PHP 之Mysql优化
一、建立索引
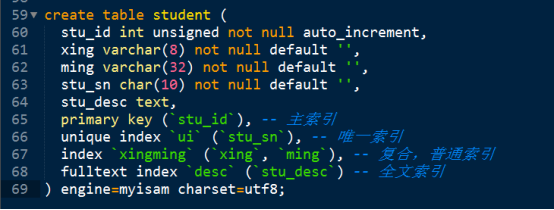
普通索引 index: 对关键字没有要求。
唯一索引 unique index: 要求关键字不能重复。同时增加唯一约束。
主键索引 primary key: 要求关键字不能重复,也不能为NULL。同时增加主键约束。
全文索引 fulltext key: 关键字的来源不是所有字段的数据,而是从字段中提取的特别关键词。
索引的管理:
- 建表时
- 更新表结构

1、前缀索引
建立前缀索引的语法:
alter table test add KEY (name(5));
name一定是字符类型(索引字段),5为长度
那好,如何确定取前面几个字符呢?显然,这个场景是一个观察的结果,也就是说,必须要有一定量的实际数据,我们才能分析出其规律,也就是说这个索引是在后期优化得来的,前期没必要建立。
- 计算不重复的概率:
select COUNT(DISTINCT name) / COUNT(*) as rate from test;
- 找出接近rate的一个n(试出最合理的n)
select COUNT(DISTINCT LEFT(name, 3)) / COUNT() as rate3 from test;
select COUNT(DISTINCT LEFT(name, 5)) / COUNT() as rate5 from test;
select COUNT(DISTINCT LEFT(name, 7)) / COUNT() as rate7 from test;
select COUNT(DISTINCT LEFT(name, 9)) / COUNT() as rate9 from test;
select COUNT(DISTINCT LEFT(name, 11)) / COUNT() as rate11 from test;
select COUNT(DISTINCT LEFT(name, 15)) / COUNT() as rate15 from test;
select COUNT(DISTINCT LEFT(name, 20)) / COUNT(*) as rate20 from test;
…
2、全文索引
该类型的索引特殊在:关键字的创建上。为了解决 like ‘%keyword%’这类查询的匹配问题。
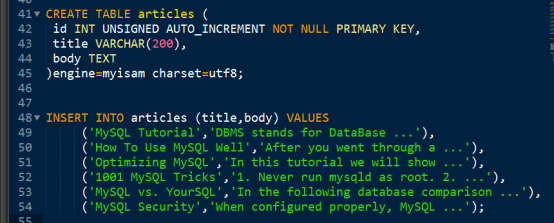
查询 标题或者内容包含 database 关键字的记录。
形成的SQL如下:
Select * from articles where title like ‘%database%’ or body like ‘%database%’;
此时需要建立全文索引

直接使用上面的SQL:
需要使用特殊的全文索引匹配语法才可以生效:
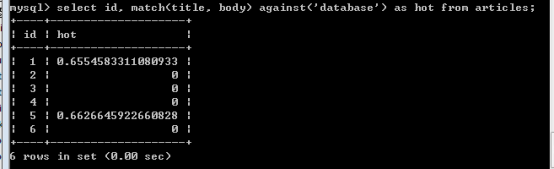
Match() against();

注意:mysql提供的全文索引不能对中文起作用,可以采用Sphinx索引引擎。
Match() against() ,返回的关键字的匹配度(关键字与记录的关联程度)。
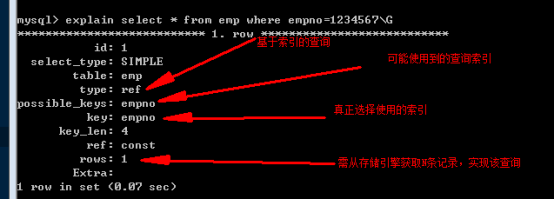
3、Explain 执行计划
可以通过在select语句前使用 explain,来获取该查询语句的执行计划,而不是真正执行该语句。
二、查询缓存(query_cache)
查看缓存配置:
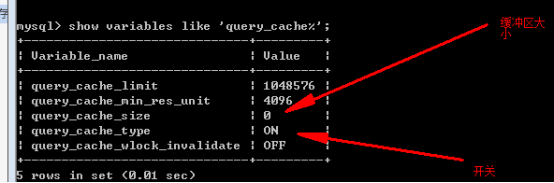
开启并设置大小:
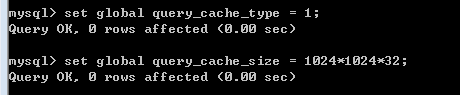
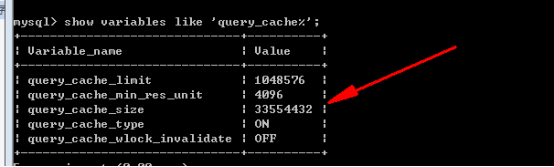
注意事项:
1、严格保证SQL一致,区分大小写等。
2、 如果查询时包含动态数据,则不能被缓存。
3、一旦开启查询缓存,MySQL会将所有可以被缓存的select语句都缓存。如果存在不想使用缓存的SQL执行,则可以使用 SQL_NO_CACHE语法提示达到目的。
三、分区
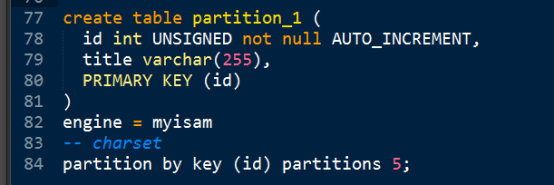
1、分区语法
Create table table_name (
定义
)
Partition by 分区算法 (参数) 分区选项。
注意:分区与存储引擎无关,是MySQL逻辑层完成的。
通过变量查看当前mysql是否支持分区:

分区算法:
MySQL提供4种
取余:Key,hash
条件:List,range
提示,参与分区的参数字段需要为主键的一部分。
- key - 按照某个字段进行取余
Hash - 按照某个表达式的值进行取余
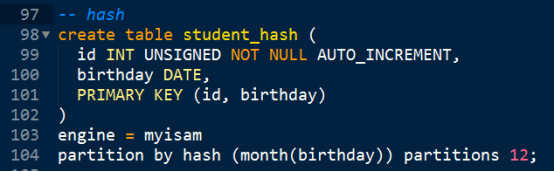
注意:Key,hash都是取余算法,要求分区参数,返回的数据必须为整数。
List - 需要指定的每个分区数据的存储条件
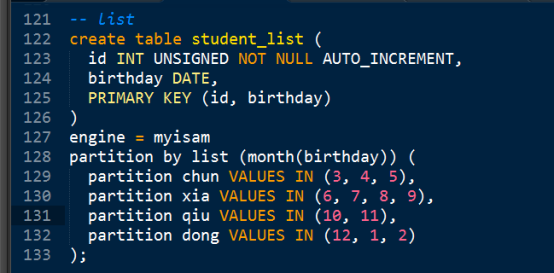
- Range - 条件依赖的数据是一个条件表达式
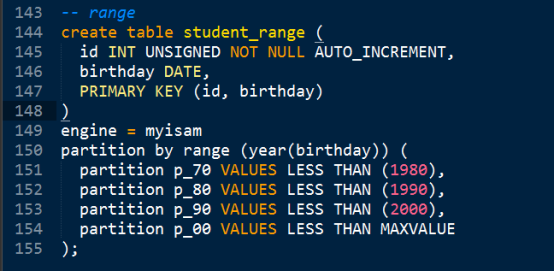
2、管理分区语法
- 取余:key和hash
增加分区数量:

减少分区数量:

采用取余算法的分区数量的修改,不会导致已有分区数据的丢失,需要重新分配数据到新大地分区。
- 条件:List和Range
添加分区:

删除分区:

注意:删除条件算法的分区,导致分区数据丢失。
四、分表
1、水平分表案例
创建结构相同的N个表:
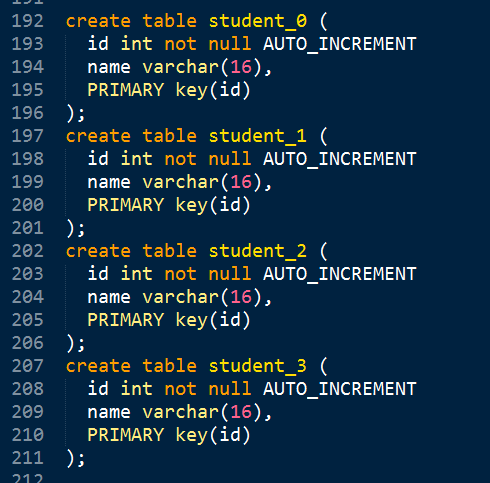
再创建用于管理学生ID的表:
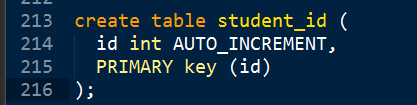
PHP客户端逻辑:
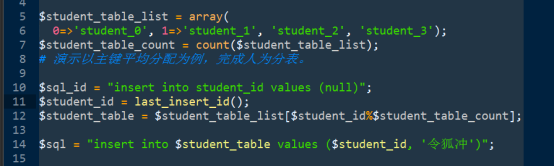
2、垂直分表
表中存在多个字段。
常用字段 - 非常有字段
主要目的,减少每条记录的长度。
例如学生表可以分成:
基础表和额外表,两张表中记录为1:1的关系。
案例:
基础信息表
Student_base
Id name age
额外信息表
Student_extra
Id 籍贯 政治面貌
五、架构层面

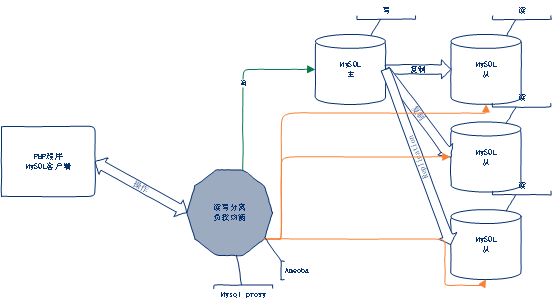
六、SQL语句
将复杂的SQL拆分多次执行。
案例:
商品,分类:
Select * from category;分类列表
Select cat_id, count(*) from goods group by goods;分类对应的商品数量。
分页
Limit offset, size;
Size = 10;
|
Page |
offset |
|
5 |
40, 10 |
|
50 |
490, 10 |
|
5000 |
4990, 10 |
|
500000 |
499990, 10 |
Limit 的使用,会大大提升无效数据的检索(被跳过)。
应该使用条件等过滤方式,将检索到的数据尽可能精确定位到需要的数据上。
例如分页:
Limit size;
七、慢查询日志
查看慢查询日志:
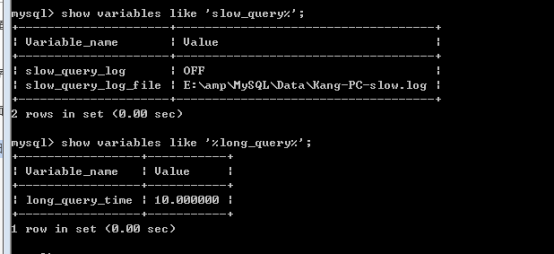
开启日志:
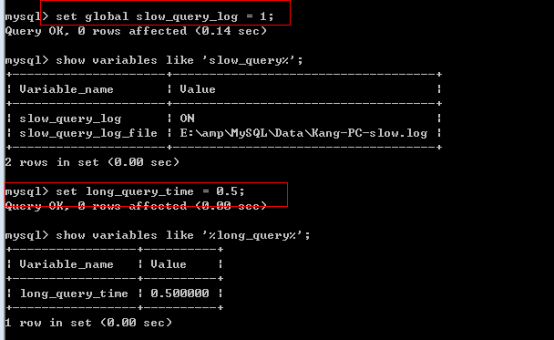
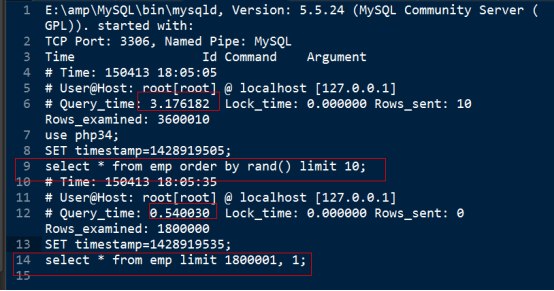
日志信息如下:
PHP 之Mysql优化的更多相关文章
- MySQL优化聊两句
原文地址:http://www.cnblogs.com/verrion/p/mysql_optimised.html MySQL优化聊两句 MySQL不多介绍,今天聊两句该如何优化以及从哪些方面入手, ...
- 0104探究MySQL优化器对索引和JOIN顺序的选择
转自http://www.jb51.net/article/67007.htm,感谢博主 本文通过一个案例来看看MySQL优化器如何选择索引和JOIN顺序.表结构和数据准备参考本文最后部分" ...
- mysql 优化
1.存储过程造数据 CREATE DEFINER=`root`@`localhost` PROCEDURE `generate_test_data`(`n` int) begin declare i ...
- mysql优化笔记之分页
过年闲得蛋疼,于是看看mysql优化,看了网上好多关于分页的优化方法,但是呢,我亲自试上一把的时候,没有出现他们说的现象...难道是我的机器问题么? 下面看看我的实践记录,希望看到的加入进来交流一下O ...
- MySQL优化概述
一. MySQL优化要点 MySQL优化是一门复杂的综合性技术,主要包括: 1 表的设计合理化(符合 3NF,必要时允许数据冗余) 2.1 SQL语句优化(以查询为主) 2.2 适当添加索引(主键索引 ...
- MySQL优化实例
这周就要从泰笛离职了,在公司内部的wiki上,根据公司实际的项目,写了一些mysql的优化方法,供小组里的小伙伴参考下,没想到大家的热情很高,还专门搞了个ppt讲解了一下. 举了三个大家很容易犯错的地 ...
- Mysql优化系列(2)--通用化操作梳理
前面有两篇文章详细介绍了mysql优化举措:Mysql优化系列(0)--总结性梳理Mysql优化系列(1)--Innodb引擎下mysql自身配置优化 下面分类罗列下Mysql性能优化的一些技巧,熟练 ...
- mysql优化记录
老板反应项目的反应越来越慢,叫优化一下,顺便学习总结一下mysql优化. 不同引擎的优化,myisam读的效果好,写的效率差,使用场景 非事务型应用只读类应用空间类应用 Innodb的特性,innod ...
- mysql 优化实例之索引创建
mysql 优化实例之索引创建 优化前: pt-query-degist分析结果: # Query 23: 0.00 QPS, 0.00x concurrency, ID 0x78761E301CC7 ...
- MySQL优化的奇技淫巧之STRAIGHT_JOIN
原文地址:http://huoding.com/2013/06/04/261 问题 通过「SHOW FULL PROCESSLIST」语句很容易就能查到问题SQL,如下: SELECT post.* ...
随机推荐
- 1.java小作业-计算1到100的整合-指定输入多少行输出就打印多少行-打印24小时60分钟每一分钟-重载基础练习-面向java编程初学者
可能有和我一样刚开始学习java的小伙伴们, 可以或多或少了解一点别的语言知识,我就是中途转过来的, 明白一点,关键不在语言本身····· 所以面对初学者来说,基础要学好, 下面列举几个没什么难度的小 ...
- Sequelize手记 - (一)
最近开始接触数据库,现在普遍用的都是Mysql数据库,简单的了解了一下sql语句,没有太深入的学习,然后就开始找相关的ORM框架,然后锁定了Sequelize,个人感觉很强大,搜索了一些文档,但是很让 ...
- Java框架之MyBatis框架(二)
Mybatis框架是相对于优化dao层的框架,其有效的减少了频繁的连接数据库(在配置文件xml中进行配置),将sql语句与java代码进行分离(写在XXXXmapper.xml文件中,一个表对应一个x ...
- vue中keep-alive,include的指定页面缓存问题
做vue项目时,有时要在某些页面做缓存,而其它页面不要.比如:A:首页,B:获取所有订单页面,C:订单详情页面:从A(首页)进入 B(获取所有订单)时应该不缓存,B(所有订单)进入 C(订单详情)订单 ...
- ffmpeg 把视频转换为图片
ffmpeg -i "Tail of Hope.mp4" -r 1 -q:v 2 -f image2 pic-%03d.jpeg
- MYSQL慢查询优化方法及优化原则
1.日期大小的比较,传到xml中的日期格式要符合'yyyy-MM-dd',这样才能走索引,如:'yyyy'改为'yyyy-MM-dd','yyyy-MM'改为'yyyy-MM-dd'[这样MYSQL会 ...
- Linux 服务控制与运行级别
如何控制服务的运行状态?如何切换不同的运行级别? 服务控制 ntsysv 仿图形交互界面,集中配置各种服务启动状态 --level 35:同时对指定运行级别中的服务进行管理,不加仅管理当前运行级别中的 ...
- js获取ip内网地址
<script type="text/javascript"> function getUserIP(onNewIP) { // onNewIp - your list ...
- java 的任意进制间转换
直接上代码: public class Main { public static void main(String[] args) { // TODO Auto-generated method st ...
- python笔记36-装饰器之wraps
前言 前面一篇对python装饰器有了初步的了解了,但是还不够完美,领导看了后又提出了新的需求,希望运行的日志能显示出具体运行的哪个函数. __name__和doc __name__用于获取函数的名称 ...