count(*) count(1) count(字段) 区别
count(*) count(1) count(字段) 区别
count(*)和count(字段)
count(*)和count(字段)使用的目的是不一样的,在必须要使用count(字段)的时候还是要用的,只是在统计表全部行数的时候count(*)就是最佳的选择了。
count(字段)就不一样了,为了去除字段列中包含的NULL行,mysql必须读取该col的每一行的值,然后确认下是否为NULL,然后在进行计数。因此count(*)应该是比count(字段)快的。
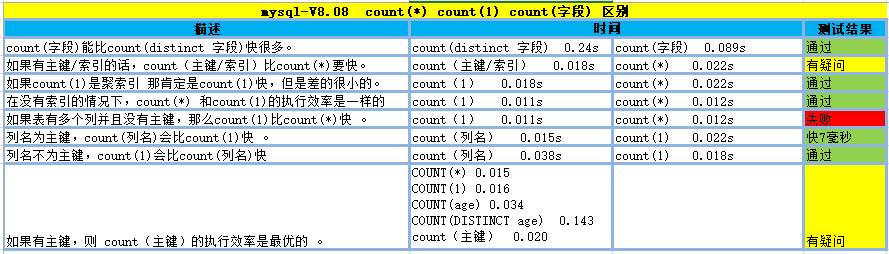
count(字段)能比count(distinct 字段)快很多。
如果有主键/索引的话,count(主键/索引)比count(*)要快。
如果你的表只有一个字段的话那count(*)就是最快的啦。
count(*) count(1) 两者比较
主要还是要count(1)所相对应的数据字段。
如果count(1)是聚索引,id,那肯定是count(1)快。但是差的很小的。
因为count(*)自动会优化指定到那一个字段。所以没必要去count(1),用count(*),sql会帮你完成优化的。
当表的数据量大些时,对表作分析之后,使用count(1)还要比使用count(*)用时多了!
从执行计划来看,count(1)和count(*)的效果是一样的。 但是在表做过分析之后,count(1)会比count(*)的用时少些(1w以内数据量),不过差不了多少。
在没有索引的情况下,count(*) 和count(1)的执行效率是一样的,不存在所谓的单列扫描和多列扫描的问题,因为count(*) 和count(1)都类似获取表的行数。
如果表有多个列并且没有主键,那么count(1) 和count(*)效率差不多 。
count(1) and count(字段) 区别是
(1) count(1) 会统计表中第一列所有的记录数,包含字段为null 的记录。
(2) count(字段) 会统计该字段在表中出现的次数,忽略字段为null 的情况。即不统计字段为null 的记录。
列名为主键,count(列名)会比count(1)快 。
列名不为主键,count(1)会比count(列名)快,因为count(列名)要计判断是否为null,而count(1)类似于获取表的行数。
如果有主键,则 count(主键)的执行效率是最优的 。
如果没有主键/索引的话,count(1)会比count(列名)快。
count(*) count(1) count(字段) 区别的更多相关文章
- 关于数据库优化1——关于count(1),count(*),和count(列名)的区别,和关于表中字段顺序的问题
1.关于count(1),count(*),和count(列名)的区别 相信大家总是在工作中,或者是学习中对于count()的到底怎么用更快.一直有很大的疑问,有的人说count(*)更快,也有的人说 ...
- Count(*), Count(1) 和Count(字段)的区别
1. count(1) and count(*) 当表的数据量大些时,对表作分析之后,使用count(1)还要比使用count(*)用时多了! 从执行计划来看,count(1)和count(*)的 ...
- MySQL学习笔记:count(1)、count(*)、count(字段)的区别
关于数据库中行数统计,无论是MySQL还是Oracle,都有一个函数可以使用,那就是COUNT. 但是,就是这个常用的COUNT函数,却暗藏着很多玄机,尤其是在面试的时候,一不小心就会被虐.不信的话请 ...
- count(1)、count(*)、count(字段)的区别
count(1)和count(*): 都为统计所有记录数,包括null 执行效率上:当数据量1W+时count(*)用时较少,1w以内count(1)用时较少 count(字段): 统计字段列的行数, ...
- COUNT(1)和COUNT(*)区别
项目经常用到count(1),但是和count(*)什么区别? 从下面实验结果来看,Count (*)和Count(1)查询结果是一样的,都包括对NULL的统计,而count(列名) 是不包括NULL ...
- select count(*)和select count(1)的区别 (转)
A 一般情况下,Select Count (*)和Select Count(1)两着返回结果是一样的 假如表沒有主键(Primary key), 那么count(1)比count(*)快, 如果有主键 ...
- count(*)、count(1)和count(列名)的区别
count(*).count(1)和count(列名)的区别 1.执行效果上: l count(*)包括了所有的列,相当于行数,在统计结果的时候,不会忽略列值为NULL l count(1)包 ...
- count(1)、count(*)与count(列名)的执行区别
执行效果: 1. count(1) and count(*) 当表的数据量大些时,对表作分析之后,使用count(1)还要比使用count(*)用时多了! 从执行计划来看,count(1)和coun ...
- count(*)与count(1)、count('xxx')等在使用语法方面的区别
语法方面: 区别就是:没有区别!!! “*”号是通配符: “*”号是通配符 “*”号是通配符 使用"*"号和使用其他数字和任意非字段字符在使用方面没有任何语法错误; 至于效率方面是 ...
随机推荐
- Java 面向对象(九)内部类
一.概述 1.引入 类的成员包括: 1.属性:成员变量2.方法:成员方法3.构造器4.代码块5.内部类:成员内部类 其中 1.2是代表这类事物的特征 其中3.4是初始化类和对象用的 其中5协助 ...
- Java 使用properties配置文件加载配置
一般我们不把数据库的配置信息写死在代码中. 写好代码后,编译.调试,成功后只把输出目录中的东西(jar包..class文件.资源文件等)拷贝到服务器上,由运维来管理.服务器上是没有源文件的(.java ...
- service基础概念和操作
sevice概念介绍 service的实现强烈依赖于kube-DNS组件 新版本k8s安装的是core-DNS 因为每个pod是有生命周期的 为了给客户端访问pod提供一个固定的访问端点 servic ...
- Java黑科技之源:JVMTI完全解读
Java生态中有一些非常规的技术,它们能达到一些特别的效果.这些技术的实现原理不去深究的话一般并不是广为人知.这种技术通常被称为黑科技.而这些黑科技中的绝大部分底层都是通过JVMTI实现的. 形象地说 ...
- python实现文件批量编码转换
起因:大三做日本交换生期间在修一门C语言图像处理的编程课,在配套书籍的网站上下载了sample,但是由于我用的ubuntu18.04系统默认用utf-8编码,而文件源码是Shift_JIS编码,因而文 ...
- k8s管理存储资源
1. Kubernetes 如何管理存储资源 理解volume 首先我们学习 Volume,以及 Kubernetes 如何通过 Volume 为集群中的容器提供存储:然后我们会实践几种常用的 Vol ...
- python3 networkx
一.networkx 1.用于图论和复杂网络 2.官网:http://networkx.github.io/ 3.networkx常常结合numpy等数据处理相关的库一起使用,通过matplot来可视 ...
- SpringBoot项目的测试类
1. package soundsystem; import static org.junit.Assert.*; import org.junit.Test; import org.junit.ru ...
- Elasticsearch 待办
日期格式:yyyy-MM-dd,改为 yyyy-MM-dd HH:mm:ss.SSS:实体类路径:https://github.com/cag2050/spring_boot_elasticsearc ...
- luogu2900:Land Acquisition(斜率优化)
题意:有N块地,每块地给出的宽和高,然后可以分批买,每次买的代价是所选择的地种最宽*最高. 问怎么买,使得代价和最小. 思路:显然,先去掉被包括的情况,即如果一个地的宽和高斗比另外一个小,那么久可以删 ...