python 学习之 基础篇二 字符编码
声明: 博文参考1:字符编码发展历程(ASCII,Unicode,UTF-8)
博文参考2:Python常见字符编码间的转换
(1)为什么要用字符编码
早期的计算机使用的是通电与否的特性的真空管,如果通电就是1,没有通电就是0,后来沿用至今我们称这种只有0/1的环境为
二进制制,英文称为binary。但是二进制数据(0/1)怎么能表示我们所熟知的英文,数字,字符,汉字呢?所以就有了各种编码,因
为开始计算机只在美国用。八位的字节一共可以组合出256(2的8次方)种不同的状态。(可以涵盖美国人使用的字母,数字和特殊符
号。)所以他们把其中的编号从0开始的32种状态分别规定了特殊的用途,一但终端、打印机遇上约定好的这些字节被传过来时,
就要做一些约定的动作:
遇上0×10, 终端就换行;
遇上0×07, 终端就向人们嘟嘟叫;
遇上0x1b, 打印机就打印反白的字,或者终端就用彩色显示字母。
他们看到这样很好,于是就把这些0×20以下的字节状态称为”控制码”。他们又把所有的空 格、标点符号、数字、大小写字母分
别用连续的字节状态表示,一直编到了第127号,这样计算机就可以用不同字节来存储英语的文字了。大家看到这样,都感觉很好
,于是大家都把这个方案叫做 ANSI 的”Ascii”编码(American Standard Code for Information Interchange,美国信息互换标
准代码)。当时世界上所有的计算机都用同样的ASCII方案来保存英文文字。
后来,就像建造巴比伦塔一样,世界各地都开始使用计算机,但是很多国家用的不是英文,他们的字母里有许多是ASCII里没
有的,为了可以在计算机保存他们的文字,他们决定采用 127号之后的空位来表示这些新的字母、符号,还加入了很多画表格时需
要用下到的横线、竖线、交叉等形状,一直把序号编到了最后一个状态255。从128 到255这一页的字符集被称”扩展字符集“。从此
之后,贪婪的人类再没有新的状态可以用了,美帝国主义可能没有想到还有第三世界国家的人们也希望可以用到计算机吧!
等中国人们得到计算机时,已经没有可以利用的字节状态来表示汉字,况且有6000多个常用汉字需要保存呢。但是这难不倒智
慧的中国人民,我们不客气地把那些127号之后的奇异符号们直接取消掉, 规定:一个小于127的字符的意义与原来相同,但两个大
于127的字符连在一起时,就表示一个汉字,前面的一个字节(他称之为高字节)从0xA1用到0xF7,后面一个字节(低字节)从
0xA1到0xFE,这样我们就可以组合出大约7000多个简体汉字了。在这些编码里,我们还把数学符号、罗马希腊的字母、日文的假
名们都编进去了,连在 ASCII 里本来就有的数字、标点、字母都统统重新编了两个字节长的编码,这就是常说的”全角”字符,而原
来在127号以下的那些就叫”半角”字符了。中国人民看到这样很不错,于是就把这种汉字方案叫做“GB2312“。GB2312 是对 ASCII
的中文扩展。
因为当时各个国家都像中国这样搞出一套自己的编码标准,结果互相之间谁也不懂谁的编码,谁也不支持别人的编码,连大陆
和台湾这样只相隔了150海里,使用着同一种语言的兄弟地区,也分别采用了不同的 DBCS 编码方案——当时的中国人想让电脑显
示汉字,就必须装上一个”汉字系统”,专门用来处理汉字的显示、输入的问题,像是那个台湾的愚昧封建人士写的算命程序就必须
加装另一套支持 BIG5 编码的什么”倚天汉字系统”才可以用,装错了字符系统,显示就会乱了套!这怎么办?而且世界民族之林中
还有那些一时用不上电脑的穷苦人民,他们的文字又怎么办?真是计算机的巴比伦塔命题啊!
正在这时,大天使加百列及时出现了——一个叫 ISO(国际标谁化组织)的国际组织决定着手解决这个问题。他们采用的方法
很简单:废了所有的地区性编码方案,重新搞一个包括了地球上所有文化、所有字母和符号的编码!他们打算叫它”Universal
Multiple-Octet Coded Character Set”,简称 UCS, 俗称“unicode“。
unicode开始制订时,计算机的存储器容量极大地发展了,空间再也不成为问题了。于是 ISO 就直接规定必须用两个字节,也
就是16位来统一表示所有的字符,对于ASCII里的那些“半角”字符,unicode包持其原编码不变,只是将其长度由原来的8位扩展为
16位,而其他文化和语言的字符则全部重新统一编码。由于”半角”英文符号只需要用到低8位,所以其高8位永远是0,因此这种大
气的方案在保存英文文本时会多浪费一倍的空间。
这时候,从旧社会里走过来的程序员开始发现一个奇怪的现象:他们的 strlen 函数靠不住了,一个汉字不再是相当于两个字符
了,而是一个!是的,从unicode开始,无论是半角的英文字母,还是全角的汉字,它们都是统一的”一个字符“!同时,也都是统一
的”两个字节“,请注意”字符”和”字节”两个术语的不同,“字节”是一个8位的物理存贮单元,而“字符”则是一个文化相关的符号。在
unicode中,一个字符就是两个字节。一个汉字算两个英文字符的时代已经快过去了。
unicode同样也不完美,这里就有两个的问题,一个是,如何才能区别unicode和ascii?计算机怎么知道三个字节表示一个符号
,而不是分别表示三个符号呢?第二个问题是,我们已经知道,英文字母只用一个字节表示就够了,如果unicode统一规定,每个
符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是0,这对于存储空间来说是极大的浪费,文本文件的大
小会因此大出二三倍,这是难以接受的。
unicode在很长一段时间内无法推广,直到互联网的出现,为解决unicode如何在网络上传输的问题,于是面向传输的众多 UTF
(UCSTransfer Format)标准出现了,顾名思义,UTF-8就是每次8个位传输数据,而UTF-16就是每次16个位。UTF-8就是在互
联网上使用最广的一种unicode的实现方式,这是为传输而设计的编码,并使编码无国界,这样就可以显示全世界上所有文化的字
符了。UTF-8最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节
长度,当字符在ASCII码的范围时,就用一个字节表示,保留了ASCII字符一个字节的编码做为它的一部分,注意的是unicode一个
中文字符占2个字节,而UTF-8一个中文字符占3个字节)。
从unicode到utf-8并不是直接的对应,而是要过一些算法和规则来转换。
7 7 E 5
0111 0111 1110 0101 二进制的77E5
--------------------------
0111 011111 100101 按规则重组后的二进制77E5
1110XXXX 10XXXXXX 10XXXXXX 套用UTF-8模版(固定化模版)
11100111 10011111 10100101 代入模版
E 7 9 F A 5
最后简单总结一下:
中国人民通过对 ASCII 编码的中文扩充改造,产生了 GB2312 编码,可以表示6000多个常用汉字。
汉字实在是太多了,包括繁体和各种字符,于是产生了 GBK 编码,它包括了 GB2312 中的编码,同时扩充了很多。
中国是个多民族国家,各个民族几乎都有自己独立的语言系统,为了表示那些字符,继续把 GBK 编码扩充为 GB18030 编码。
每个国家都像中国一样,把自己的语言编码,于是出现了各种各样的编码,如果你不安装相应的编码,就无法解释相应编码想
表达的内容。
终于,有个叫 ISO 的组织看不下去了。他们一起创造了一种编码 UNICODE ,这种编码非常大,大到可以容纳世界上任何一
个文字和标志。所以只要电脑上有 UNICODE 这种编码系统,无论是全球哪种文字,只需要保存文件的时候,保存成 UNICODE 编
码就可以被其他电脑正常解释。
UNICODE 在网络传输中,出现了两个标准 UTF-8 和 UTF-16,分别每次传输 8个位和 16个位。于是就会有人产生疑问,
UTF-8 既然能保存那么多文字、符号,为什么国内还有这么多使用 GBK 等编码的人?因为 UTF-8 等编码体积比较大,占电脑空间
比较多,如果面向的使用人群绝大部分都是中国人,用 GBK 等编码也可以。
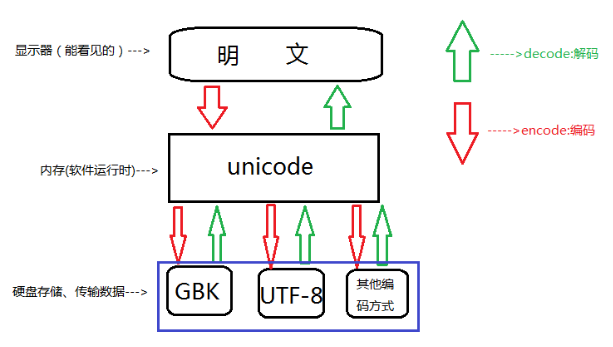
(2)字符在硬盘上的存储
首先要明确的一点就是,无论以什么编码在内存里显示字符,存到硬盘上都是2进制(0b是说明这段数字是二进制,0x表示是
16进制。0x几乎所有的编译器都支持,而支持0b的并不多)。理解这一点很重要。
比如:
ascii编码(美国):
l 0b1101100
o 0b1101111
v 0b1110110
e 0b1100101
GBK编码(中国):
老 0b11000000 0b11001111
男 0b11000100 0b11010000
孩 0b10111010 0b10100010
还要注意的一点是:存到硬盘上时是以何种编码存的,再从硬盘上读出来时,就必须以何种编码读(开头声明或转换),要不然就乱了。
(3)编码转换
虽然有了unicode and utf-8 ,但是由于历史问题,各个国家依然在大量使用自己的编码,比如中国的windows,默认编码依然
是gbk,而不是utf-8。
基于此,如果中国的软件出口到美国,在美国人的电脑上就会显示乱码,因为他们没有gbk编码。
所以该怎么办呢?
还记得我们讲unicode其中一个功能是其包含了跟全球所有国家编码的映射关系,这时就派上用场了。
无论你以什么编码存储的数据,只要你的软件在把数据从硬盘读到内存里,转成unicode来显示,就可以了。
由于所有的系统、编程语言都默认支持unicode,那你的gbk软件放到美国电脑上,加载到内存里,变成了unicode,
中文就可以正常展示啦
Python3执行过程
1、解释器找到代码文件,把代码字符串按文件头定义的编码加载到内存,转成unicode
2、把代码字符串按照语法规则进行解释
3、所有的变量字符都会以unicode编码声明
在py3上把你的代码以utf-8编写,保存,然后在windows上执行。
发现可以正常执行!
其实utf-8编码之所以能在windows gbk的终端下显示正常,是因为到了内存里python解释器把utf-8转成了unicode , 但是这
只是python3, 并不是所有的编程语言在内存里默认编码都是unicode,比如万恶的python2 就不是,它是ASCII(龟叔当初设计
Python时的一点缺陷),想写中文,就必须声明文件头的coding为gbk or utf-8, 声明之后,python2解释器仅以文件头声明的
编码去解释你的代码,加载到内存后,并不会主动帮你转为unicode,也就是说,你的文件编码是utf-8,加载到内存里,你的变
量字符串就也是utf-8, 这意味着什么?意味着,你以utf-8编码的文件,在windows是乱码。
其实乱是正常的,不乱才不正常,因为只有2种情况,你的windows上显示才不会乱。
1、字符串以GBK格式显示
2、字符串是unicode编码
Python2并不会自动的把文件编码转为unicode存在内存里。
所以我们只有手动转,Python3 自动把文件编码转为unicode必定是调用了什么方法,这个方法就是,decode(解码) 和encode
(编码)
方法如下:
UTF-/GBK --> decode 解码 --> Unicode
Unicode --> encode 编码 --> GBK / UTF-
例如:
#!/usr/bin/env python3
#-*- coding:utf- -*-
# write by congcong s = '匆匆'
print(s)
s1 = s.decode("utf-8") # utf- 转成 Unicode,decode(解码)需要注明当前编码格式
print(s1,type(s1)) s2 = s1.encode("gbk") # unicode 转成 gbk,encode(编码)需要注明生成的编码格式
print(s2,type(s2)) s3 = s1.encode("utf-8") # unicode 转成 utf-,encode(编码)注明生成的编码格式
print(s3,type(s3))
文件在 Python2 和 Python3 环境下运行结果的区别,如下所示:
#coding:utf-
s = "你好,中国!"
print(s) # Python2输出乱码,Python3正常输出
print(type(s)) # 均输出 <type 'str'> #解码成unicode
s1 = s.decode("utf-8")
print(s1) # Python2中输出 “你好,中国!”,Python3显示'str'对象没有属性'decode'
print(type(s1)) # Python2中输出 <type 'unicode'> Python3中输出 <class 'str'> #编码成gbk 或 utf-
s2 = s1.encode('gbk')
print(s2) # Python2中输出 “你好,中国!”
print(type(s2)) # Python2中输出 <type 'str'>
s3 = s1.encode('utf-8')
print(s3) # Python2输出乱码,
print(type(s3)) # 输出 <type 'str'>
编码相互转换的规则如下:
(4)如何验证编码转对了呢?
1、查看数据类型,python 2 里有专门的unicode 类型
2、查看unicode编码映射表
unicode字符是有专门的unicode类型来判断的,但是utf-8,gbk编码的字符都是str,你如果分辨出来的当前的字符串数据是
何种编码的呢?
有人说可以通过字节长度判断,因为utf-8一个中文占3字节,gbk一个占2字节。
看输出的字节个数,也能大体判断是什么类型。精确的验证一个字符的编码呢,就是拿这些16进制的数跟编码表里去匹配。
关于 Unicode 与 GBK 等编码对应关系(以中文“路”为例):

完整的编码对应表可到这个网站下载:unicode与gbk的映射表 http://www.unicode.org/charts/
(5)Python byte类型
把8个二进制一组称为一个byte,用16进制来表示。为的就是让人们看起来更可读。我们称之为bytes类型,即字节类型。
python2的字符串其实更应该称为字节串。 通过存储方式就能看出来, 但python2里还有一个类型是bytes呀,难道又叫bytes
又叫字符串?
嗯 ,是的,在python2里,bytes == str , 其实就是一回事。
除此之外呢, python2里还有个单独的类型是unicode , 把字符串解码后,就会变成unicode。
>>> s
'\xe8\xb7\xaf\xe9\xa3\x9e' #utf-
>>> s.decode('utf-8')
u'\u8def\u98de' #unicode 在unicode编码表里对应的位置
>>> print(s.decode('utf-8'))
路飞 #unicode 格式的字符
Python2的默认编码是ASCII码,当后来大家对支持汉字、日文、法语等语言的呼声越来越高时,Python于是准备引入
unicode,但若直接把默认编码改成unicode的话是不现实的, 因为很多软件就是基于之前的默认编码ASCII开发的,编码一换
,那些软件的编码就都乱了。所以Python 2就直接搞了一个新的字符类型,就叫unicode类型,比如你想让你的中文在全球
所有电脑上正常显示,在内存里就得把字符串存成unicode类型。
>>> s = "路飞"
>>> s
'\xe8\xb7\xaf\xe9\xa3\x9e'
>>> s2 = s.decode("utf-8")
>>> s2
u'\u8def\u98de'
>>> type(s2)
<type 'unicode'>
注意:
Python3 除了把字符串的编码改成了unicode, 还把str 和bytes 做了明确区分, str 就是unicode格式的字符, bytes就是单
纯二进制啦。
在py3里看字符,必须得是unicode编码,其它编码一律按bytes格式展示。
Python只要出现各种编码问题,无非是哪里的编码设置出错了
常见编码错误的原因有以下这些:
Python解释器的默认编码
Python源文件文件编码
Terminal使用的编码
操作系统的语言设置
最后总结一下:
python3:文件默认编码是utf-8 , 字符串编码是 unicode以utf-8 或者 gbk等编码的代码,加载到内存,会自动转为unicode
正常显示。
python2:文件默认编码是ascii , 字符串编码也是 ascii , 如果文件头声明了是gbk,那字符串编码就是gbk。以utf-8 或者 gbk
等编码的代码,加载到内存,并不会转为unicode,编码仍然是utf-8或者gbk等编码。
python 学习之 基础篇二 字符编码的更多相关文章
- Python学习笔记基础篇——总览
Python初识与简介[开篇] Python学习笔记——基础篇[第一周]——变量与赋值.用户交互.条件判断.循环控制.数据类型.文本操作 Python学习笔记——基础篇[第二周]——解释器.字符串.列 ...
- Python 基础篇:字符编码、函数
字符编码 在python2默认编码是ASCII, python3里默认是utf-8 unicode 分为 utf-32(占4个字节),utf-16(占两个字节),utf-8(占1-4个字节), so ...
- Python学习笔记——基础篇【第一周】——变量与赋值、用户交互、条件判断、循环控制、数据类型、文本操作
目录 Python第一周笔记 1.学习Python目的 2.Python简史介绍 3.Python3特性 4.Hello World程序 5.变量与赋值 6.用户交互 7.条件判断与缩进 8.循环控制 ...
- python学习之路 三:字符编码
本节重点 彻底掌握字符编码之前的转换关系 掌握 python2 vs python3 上编码的区别 掌握 python2 和python3 上bytes,str 的区别 补充知识点:三元运算 三元运 ...
- Python学习笔记——基础篇【第五周】——模块
模块,用一砣代码实现了某个功能的代码集合. 类似于函数式编程和面向过程编程,函数式编程则完成一个功能,其他代码用来调用即可,提供了代码的重用性和代码间的耦合.而对于一个复杂的功能来,可能需要多个函数才 ...
- python学习笔记-基础、语句、编码、迭代器
#python的优缺点优点:Python简单优雅,尽量写容易看明白的代码,尽量写少的代码.缺点:第一个缺点就是运行速度慢,和C程序相比非常慢,因为Python是解释型语言,你的代码在执行时会一行一行地 ...
- python学习(2)关于字符编码
关于字符编码的学习内容笔记如下: 1.计算机只能用0和1来进行记录和存储.计算机是二进制. 2.ASCII(American Standard Code for Information Interch ...
- python学习第二节 数据类型、字符编码、文件处理
标准数据类型 Python3 中有六个标准的数据类型: Number(数字) String(字符串) List(列表) Tuple(元组) Sets(集合) Dictionary(字典) 数字 #整型 ...
- Python学习笔记——基础篇【第五周】——常用模块学习
模块介绍 本节大纲: 模块介绍 time &datetime模块 (时间模块) random (随机数模块) os (系统交互模块) sys shutil (文件拷贝模块) j ...
随机推荐
- STM32F4 串口IAP程序要点
1. IAP(bootloader)程序 1.1 内部Flash地址分配 /* Start of the Flash address */ #define STM32_FLASH_BASE 0x080 ...
- INPUT输入子系统【转】
转自:https://www.cnblogs.com/deng-tao/p/6094049.html 1.Linux系统支持的输入设备繁多,例如键盘.鼠标.触摸屏.手柄或者是一些输入设备像体感输入等等 ...
- 代码审计-数组返回NULL绕过
<?php $flag = "flag"; if (isset ($_GET['password'])) { if (ereg ("^[a-zA-Z0-9]+$&q ...
- web权限验证方法说明[转载]
前言 本文将会从最基本的一种web权限验证说起,即HTTP Basic authentication,然后是基于cookies和tokens的权限验证,最后则是signatures和一次性密码. HT ...
- 添加ssh密钥
直接运行ssh-keygen,可以不输入密码 $ ssh-keygen Generating public/private rsa key pair. Enter file in which to s ...
- day30_8.9 操作系统与并发编程
一.操作系统相关 1.手工操作 1946年第一台计算机诞生--20世纪50年代中期,计算机工作还在采用手工操作方式.此时还没有操作系统的概念. 这时候的计算机是由人为将穿孔的纸带装入输入机,控制台获取 ...
- 莫烦TensorFlow_09 MNIST例子
import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data mnist = input_dat ...
- zzDeep Learning Papers Translation(CV)
Deep Learning Papers Translation(CV) Image Classification AlexNetImageNet Classification with Deep C ...
- zz2019年主动学习有哪些进展?答案在这三篇论文里
2019年主动学习有哪些进展?答案在这三篇论文里 目前推广应用的机器学习方法或模型主要解决分类问题,即给定一组数据(文本.图像.视频等),判断数据类别或将同类数据归类等,训练过程依赖于已标注类别的训练 ...
- JDOJ 1928: 排队买票
JDOJ 1928: 排队买票 JDOJ传送门 Description 一场演唱会即将举行.现有n个歌迷排队买票,一个人买一张,而售票处规定,一个人每次最多只能买两张票.假设第i位歌迷买一张票需要时间 ...