BERT安装与使用
环境:
python 3.5
tensorflow 1.12.1
bert-serving-server 1.9.1
bert-serving-cline 1.9.1
官网上说要保证Python >= 3.5 with Tensorflow >= 1.10
1.安装BERT服务端和客户端
pip install bert-serving-server # server
pip install bert-serving-client # client, independent of `bert-serving-server`
2.下载预训练的中文BERT模型
根据 NLP 任务的类型和规模不同,Google 提供了多种预训练模型供选择:
- BERT-Base, Chinese: 简繁体中文, 12-layer, 768-hidden, 12-heads, 110M parameters【我下载的是这个】
- BERT-Base, Multilingual Cased: 多语言(104 种), 12-layer, 768-hidden, 12-heads, 110M parameters
- BERT-Base, Uncased: 英文不区分大小写(全部转为小写), 12-layer, 768-hidden, 12-heads, 110M parameters
- BERT-Base, Cased: 英文区分大小写, 12-layer, 768-hidden, 12-heads , 110M parameters
- 中文效果更好的哈工大版 BERT:Chinese-BERT-wwm
下载成功后,解压
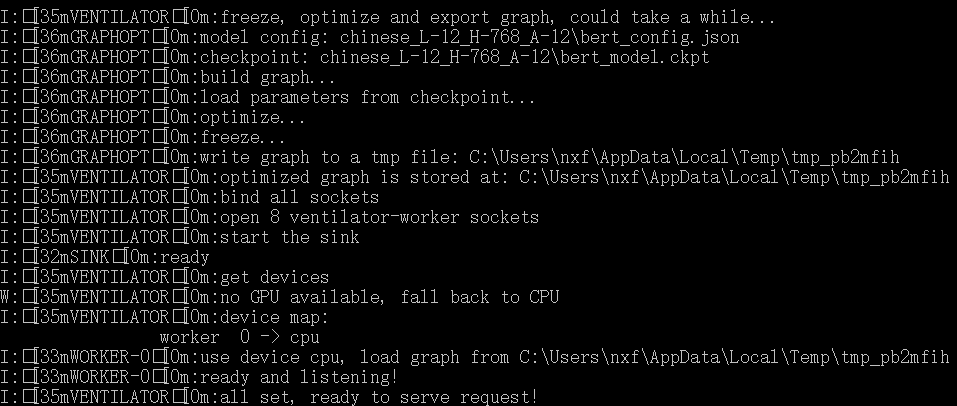
3.启动BERT服务端
bert-serving-start -model_dir chinese_L-12_H-768_A-12 -num_worker=1
-model_dir 是预训练模型的路径,-num_worker 是线程数,表示同时可以处理多少个并发请求
BERT 模型对内存有比较大的要求,如果启动时一直卡在 load graph from model_dir 可以将 num_worker 设置为 1 或者加大机器内存。
4. 在客户端获取句向量
from bert_serving.client import BertClient
bc = BertClient(ip='localhost',check_version=False, check_length=False)
vec = bc.encode(['努力写大论文中'])
print(vec) # 维度(1,768)
vec 是一个 numpy.ndarray ,它的每一行是一个固定长度的句子向量,长度由输入句子的最大长度决定。如果要指定长度,可以在启动服务使用 max_seq_len 参数,过长的句子会被从右端截断。

在计算中文向量时,可以直接输入整个句子不需要提前分词。因为 Chinese-BERT 中,语料是以字为单位处理的,因此对于中文语料来说输出的是字向量。
举个例子,当用户输入:
bc.encode(['你好吗?'])
实际上,BERT 模型的输入是:
tokens: [CLS] 你 好 么 ? [SEP]
input_ids: 101 872 1962 720 8043 102 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
input_mask: 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
5.获取词向量
启动服务时将参数 pooling_strategy 设置为 None :
bert-serving-start -pooling_strategy NONE -model_dir /root/zhihu/bert/chinese_L-12_H-768_A-12/
这时的返回是语料中每个 token 对应 embedding 的矩阵
bc = BertClient()
vec = bc.encode(['hey you', 'whats up?']) vec # [2, 25, 768]
vec[0] # [1, 25, 768], sentence embeddings for `hey you`
vec[0][0] # [1, 1, 768], word embedding for `[CLS]`
vec[0][1] # [1, 1, 768], word embedding for `hey`
vec[0][2] # [1, 1, 768], word embedding for `you`
vec[0][3] # [1, 1, 768], word embedding for `[SEP]`
vec[0][4] # [1, 1, 768], word embedding for padding symbol
vec[0][25] # error, out of index!

参考文献:
【1】bert-as-service三行代码使用bert模型 - accumulate_zhang的博客 - CSDN博客
【2】快速使用 BERT 生成词向量:bert-as-service - P01son的博客 - CSDN博客
BERT安装与使用的更多相关文章
- win10 + 独显 + Anaconda3 + tensorflow_gpu1.13 安装教程(跑bert模型)
这里面有很多坑,最大的坑是发现各方面都装好了结果报错 Loaded runtime CuDNN library: 7.3.1 but source was compiled with: 7.4.1, ...
- java-1-java开发环境安装及配置-绝对权威
1,下载安装jdk1.8u45 http://www.oracle.com/technetwork/java/javase/downloads/index-jsp-138363.html 一般安装目录 ...
- 源代码安装-非ROOT用户安装软件的方法
0. 前言 如果你没有sudo权限,则很多程序是无法使用别人编译好的文件安装的. 还有时候,没有对应你的主机配置的安装包,这时候需要我们自己下载最原始的源代码,然后进行编译安装. 这样安装的程序 ...
- Net-SNMP V3协议 安装配置笔记(CentOS 6.3/5.6)
注意:snmp V3,需要需要关闭selinux和防火墙: 关闭selinux方法: #vi /etc/selinux/config 将文件中的SELINUX="" 为 disab ...
- 学习笔记44—Linux下安装freesurfer
第一步:安装ubuntu (略过) 第二步:下载freesurfer:从freesurfer的官方网站上下载:http://surfer.nmr.mgh.harvard.edu/fswiki/Down ...
- Net-SNMP(V3协议)安装配置笔记(CentOS 5.2)(转)
原出处:http://blog.ihipop.info/2010/03/722.html 为了这颗仙人掌(cacti),我必须先部署(Net-SNMP), 同时我为了安全因素,也为了简便考虑,决定采用 ...
- 基于Bert的文本情感分类
详细代码已上传到github: click me Abstract: Sentiment classification is the process of analyzing and reaso ...
- 使用modelarts部署bert命名实体识别模型
模型部署介绍 当我们通过深度学习完成模型训练后,有时希望能将模型落地于生产,能开发API接口被终端调用,这就涉及了模型的部署工作.Modelarts支持对tensorflow,mxnet,pytorc ...
- 使用bert进行情感分类
2018年google推出了bert模型,这个模型的性能要远超于以前所使用的模型,总的来说就是很牛.但是训练bert模型是异常昂贵的,对于一般人来说并不需要自己单独训练bert,只需要加载预训练模型, ...
随机推荐
- python 异常try/except语句
异常模式的写法 try: 执行正常的模块 except X: 执行异常X的代码 except: 其他的异常执行模块except 必须在except X之后 else: 没有异常,则会执行完try,而后 ...
- pymongo 笔记(转)
1. 安装MongoDB并启动服务,安装PyMongo2. 连接MongoDB,并指定连接数据库.集合 import pymongo client = pymongo.MongoClient(host ...
- day71_10_16多表断关联
---恢复内容开始--- 本次环境: 配置settings INSTALLED_APPS = [ # ... 'rest_framework', ] DATABASES = { 'default': ...
- node.js是用来做什么的?这是我看到最好的解释了
一种JavaScript的运行环境,能够使得JavaScript脱离浏览器运行. 参考链接:https://www.cnblogs.com/suhaihong/p/6598308.html https ...
- LeetCode236. 二叉树的最近公共祖先
* @lc app=leetcode.cn id=236 lang=cpp * * [236] 二叉树的最近公共祖先 * * https://leetcode-cn.com/problems/ ...
- 药店商品销量分析(python)
一.数据分析的步骤 二.提出问题 分析药店商品销售情况 1)月均消费次数 2)月均消费金额 3)客单价 4)消费趋势 5)热销商品.滞销商品 三.理解数据 销售数据源为excel文件 字段的含义: 共 ...
- 怎样用cmd脚本添加Qt的环境变量
在网上遍历了很久,终于找到了一个简单且令人满意的答案: 定位到PyQt5发布文件所需的plugins的位置: 新建一个名为“设置环境变量”的cmd脚本,在里面写上: wmic ENVIRONMENT ...
- [探究] dsu on tree,一类树上离线问题的做法
dsu on tree. \(\rm 0x01\) 前言\(\&\)技术分析 \(\bold{dsu~on~tree}\),中文别称"树上启发式合并"(虽然我并不承认这种称 ...
- QPushButton 一组中凸显选中的一个,且只能选中一个。
QButtonGroup * buttonGroup = new QButtonGroup(this); buttonGroup->setExclusive(true); ui->push ...
- ItelliJ Idea 2019提交TFVC变更,系统提示Validation must be performed before checking in
问题描述 全新安装的Idea 2019,从Azure DevOps Server 2019 (原名TFS)的TFVC代码库下载文件,正常. 修改代码后,签入,系统提示"Validation ...