Neo4j 第八篇:投射和过滤
投射子句用于定义如何返回数据集,并可以对返回的表达式设置别名,而过滤子句用于对查询的结果集按照条件进行过滤
一,Return子句
使用return子句返回节点,关系和关系。
1,返回节点
MATCH (n { name: 'B' })
RETURN n
2,返回关系
MATCH (n { name: 'A' })-[r:KNOWS]->(c)
RETURN r
3,返回属性
MATCH (n { name: 'A' })
RETURN n.name
4,返回所有元素
MATCH p =(a { name: 'A' })-[r]->(b)
RETURN *
5,为属性设置别名
MATCH (a { name: 'A' })
RETURN a.age AS SomethingTotallyDifferent
6,返回谓词(predicate),文本(literal)或模式(pattern)
MATCH (a { name: 'A' })
RETURN a.age > 30, "I'm a literal",(a)-->()
7,使用distinct关键字返回不重复值
MATCH (a { name: 'A' })-->(b)
RETURN DISTINCT b
二,with 子句
一个查询(Query)语句有很多查询子句,每一个查询子句按照特定的顺序执行,每一个子句是查询的一部分(Part)。with子句的作用是把上一个查询的结果进行处理,作为下一个查询的数据源,也就是说,在上一个查询的结果输出到客户端之前,把结果传递到后续的子句中去。
1,对聚合的结果进行过滤
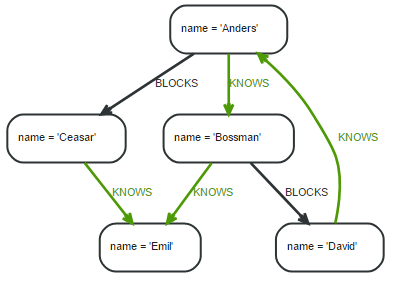
聚合的结果必须通过with子句才能被过滤,例如,with子句保留otherPerson,并新增聚合查询count(*),通过where子句过滤,返回查询结果:Anders。
MATCH (david { name: 'David' })--(otherPerson)-->()
WITH otherPerson, count(*) AS foaf
WHERE foaf > 1
RETURN otherPerson.name
2,限制返回的结果
MATCH (n { name: 'Anders' })--(m)
WITH m
ORDER BY m.name DESC LIMIT 1
MATCH (m)--(o)
RETURN o.name
三,unwind子句
unwind子句用于把list格式的字符串拆开为行的序列
1,拆开列表
UNWIND [1, 2, 3, NULL ] AS x
RETURN x, 'val' AS y
2,拆开嵌套列表
WITH [[1, 2],[3, 4], 5] AS nested
UNWIND nested AS x
UNWIND x AS y
RETURN y
3,Collect函数
collect函数用于把值组装成列表
WITH [1, 1, 2, 2] AS coll
UNWIND coll AS x
WITH DISTINCT x
RETURN collect(x) AS setOfVals
四,Where子句
使用Where子句对查询的结果进行过滤
1,按照逻辑表达式来过滤
MATCH (n)
WHERE n.name = 'Peter' XOR (n.age < 30 AND n.name = 'Tobias') OR NOT (n.name = 'Tobias' OR n.name = 'Peter')
RETURN n.name, n.age
2,按照节点的标签来过滤
MATCH (n)
WHERE n:Swedish
RETURN n.name, n.age
3,按照节点的属性来过滤
MATCH (n)
WHERE n.age < 30
RETURN n.name, n.age
4,按照关系的属性来过滤
MATCH (n)-[k:KNOWS]->(f)
WHERE k.since < 2000
RETURN f.name, f.age, f.email
5,按照动态计算的属性来计算
WITH 'AGE' AS propname
MATCH (n)
WHERE n[toLower(propname)]< 30
RETURN n.name, n.age
6,是否存在属性
MATCH (n)
WHERE exists(n.belt)
RETURN n.name, n.belt
7,字符串匹配
对字符串进行匹配:starts with、ends with,contains
MATCH (n)
WHERE n.name STARTS WITH 'Pet'
RETURN n.name, n.age MATCH (n)
WHERE n.name ENDS WITH 'ter'
RETURN n.name, n.age MATCH (n)
WHERE n.name CONTAINS 'ete'
RETURN n.name, n.age
8,正则匹配
使用 =~ 'regexp' 匹配正则 ,如果正则表达式以(?i)开头,表示整个正则是大小写敏感的。
MATCH (n)
WHERE n.name =~ 'Tob.*'
RETURN n.name, n.age MATCH (n)
WHERE n.name =~ '(?i)ANDR.*'
RETURN n.name, n.age
9,匹配路径模式
MATCH (tobias { name: 'Tobias' }),(others)
WHERE others.name IN ['Andres', 'Peter'] AND (tobias)<--(others)
RETURN others.name, others.age
使用not来排除路径模式:
MATCH (persons),(peter { name: 'Peter' })
WHERE NOT (persons)-->(peter)
RETURN persons.name, persons.age
使用属性来匹配路径:
MATCH (n)
WHERE (n)-[:KNOWS]-({ name: 'Tobias' })
RETURN n.name, n.age
使用关系类型来匹配路径:
MATCH (n)-[r]->()
WHERE n.name='Andres' AND type(r)=~ 'K.*'
RETURN type(r), r.since
10,列表
使用IN操作符表示匹配列表中的元素
MATCH (a)
WHERE a.name IN ['Peter', 'Tobias']
RETURN a.name, a.age
11,缺失值
如果属性值缺失,那么属性值默认值是null,null和任何值比较都是false;可以使用is not null 或 is null来判断是否为null
MATCH (person)
WHERE person.name = 'Peter' AND person.belt IS NULL
RETURN person.name, person.age, person.belt
五,排序
使用order by对查询的结果进行排序,默认是升序,使用关键字desc使Cypher按照降序进行排序。
1,按照节点的属性进行升序排序
MATCH (n)
RETURN n.name, n.age
ORDER BY n.name
2,按照节点的属性值进行降序排序
MATCH (n)
RETURN n.name, n.age
ORDER BY n.name DESC
六,SKIP和LIMIT
SKIP是跳过前N行,LIMIT是限制返回的数量
1,跳过前3行
MATCH (n)
RETURN n.name
ORDER BY n.name
SKIP 3
2,跳过前3行,返回第4和5行
MATCH (n)
RETURN n.name
ORDER BY n.name
SKIP 3
LIMIT 2
参考文档:
Neo4j 第八篇:投射和过滤的更多相关文章
- 【译】SQL Server索引进阶第八篇:唯一索引
原文:[译]SQL Server索引进阶第八篇:唯一索引 索引设计是数据库设计中比较重要的一个环节,对数据库的性能其中至关重要的作用,但是索引的设计却又不是那么容易的事情,性能也不是那么轻易就 ...
- ElasticSearch入门 第八篇:存储
这是ElasticSearch 2.4 版本系列的第八篇: ElasticSearch入门 第一篇:Windows下安装ElasticSearch ElasticSearch入门 第二篇:集群配置 E ...
- Mysql优化(出自官方文档) - 第八篇(索引优化系列)
目录 Mysql优化(出自官方文档) - 第八篇(索引优化系列) Optimization and Indexes 1 Foreign Key Optimization 2 Column Indexe ...
- 解剖SQLSERVER 第八篇 OrcaMDF 现在支持多数据文件的数据库(译)
解剖SQLSERVER 第八篇 OrcaMDF 现在支持多数据文件的数据库(译) http://improve.dk/orcamdf-now-supports-databases-with-mult ...
- Python之路【第十八篇】:Web框架们
Python之路[第十八篇]:Web框架们 Python的WEB框架 Bottle Bottle是一个快速.简洁.轻量级的基于WSIG的微型Web框架,此框架只由一个 .py 文件,除了Pytho ...
- 第八篇 :微信公众平台开发实战Java版之如何网页授权获取用户基本信息
第一部分:微信授权获取基本信息的介绍 我们首先来看看官方的文档怎么说: 如果用户在微信客户端中访问第三方网页,公众号可以通过微信网页授权机制,来获取用户基本信息,进而实现业务逻辑. 关于网页授权回调域 ...
- 第八篇 Replication:合并复制-How it works
本篇文章是SQL Server Replication系列的第八篇,详细内容请参考原文. 在这一系列的前几篇你已经学习了如何在多服务器环境中配置合并复制.这一篇将介绍合并代理并解释它在复制过程中扮演的 ...
- 第八篇 Integration Services:高级工作流管理
本篇文章是Integration Services系列的第八篇,详细内容请参考原文. 简介在前面两篇文章,我们创建了一个新的SSIS包,学习了SSIS中的脚本任务和优先约束,并检查包的MaxConcu ...
- 第八篇 SQL Server安全数据加密
本篇文章是SQL Server安全系列的第八篇,详细内容请参考原文. Relational databases are used in an amazing variety of applicatio ...
随机推荐
- HttpHelper之我见
前几月一直用一个Http的访问类去调用WebApi,说句实话最开始没觉有什么,一是技术老,二是觉得比较简单,但是最近我一直关注云开发和AI这块儿微软技术,看到云平台调用API大多类似,所以回想这个早年 ...
- 华为手机 android8.0APP更新时出现安装包解析异常的提示及安装闪退(无反应)问题
在做android app升级更新时遇到几个问题,我用的测试机是华为V10 系统为8.0 一.安装闪退(无反应) 解决办法: 只要在Mainfest.xml 中加入权限编码即可解决 <uses- ...
- 了解iOS各个版本新特性总结
参考了一下的文章:https://blog.csdn.net/zxtc19920/article/details/54341836 iOS7新特性 · 在iOS7当中,使用麦克风也需要取得用户同意了. ...
- ZooKeeper之服务器动态上下线案例
需求 某分布式系统中,主节点可以有多台,可以动态上下线,任意一台客户端都能实时感知到主节点服务器的上下线. 需求分析 具体实现 先在集群上创建/servers节点 create /servers &q ...
- 简易解说拉格朗日对偶(Lagrange duality)(转载)
转载自https://www.cnblogs.com/90zeng/p/Lagrange_duality.html,本人觉得讲的非常好! 1.原始问题 假设是定义在上的连续可微函数(为什么要求连续可微 ...
- super与this用法
super注意点: 1.当super调用父类的构造方法,必须在构造方法的第一个: 2.super必须只能出现在子类的方法或者构造方法中: 3.super和this不能同时调用构造方法: 4.super ...
- AssetBundleMaster_ReadMe_EN
Before we start use it, you'd better import it to an empty project, following the ReadMe to learn th ...
- 如果使用jsp文件,需要在配置文件中配置resources项,才能让idea识别这个jsp文件
没有添加这一项在编译后的.class文件中的结构目录是这样子的 添加上这一个配置项,在class配置文件中的位置是这样子的: 添加的配置文件是这样子的: <resources> <r ...
- android 开发工具 adb
1.abd基本使用 1.启动一个adb应用程序 adb -P <port> start-server # -P指定端口 默认是5037 1.停止adb adb kill-server 2. ...
- VMware10新建虚拟机
1. 新建虚拟机 2. 选择 “典型(推荐)(T)” 安装 3. “稍后安装操作系统”,创建一个空白硬盘 4. 选择 “Linux” 的 “CentOS 64位” 5. 设置 “虚拟机名称” 和 “位 ...