 如果点击jqgrid自带的搜索,则向后台传递“_search”参数,和searchField.searchOper.searchString三个值.如下所示: string ...
- IOS疯狂基础之屏幕旋转控制,获得当前方向(转)
转自:http://blog.csdn.net/wudizhukk/article/details/8674393 获得当前屏幕方向 self.interfaceOrientation或[[UIApp ...