Python的网页解析库-PyQuery
PyQuery库也是一个非常强大又灵活的网页解析库,如果你有前端开发经验的,都应该接触过jQuery,那么PyQuery就是你非常绝佳的选择,PyQuery 是 Python 仿照 jQuery 的严格实现。语法与 jQuery 几乎完全相同,所以不用再去费心去记一些奇怪的方法了。
官网地址:http://pyquery.readthedocs.io/en/latest/
jQuery参考文档: http://jquery.cuishifeng.cn/
初始化
初始化的时候一般有三种传入方式:传入字符串,传入url,传入文件
字符串初始化

html = '''
<div>
<ul>
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
print(doc)
print(type(doc))
print(doc('li'))
结果如下:
由于PyQuery写起来比较麻烦,所以我们导入的时候都会添加别名:
from pyquery import PyQuery as pq
这里我们可以知道上述代码中的doc其实就是一个pyquery对象,我们可以通过doc可以进行元素的选择,其实这里就是一个css选择器,所以CSS选择器的规则都可以用,直接doc(标签名)就可以获取所有的该标签的内容,如果想要获取class 则doc('.class_name'),如果是id则doc('#id_name')....
URL初始化
from pyquery import PyQuery as pq
doc = pq(url="http://www.baidu.com",encoding='utf-8')
print(doc('head'))
文件初始化
我们在pq()这里可以传入url参数也可以传入文件参数,当然这里的文件通常是一个html文件,例如:pq(filename='index.html')
基本的CSS选择器
html = '''
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
print(doc('#container .list li'))
这里我们需要注意的一个地方是doc('#container .list li'),这里的三者之间的并不是必须要挨着,只要是层级关系就可以,下面是常用的CSS选择器方法:
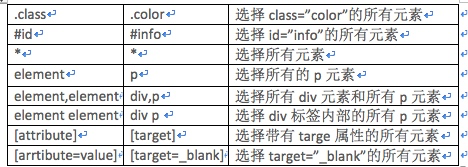
查找元素
子元素
children,find
代码例子:
html = '''
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
items = doc('.list')
print(type(items))
print(items)
lis = items.find('li')
print(type(lis))
print(lis)
运行结果如下
从结果里我们也可以看出通过pyquery找到结果其实还是一个pyquery对象,可以继续查找,上述中的代码中的items.find('li') 则表示查找ul里的所有的li标签
当然这里通过children可以实现同样的效果,并且通过.children方法得到的结果也是一个pyquery对象
li = items.children() print(type(li)) print(li)
同时在children里也可以用CSS选择器
li2 = items.children('.active') print(li2)
父元素
parent,parents方法
通过.parent就可以找到父元素的内容,例子如下:
html = '''
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
items = doc('.list')
container = items.parent()
print(type(container))
print(container)
通过.parents就可以找到祖先节点的内容,例子如下:
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
items = doc('.list')
parents = items.parents()
print(type(parents))
print(parents)
结果如下:从结果我们可以看出返回了两部分内容,一个是的父节点的信息,一个是父节点的父节点的信息即祖先节点的信息
同样我们通过.parents查找的时候也可以添加css选择器来进行内容的筛选
兄弟元素
siblings
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('.list .item-0.active')
print(li.siblings())
代码中doc('.list .item-0.active') 中的.tem-0和.active是紧挨着的,所以表示是并的关系,这样满足条件的就剩下一个了:thired item的那个标签了
这样在通过.siblings就可以获取所有的兄弟标签,当然这里是不包括自己的
同样的在.siblings()里也是可以通过CSS选择器进行筛选
遍历
单个元素
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('.item-0.active')
print(li)
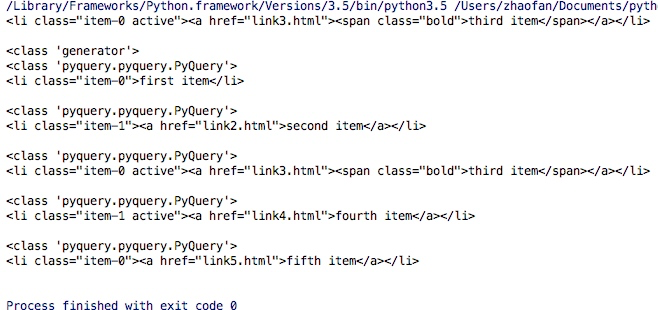
lis = doc('li').items()
print(type(lis))
for li in lis:
print(type(li))
print(li)
运行结果如下:从结果中我们可以看出通过items()可以得到一个生成器,并且我们通过for循环得到的每个元素依然是一个pyquery对象。
获取信息
获取属性
pyquery对象.attr(属性名)
pyquery对象.attr.属性名
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
a = doc('.item-0.active a')
print(a)
print(a.attr('href'))
print(a.attr.href)
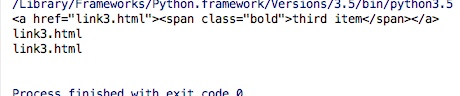
所以这里我们也可以知道获得属性值的时候可以直接a.attr(属性名)或者a.attr.属性名
获取文本
在很多时候我们是需要获取被html标签包含的文本信息,通过.text()就可以获取文本信息
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
a = doc('.item-0.active a')
print(a)
print(a.text())
结果如下:

获取html
我们通过.html()的方式可以获取当前标签所包含的html信息,例子如下:
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('.item-0.active')
print(li)
print(li.html())
结果如下:

DOM操作
addClass、removeClass
熟悉前端操作的话,通过这两个操作可以添加和删除属性
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('.item-0.active')
print(li)
li.removeClass('active')
print(li)
li.addClass('active')
print(li)
attr,css
同样的我们可以通过attr给标签添加和修改属性,
如果之前没有该属性则是添加,如果有则是修改
我们也可以通过css添加一些css属性,这个时候,标签的属性里会多一个style属性
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('.item-0.active')
print(li)
li.attr('name', 'link')
print(li)
li.css('font-size', '14px')
print(li)
结果如下:

remove
有时候我们获取文本信息的时候可能并列的会有一些其他标签干扰,这个时候通过remove就可以将无用的或者干扰的标签直接删除,从而方便操作
html = '''
<div class="wrap">
Hello, World
<p>This is a paragraph.</p>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
wrap = doc('.wrap')
print(wrap.text())
wrap.find('p').remove()
print(wrap.text())
结果如下:

pyquery中DOM的其他api操作参考:
http://pyquery.readthedocs.io/en/latest/api.html
Python的网页解析库-PyQuery的更多相关文章
- Python网页解析库:用requests-html爬取网页
Python网页解析库:用requests-html爬取网页 1. 开始 Python 中可以进行网页解析的库有很多,常见的有 BeautifulSoup 和 lxml 等.在网上玩爬虫的文章通常都是 ...
- 【Python爬虫】BeautifulSoup网页解析库
BeautifulSoup 网页解析库 阅读目录 初识Beautiful Soup Beautiful Soup库的4种解析器 Beautiful Soup类的基本元素 基本使用 标签选择器 节点操作 ...
- 网页解析库-Xpath语法
网页解析库 简介 除了正则表达式外,还有其他方便快捷的页面解析工具 如:lxml (xpath语法) bs4 pyquery等 Xpath 全称XML Path Language, 即XML路径语言, ...
- Python_爬虫_BeautifulSoup网页解析库
BeautifulSoup网页解析库 from bs4 import BeautifulSoup 0.BeautifulSoup网页解析库包含 的 几个解析器 Python标准库[主要,系统自带;] ...
- python爬虫网页解析之lxml模块
08.06自我总结 python爬虫网页解析之lxml模块 一.模块的安装 windows系统下的安装: 方法一:pip3 install lxml 方法二:下载对应系统版本的wheel文件:http ...
- python爬虫网页解析之parsel模块
08.06自我总结 python爬虫网页解析之parsel模块 一.parsel模块安装 官网链接https://pypi.org/project/parsel/1.0.2/ pip install ...
- 小白学 Python 爬虫(23):解析库 pyquery 入门
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- Python爬虫【解析库之pyquery】
该库跟jQuery的使用方法基本一样 http://pyquery.readthedocs.io/ 官方文档 解析库的安装 pip3 install pyquery 初始化 1.字符串初始化 htm ...
- python3解析库pyquery
pyquery是一个类似jquery的python库,它实现能够在xml文档中进行jQuery查询,pyquery使用lxml解析器进行快速在xml和html文档上操作,它提供了和jQuery类似的语 ...
随机推荐
- 第六篇 -- LINQ to XML
一.LINQ to XML常用成员 LINQ to XML的成员, 属性列表: 属性 说明 Document 获取此 XObject 的 XDocument EmptySequence 获取空的元 ...
- Arthas - 开源的java诊断工具,非常有用
常用命令 help 查看帮助 help COMMAND 查看指定命令的详细帮助 COMMAND -h 查看指定命令的详细帮助 double tab 查看支持的所有命令 dashboard 查看线程JV ...
- js的类型系统--js基于原型的基石是所有对象最终都能够类型自证
一.动态类型 变量能够类型自证的类型即为动态类型 二.基础与内置类型 三.对象与类型的关系 1.对象本身能够自证为基本类型: 2.元原型可能为一个空的集合: 3.复合对象的成员能够自证为基本类型: 4 ...
- rxswift的双向绑定
将值域与控件域一同提升为rx的monand域,然后进行绑定. 类型提升. 在之前的文章样例中,所有的绑定都是单向的.但有时候我们需要实现双向绑定.比如将控件的某个属性值与 ViewModel里的某个 ...
- oracle封装OracleHelper
1.Oracle 封装类 using System; using System.Collections.Generic; using System.Linq; using System.Text; u ...
- FitNesseRoot/ErrorLogs目录下可查看fitnesse输出日志
调试fitnesse用例时,通过测试页面的输出信息不是很好定位问题出在哪里 这时可以在写代码过程中,增加一些输出信息,比如说java的话,可以用log4j.注意要把日志输出弄成utf-8编码,不然会中 ...
- 从WinDbg中的转储查看操作系统版本和SP详细信息
这是一个很常见的问题,我们几乎总是遇到.想象一下这样一种情况,我们从某个地方得到一个内存转储,想看看在那里运行的是什么操作系统,安装了什么SP..为此,有一个非常简单的命令. 0:000> ve ...
- Linux后台开发工具箱-葵花宝典
Linux后台开发工具箱-葵花宝典 一见 2016/11/4 目录 目录 1 1. 前言 4 2. 脚本类工具 4 2.1. 双引号和单引号 4 2.2. 取脚本完整文件路径 5 2.3. 环境变量和 ...
- 细说PHP-fpm
在理解php-fpm之前,我们要先搞清楚几个关键词以及他们之间的关系:CGI FastCGI:(Fast Common Gateway Interface),即快速通用网关接口,是一种让交互程序与We ...
- 【题解】洛谷 P1080 国王游戏
目录 题目 思路 \(Code\) 题目 P1080 国王游戏 思路 贪心+高精度.按\(a \times b\)从小到大排序就可以了. \(Code\) #include<bits/stdc+ ...