doris: shell invoke .sql script for doris and passing values for parameters in sql script.
1. background
in most cases, we want to execute sql script in doris routinely. using azkaban, to load data,etc.And we want to pass parameters to the sql script file. we can easily handle such situation in hive.
1.1 hive usage:
using -hiveconf: or -hivevar:
shell file:
we want to pass 2 parameters into hive sql script: p_partition_d & p_partition_to_delete: which pass two parameters into hive.sql file using -hivevar {variable_name}={variable_value}
#!/bin/bash
CURRENT_DIR=$(cd `dirname $`; pwd)
echo "CURRENT_DIR:"${CURRENT_DIR} APPLICATION_ROOT_DIR=$(cd ${CURRENT_DIR}/..;pwd)
echo "APPLICATION_ROOT_DIR:"${APPLICATION_ROOT_DIR} source ${APPLICATION_ROOT_DIR}/globle_config.shif [ $# = ]; then
p_partition_d=$(date -d "0 days" +%Y%m%d)
p_partition_to_delete=`date -d "-8 days" +%Y%m%d` fi if [ $# = ]; then
p_partition_d=$(date -d "$1" +%Y%m%d)
p_partition_to_delete=`date -d "$1 -8 days" +%Y%m%d`
fi echo "p_partition_d: "${p_partition_d}
echo "p_partition_to_delete: "${p_partition_to_delete} $HIVE_HOME_BIN/hive -hivevar p_partition_d="${p_partition_d}" \
-hivevar p_partition_to_delete="${p_partition_to_delete}" \
-f ${CURRENT_DIR}/abc_incremental.sql if [ $? != ];then
exit -
fi
the conresponding hive sql script shows as follows:
--handles the inserted data.
-- points_core.tb_acc_rdm_rel is append only, so no update and delete is related!!!!
INSERT OVERWRITE TABLE ods.abc_incremental PARTITION(pt_log_d = '${hivevar:p_partition_d}')
SELECT
id,
last_update_timestamp
FROM staging.staging_abc AS a
WHERE
pt_log_d = '${hivevar:p_partition_d}'; ---------------------------------------------------------------------------------------------------------------------
---------------------------------------------------------------------------------------------------------------------
---------------------------------------------------------------------------------------------------------------------
-- delete hive table partition, the delete file job would be done in shell script,since this table is external table.
ALTER TABLE staging.staging_abc DROP IF EXISTS PARTITION(pt_log_d='${hivevar:p_partition_to_delete}'); ---------------------------------------------------------------------------------------------------------------------
---------------------------------------------------------------------------------------------------------------------
---------------------------------------------------------------------------------------------------------------------
in the hql file ,we reference the passing parameter using ${hivevar:variable_name}.
Note: we can also using hiveconf instead of hivevar, but for each parameter, we should use it as the style the parameter passed in. the difference between hivevar and hiveconf is:
- hivevar: only contains user parameters.
- hiveconf: contains both the hive system variables and user parameters.
1.2 doris requerirements
common requierment like:
- to load data into specified partition which the partition paramerter is to be passed in.
- load data into doris table from external system, such hdfs, etc. In the load statement, the load label paramerter should be pass in to the sql script.
2. solution
2.1 doris common scripts impmentation
I have implemented a common shell script, by calling such shell script, we can pass in parameter values just as the style we used in hive.
the implementation code shows as follows:
globle_config.sh
#!/bin/bash OP_HOME_BIN=/opt/cloudera/parcels/CDH-5.11.-.cdh5.11.1.p0./bin
HIVE_HOME_BIN=/opt/cloudera/parcels/CDH-5.11.-.cdh5.11.1.p0./bin
MYSQL_HOME_BIN=/usr/local/mysql/bin DORIS_HOST=192.168.1.101
DORIS_PORT=
DORIS_USER_NAME=dev_readonly
DORIS_PASSWORD=dev_readonly# # this function provide functionality to copy the provided file
# input parameter:
# $: the working directory
# $: the absolute path of the file to be copyed.
# result: the absolute path the copyed file, the copyed file was located at the working folder.
function func_copy_file() {
if [ $# != ]; then
echo "missing parameter, type in like: repaceContent /opt/ /opt/a.sql"
exit -
fi working_dir=$
source_file=$ # check(s) if the file to be copyed exists.
if [ ! -f $source_file ]; then
echo "file : " $source_file " to be copied does not exist"
exit -
fi # check(s) if the working dir exists.
if [ ! -d "$working_dir" ]; then
echo "the working directory : " $source_file " does not exist"
exit -
fi # checks if the file already exists, $result holds the copied file name(absolute path)
result=${working_dir}/$(generate_datatime_random)
while [ -f $result ]; do
result=${working_dir}/$(generate_datatime_random)
done # copy file
cp ${source_file} ${result} echo ${result}
} # this function provide functionality to generate a ramdom string based on current system timestamp.
# input parameter:
# N/A
# result: ramdom string based on current system timestamp.
function generate_datatime_random() {
# date=$(date -d -0days +%Y%m%d)
# #time random millionsecond to prevent label corruption.
# randnum=$(date +%s%N)
echo $(date -d -0days +%Y%m%d)_$(date +%s%N)
} #replace the specifed string to the target string in the provided file
# $: the absolute path of the file to be replaced.
# $: the source_string for the replacement.
# $: the target string for the replacement.
# result: none
function func_repace_content() {
if [ $# != ]; then
echo "missing parameter, type in like: repaceContent /opt/a.sql @name 'lenmom'"
exit -
fi echo "begin replacement" file_path=$
#be careful of regex expression.
source_content=$
replace_content=$ if [ ! -f $file_path ]; then
echo "file : " $file_path " to be replaced does not exist"
exit -
fi echo "repalce all ["${source_content} "] in file: "${file_path} " to [" ${replace_content}"]"
sed -i "s/${source_content}/${replace_content}/g" $file_path
} # this function provide(s) functionality to execute doris sql script file
# Input parameters:
# $: the absolute path of the .sql file to be executed.
# other paramer(s) are optional, of provided, it's the parameters paire to pass in the script file before execution.
# result: , if execute success; otherwise, -.
function func_execute_doris_sql_script() {
echo "imput parameters: "$@ parameter_number=$#
if [ $parameter_number -lt ]; then
echo "missing parameter, must contain the script file to be executed. other parameters are optional,such as"
echo "func_execute_doris_sql_script /opt/a.sql @name 'lenmom'"
exit -
fi # copy the file to be executed and wait for parameter replacement.
working_dir="$(
cd $(dirname $)
pwd
)"
file_to_execute=$(func_copy_file "${working_dir}" "$1")
if [ $? != ]; then
exit -
fi if [ $parameter_number -gt ]; then
for ((i = ; i <= $parameter_number; i += )); do
case $i in
)
func_repace_content "$file_to_execute" "$2" "$3"
;;
)
func_repace_content "$file_to_execute" "$4" "$5"
;;
)
func_repace_content "$file_to_execute" "$6" "$7"
;;
)
func_repace_content "$file_to_execute" "$8" "$9"
;;
esac
done
fi if [ $? != ]; then
exit -
fi echo "begin to execute script in doris, the content is:"
cat $file_to_execute
echo MYSQL_HOME="$MYSQL_HOME_BIN/mysql"
if [ ! -f $MYSQL_HOME ]; then
# `which is {app_name}` return code is , so we should ignore it.
MYSQL_HOME=$(which is mysql)
# print mysql location in order to override the globle shell return code to ($?)
echo "mysql location is: "$MYSQL_HOME
fi $MYSQL_HOME -h $DORIS_HOST -P $DORIS_PORT -u$DORIS_USER_NAME -p$DORIS_PASSWORD <"$file_to_execute" if [ $? != ]; then
rm -f $file_to_execute
echo execute failed
exit -
else
rm -f $file_to_execute
echo execute success
exit
fi
} # this function provide(s) functionality to load data into doris by execute the specified load sql script file.
# Input parameters:
# $: the absolute path of the .sql file to be executed.ll
# $: the label holder to be replaced.
# result: , if execute success; otherwise, -.
function doris_load_data() {
if [ $# -lt ]; then
echo "missing parameter, type in like: doris_load_data /opt/a.sql label_place_holder"
exit -
fi if [ ! -f $ ]; then
echo "file : " $ " to execute does not exist"
exit -
fi func_execute_doris_sql_script $@ $(generate_datatime_random)
}
2.2 usage
sql script file wich name load_user_label_from_hdfs.sql
LOAD LABEL user_label.fct_usr_label_label_place_holder
( DATA INFILE("hdfs://nameservice1/user/hive/warehouse/usr_label.db/usr_label/*")
INTO TABLE fct_usr_label
COLUMNS TERMINATED BY "\\x01"
FORMAT AS "parquet"
(member_id ,mobile ,corp ,province ,channel_name ,new_usr_type ,gender ,age_type ,last_login_type)
)
WITH BROKER 'doris-hadoop'
(
"dfs.nameservices"="nameservice1",
"dfs.ha.namenodes.nameservice1"="namenodexxx,namenodexxx1",
"dfs.namenode.rpc-address.nameservice1.namenodexxx"="hadoop-datanode06:8020",
"dfs.namenode.rpc-address.nameservice1.namenodexxx1"="hadoop-namenode01:8020",
"dfs.client.failover.proxy.provider"="org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider"
)
PROPERTIES ( "timeout"="", "max_filter_ratio"="");
in this file, the load label has a place holder named label_place_holder of which the value should be passed in by the invoking shell file.
shell file:
user_label_load.sh
#!/bin/bash
CURRENT_DIR=$(cd `dirname $`; pwd)
echo "CURRENT_DIR:"${CURRENT_DIR} APPLICATION_ROOT_DIR=$(cd ${CURRENT_DIR}/..;pwd)
echo "APPLICATION_ROOT_DIR:"${APPLICATION_ROOT_DIR} source ${APPLICATION_ROOT_DIR}/globle_config.sh
#load doris data by calling common shell function
doris_load_data $CURRENT_DIR/load_user_label_from_hdfs.sql "label_place_holder"
or we can also call using function like:
func_execute_doris_sql_script "label_place_holder" $(generate_datatime_random)
if you have mutiple parameter to pass in , just use
func_execute_doris_sql_script {full_path_of_sql_file} "{parameter0_name}" "{parameter0_value}" \
"{parameter1_name}" "{parameter1_value}" \
"{parameter2_name}" "{parameter2_value}" \
......
2.3 execute
in the shell terminal, just execute the shell file would be fine.
sh user_label_load.sh
the shell file include the passed in parameters for invoking the sql script in doris.
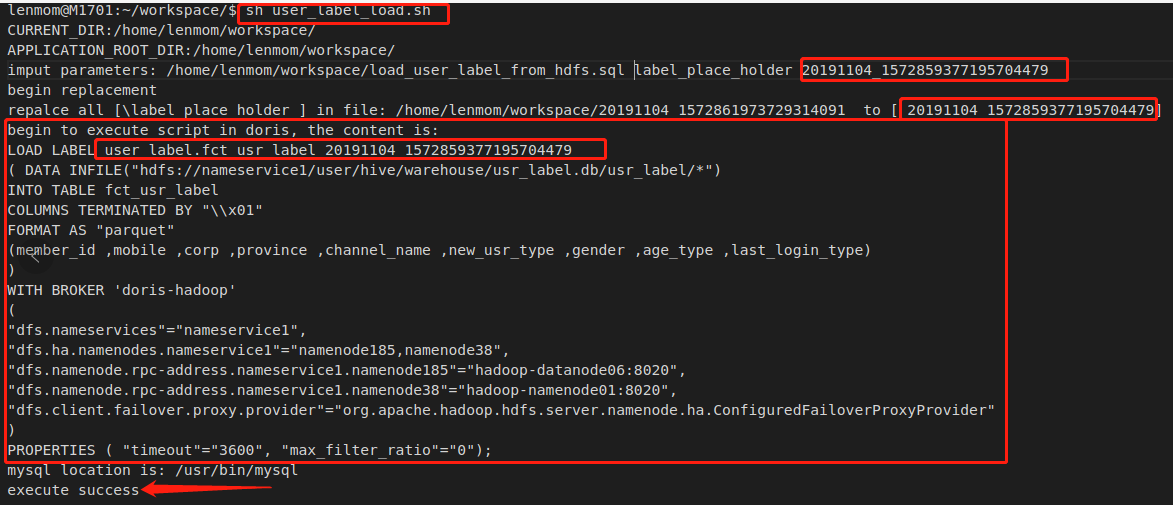
query the load result in doris:

doris: shell invoke .sql script for doris and passing values for parameters in sql script.的更多相关文章
- Bash+R: howto pass parameters from bash script to R(转)
From original post @ http://analyticsblog.mecglobal.it/analytics-tools/bashr/ In the world of data a ...
- Script to Collect Log File Sync Diagnostic Information (lfsdiag.sql) (文档 ID 1064487.1)
the article from :http://m.blog.itpub.net/31393455/viewspace-2130875/ Script to Collect Log File Syn ...
- ASP.NET会员注册登录模块(MD5加密,Parameters防止SQL注入,判断是否注册)
MD5加密,Parameters防止SQL注入: protected void btnLog_Click(object sender, EventArgs e) { //获取验 ...
- SQL Server on Red Hat Enterprise Linux——RHEL上的SQL Server(全截图)
本文从零开始一步一步介绍如何在Red Hat Enterprise Linux上搭建SQL Server 2017,包括安装系统.安装SQL等相关步骤和方法(仅供测试学习之用,基础篇). 一. 创 ...
- 【SQL Server数据迁移】64位的机器:SQL Server中查询ORACLE的数据
从SQL Server中查询ORACLE中的数据,可以在SQL Server中创建到ORACLE的链接服务器来实现的,但是根据32位 .64位的机器和软件, 需要用不同的驱动程序来实现. 在64位的机 ...
- [SDK2.2]SQL Azure (13) Azure的两种关系型数据库服务:SQL Azure与SQL Server VM的不同
<Windows Azure Platform 系列文章目录> 如果熟悉Windows Azure平台的用户不难发现,对于SQL Server数据库来说,微软提供了两种服务,分别是: -W ...
- System.Data.SqlClient.SqlException: 在与 SQL Server 建立连接时出现与网络相关的或特定于实例的错误。未找到或无法访问服务器。请验证实例名称是否正确并且 SQL Server 已配置为允许远程连接。 (provider: SQL Network Interfaces, error: 26 - 定位指定的服务器/实例时出错)
A network-related or instance-specific error occurred while establishing a connection to SQL Server. ...
- 转 一篇关于sql server 三种恢复模式的文章,从sql server 的机制上来写的,感觉很不错,转了
简介 SQL Server中的事务日志无疑是SQL Server中最重要的部分之一.因为SQL SERVER利用事务日志来确保持久性(Durability)和事务回滚(Rollback).从而还部分确 ...
- “java.sql.SQLException: Value '0000-00-00' can not be represented as java.sql.Timestamp”
最近在项目中使用hibernate查询时,总报错“java.sql.SQLException: Value '0000-00-00' can not be represented as java.sq ...
随机推荐
- to_excel
Signature: df.to_excel( ['excel_writer', "sheet_name='Sheet1'", "na_rep=''", 'fl ...
- CEOI2019 / CodeForces 1192B. Dynamic Diameter
题目简述:给定一棵$N \leq 10^5$个节点的树,边上带权,维护以下两个操作: 1. 修改一条边的边权: 2. 询问当前树的直径长度. 解1:code 注意到树的直径有以下性质: 定理:令$\t ...
- 四大网络VGGNet
一.特点 1.对AlexNet改进,在第一个卷积层用了更小的卷积核和stride 2.多尺度训练(训练和测试时,采用整张图的不同尺度) 由此,VGG结构简单,提取特征能力强,应用场景广泛 由单尺度测试 ...
- kafka2.12 集群搭建
前提: 1.下载 kafka http://kafka.apache.org/downloads 2.下载配置zookeeper http://www.cnblogs.com/eggplantpro/ ...
- Deepgreen & Greenplum DBA小白普及课之三
Deepgreen & Greenplum DBA小白普及课之三(备份问题解答) 不积跬步无以至千里,要想成为一名合格的数据库管理员,首先应该具备扎实的基础知识及问题处理能力.本文参考Pivo ...
- Cogs 452. Nim游戏!(博弈)
Nim游戏! ★ 输入文件:nim!.in 输出文件:nim!.out 简单对比 时间限制:1 s 内存限制:128 MB 甲,乙两个人玩Nim取石子游戏. nim游戏的规则是这样的:地上有n堆石子( ...
- 64位内核第三讲,Windbg的使用.以及命令
目录 一丶驱动的调试. 1.线程 2.断点 3.内存查看命令 4.修改内存命令 5.栈相关操作命令 6.进程线程命令(内核命令) 一丶驱动的调试. 编写驱动免不了调试.所以这里介绍一下WinDbg的常 ...
- Codeforces 876E National Property ——(2-SAT)
在这题上不是标准的“a或b”这样的语句,因此需要进行一些转化来进行建边.同时在这题上点数较多,用lrj大白书上的做法会T,因此采用求强连通分量的方法来求解(对一个点,如果其拓扑序大于其为真的那个点,则 ...
- 微信小程序 图片设置为圆形
要图片圆形显示,需要设置border-radius:50%,还要设置overflow:hidden,具体如下: Tip:user-avatar是图片控件的class .user-avatar { wi ...
- reverse啥时候可以用
在做历史搜索记录的时候,当你想把最新的数据放到前面,可以用到,其实就是一个数组的反转. let array=[ '周小姐','好可爱的' ] var box=array.reverse() conso ...