P1983 车站分级[拓扑]
题目描述
一条单向的铁路线上,依次有编号为 1, 2, …, n1,2,…,n的 nn个火车站。每个火车站都有一个级别,最低为 11 级。现有若干趟车次在这条线路上行驶,每一趟都满足如下要求:如果这趟车次停靠了火车站 xx,则始发站、终点站之间所有级别大于等于火车站xx 的都必须停靠。(注意:起始站和终点站自然也算作事先已知需要停靠的站点)
例如,下表是55趟车次的运行情况。其中,前44 趟车次均满足要求,而第 5 趟车次由于停靠了 3 号火车站(2级)却未停靠途经的 6号火车站(亦为 2 级)而不满足要求。
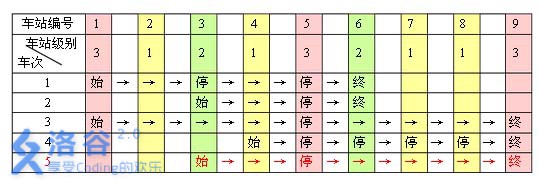
现有 mm 趟车次的运行情况(全部满足要求),试推算这nn 个火车站至少分为几个不同的级别。
解析
这题蛮好的,有助于更深入理解图论(可能吧),更有助于锻炼思维,如果可以的话,希望各位在独立思考出解法之前,能够多思考一下,反正我自己是想了一晚上。
首先分析题目,应该能很快发现每条线路对最终答案造成的影响。即,对于任意一条合法线路,其没有停靠的车站的等级恒小于其停靠过的车站的等级。
讲讲我的思路历程吧:
首先想到一种贪心,我们知道某条线路未停靠的点越少,其对最终答案的影响越小,但是经过尝试会发现这种贪心是有后效性的,不可行。
继而把思路引到图论上,图论的一个极其重要的作用大概就是维护一些抽象的关系以及限制条件,具体而明显地,比如并查集、网络流、差分约束等,其建模的本质是依靠题目中隐含的对象之间的某种关系。
那么这样想的话这题思路还是比较明显的,上面也提到过对于一条线路,其没有停靠的车站的等级恒小于其停靠过的车站的等级。这就是我们需要维护的关系。
这就很容易联想到拓扑排序,其维护的正是这种优先级大小关系。意即DAG中每一拓扑序的节点其等级大小是一致的。
我们感性地理解一下,题目告诉我们数据全部是满足要求的,实际上也就是告诉我们如果按照上面的思路建图,建出来必定是一个DAG(车站大小关系一定不会出现矛盾)。
题目要求最少划分的级别数,那我们只用使相邻拓扑序之间的节点等级差都只为1就可以了。
具体做法就是对于所有数据由等级小的车站向等级大的车站连有向边,再做一个拓扑排序就行了。
参考代码
代码略丑,实现比较简陋,如有疏漏望各位巨佬指出不足!
#include<iostream>
#include<cstdio>
#include<cstring>
#include<cmath>
#include<algorithm>
#include<string>
#include<cstdlib>
#include<queue>
#include<vector>
#define INF 0x3f3f3f3f
#define PI acos(-1.0)
#define N 1010
#define MOD 2520
#define E 1e-12
using namespace std;
inline int read()
{
int f=1,x=0;char c=getchar();
while(c<'0'||c>'9'){if(c=='-')f=-1;c=getchar();}
while(c>='0'&&c<='9'){x=x*10+c-'0';c=getchar();}
return x*f;
}
vector<int> g[N];
int head[N],tot,n,m,ing[N],dat[N][N],c[N];
bool v[N][N];
int main()
{
n=read(),m=read();
for(int i=1;i<=m;++i){
int s=read();dat[i][0]=s;
for(int j=1;j<=s;++j) dat[i][j]=read();//读入数据
}
for(int i=1;i<=m;++i){
int now=dat[i][1]+1;
for(int j=2;j<=dat[i][0];++j){
while(now<dat[i][j]){
for(int k=1;k<=dat[i][0];++k)
//维护节点之间大小关系
if(!v[now][dat[i][k]]) g[now].push_back(dat[i][k]),ing[dat[i][k]]++,v[now][dat[i][k]]=1;
now++;
//注意及时排除已经确定的关系,否则会T
}
now++;
}
}
int ans=0;
queue<int> q;
for(int i=1;i<=n;++i)//拓扑排序
if(ing[i]==0) q.push(i),c[i]=1;
while(q.size()){
int x=q.front();q.pop();
for(int i=0;i<g[x].size();++i){
int y=g[x][i];
if(--ing[y]==0) c[y]=c[x]+1,ans=max(ans,c[y]),q.push(y);
}
}
cout<<ans<<endl;
return 0;
}
写完这题的一点个人感想
对于图论,很多看似无法用图论去做的题,实际上隐藏了许多暗示,可以用图论去维护某些信息,进而求解。个人认为,图论是一个下限很低但是上限挺高的一门学问,其蕴含的骚操作还是很多的。
P1983 车站分级[拓扑]的更多相关文章
- 洛谷 P1983 车站分级 拓扑排序
Code: #include<cstdio> #include<queue> #include<algorithm> #include<cstring> ...
- 洛谷P1983 车站分级
P1983 车站分级 297通过 1.1K提交 题目提供者该用户不存在 标签图论贪心NOIp普及组2013 难度普及/提高- 提交该题 讨论 题解 记录 最新讨论 求帮忙指出问题! 我这么和(diao ...
- 洛谷P1983车站分级
洛谷\(P1983\)车站分级(拓扑排序) 目录 题目描述 题目分析 思路分析 代码实现 题目描述 题目在洛谷\(P1983\)上 题目: 一条单向的铁路线上,依次有编号为 \(1, 2, -, ...
- P1983 车站分级 思维+拓扑排序
很久以前的一道暑假集训的题,忘了补. 感觉就是思维建图,加拓扑排序. 未停靠的火车站,必然比停靠的火车站等级低,就可以以此来建边,此处注意用vis来维护一下,一个起点和终点只建立一条边,因为不这样的话 ...
- 洛谷 P1983 车站分级
题目链接 https://www.luogu.org/problemnew/show/P1983 题目描述 一条单向的铁路线上,依次有编号为 1,2,…,n的 n个火车站.每个火车站都有一个级别,最低 ...
- 洛谷P1983车站分级题解
题目 这个题非常毒瘤,只要还是体现在其思维难度上,因为要停留的车站的等级一定要大于不停留的车站的等级,因此我们可以从不停留的车站向停留的车站进行连边,然后从入度为0的点即不停留的点全都入队,然后拓扑排 ...
- LG1983 「NOIP2013」车站分级 拓扑排序
问题描述 LG1983 题解 考虑建立有向边\((a,b)\),代表\(a\)比\(b\)低级. 于是枚举每一辆车次经过的车站\(x \in [l,r]\),如果不是车辆停靠的车站,则从\(x\)向每 ...
- 【洛谷P1983 车站分级】
这题好像是个蓝题.(不过也确实差不多QwQ)用到了拓扑排序的知识 我们看这些这车站,沿途停过的车站一定比未停的车站的级别高 所以,未停靠的车站向已经停靠的车站连一条边,入度为0的车站级别就看做1 然后 ...
- P1983车站分级
%%%rqy 传送 我们注意到题目中这段话: 既然大于等于x的站都要停,那么不停的站的级别是不是都小于x?(这里讨论在始发站和终点站以内的站(注意这里是个坑)) 我们可以找出每趟车没停的站,向所有停了 ...
随机推荐
- [计算机视觉][神经网络与深度学习]Faster R-CNN配置及其训练教程2
faster-rcnn分为matlab版本和python版本,首先记录弄python版本的环境搭建过程.matlab版本见另一篇:faster-rcnn(testing): ubuntu14.04+c ...
- 最新 淘友天下java校招面经 (含整理过的面试题大全)
从6月到10月,经过4个月努力和坚持,自己有幸拿到了网易雷火.京东.去哪儿.淘友天下等10家互联网公司的校招Offer,因为某些自身原因最终选择了淘友天下.6.7月主要是做系统复习.项目复盘.Leet ...
- LeetCode 556. 下一个更大元素 III(Next Greater Element III)
556. 下一个更大元素 III 556. Next Greater Element III 题目描述 给定一个 32 位正整数 n,你需要找到最小的 32 位整数,其与 n 中存在的位数完全相同,并 ...
- [转帖]UID卡、CUID卡、FUID卡、UFUID卡的区别及写入方式
UID卡.CUID卡.FUID卡.UFUID卡的区别及写入方式 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://bl ...
- Java开发笔记(一百一十七)AWT窗口
前面介绍的所有Java代码,都只能通过日志观察运行情况,就算编译成class文件,也必须在命令行下面运行,这样的程序无疑只能给开发者做调试用,不能拿给一般人使用.因为普通用户早已习惯在窗口界面上操作, ...
- 协议——IIC
I²C即Inter-Integrated Circuit(集成电路总线),它是一种串行通信总线,使用多主从架构,由飞利浦公司在1980年代设计出来的一种简单.双向.二线制总线标准.多用于主机和从机在数 ...
- 【scratch3.0教程】2.1 涂鸦花朵
第4课 涂鸦花朵 1.编程前的准备 在设计一个作品之前,必须先策划一个脚本,然后再根据脚本,收集或制作素材(图案,声音等)接着就可以启动Scratch,汇入角色,舞台,利用搭程序积木的方式编辑程 ...
- Matrix Cells in Distance Order
Matrix Cells in Distance Order We are given a matrix with R rows and C columns has cells with intege ...
- VS2019删除大量空白行或者缩进大量空白行
原文:VS2019删除大量空白行或者缩进大量空白行 问题描述: 在vs编辑器的代码中有时含有大量无用的空白行,我们想删除这些大量空白行或者缩进空白行. 注: 不需要将代码复制在类似word的文本编辑器 ...
- java List分组和排序处理
在一些应用中,需要将List中的对象按某种情况分组或者排序处理.做个小结如下: 1. 如一个List中存放了ProductDoing对象,productDoing对象有rawTypeId 现在要求将r ...