python爬虫之Scrapy学习
在爬虫的路上,学习scrapy是一个必不可少的环节。也许有好多朋友此时此刻也正在接触并学习scrapy,那么很好,我们一起学习。开始接触scrapy的朋友可能会有些疑惑,毕竟是一个框架,上来不知从何学起。从本篇起,博主将开启scrapy学习的系列,分享如何快速入门scrapy并熟练使用它。
本篇作为第一篇,主要介绍和了解scrapy,在结尾会向大家推荐一本关于学习scrapy的书,以及获取的方式。
为什么要用爬虫框架?
如果你对爬虫的基础知识有了一定了解的话,那么是时候该了解一下爬虫框架了。那么为什么要使用爬虫框架?
- 学习框架的根本是学习一种编程思想,而不应该仅仅局限于是如何使用它。从了解到掌握一种框架,其实是对一种思想理解的过程。
- 框架也给我们的开发带来了极大的方便。许多条条框框都已经是写好了的,并不需要我们重复造轮子,我们只需要根据自己的需求定制自己要实现的功能就好了,大大减少了工作量。
- 参考并学习优秀的框架代码,提升编程代码能力。
博主当时是根据这几点来进行爬虫框架的学习的,但是切记核心目标是掌握一种框架思想,一种框架的能力,掌握了这种思想你才能更好的去使用它,甚至扩展它。
scrapy框架的介绍
比较流行的爬虫的框架有scrapy和pyspider,但是被大家所钟爱的我想非scrapy莫属了。scrapy是一个开源的高级爬虫框架,我们可以称它为"scrapy语言"。它使用python编写,用于爬取网页,提取结构性数据,并可将抓取得结构性数据较好的应用于数据分析和数据挖掘。scrapy有以下的一些特点:
scrapy基于事件的机制,利用twisted的设计实现了非阻塞的异步操作。这相比于传统的阻塞式请求,极大的提高了CPU的使用率,以及爬取效率。- 配置简单,可以简单的通过设置一行代码实现复杂功能。
- 可拓展,插件丰富,比如分布式
scrapy + redis、爬虫可视化等插件。 - 解析方便易用,
scrapy封装了xpath等解析器,提供了更方便更高级的selector构造器,可有效的处理破损的HTML代码和编码。
scrapy和requests+bs用哪个好?
有的朋友问了,为什么要使用scrapy,不使用不行吗?用resquests + beautifulsoup组合难道不能完成吗?
不用纠结,根据自己方便来。resquests + beautifulsoup当然可以了,requests + 任何解析器都行,都是非常好的组合。这样用的优点是我们可以灵活的写我们自己的代码,不必拘泥于固定模式。对于使用固定的框架有时候不一定用起来方便,比如scrapy对于反反爬的处理并没有很完善,好多时候也要自己来解决。
但是对于一些中小型的爬虫任务来讲,scrapy确实是非常好的选择,它避免了我们来写一些重复的代码,并且有着出色的性能。我们自己写代码的时候,比如为了提高爬取效率,每次都自己码多线程或异步等代码,大大浪费了开发时间。这时候使用已经写好的框架是再好不过的选择了,我们只要简单的写写解析规则和pipeline就好了。那么具体哪些是需要我们做的呢?看看下面这个图就明白了。
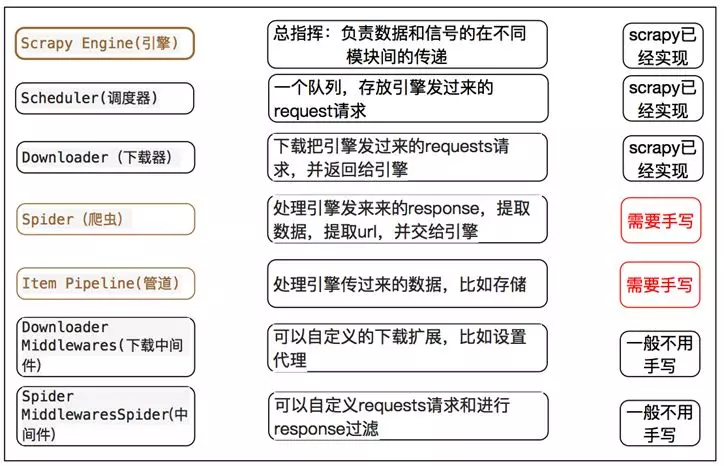
因此,对于该用哪个,根据个人需求和喜好决定。但是至于学习的先后顺序,建议先学学resquests + beautifulsoup,然后再接触Scrapy效果可能会更好些,仅供参考。
scrapy的架构
在学习Scrapy之前,我们需要了解Scrapy的架构,明白这个架构对学习scrapy至关重要。
Scrapy官方文档的图片
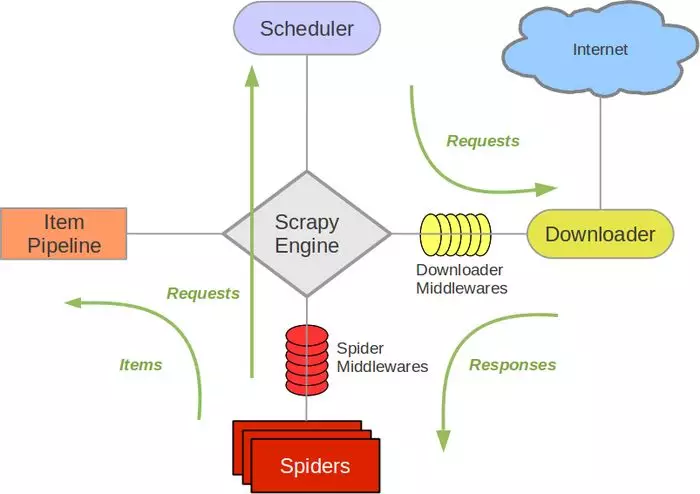
下面的描述引自官方doc文档(在此引用),讲的很清楚明白,对照这个图看就能明白。
组件
Scrapy Engine
引擎负责控制数据流在系统中所有组件中流动,并在相应动作发生时触发事件。 详细内容查看下面的数据流(Data Flow)部分。
调度器(Scheduler)
调度器从引擎接受request并将他们入队,以便之后引擎请求他们时提供给引擎。
下载器(Downloader)
下载器负责获取页面数据并提供给引擎,而后提供给spider。
SpidersSpider是Scrapy用户编写用于分析response并提取item(即获取到的item)或额外跟进的URL的类。 每个spider负责处理一个特定(或一些)网站。
Item PipelineItem Pipeline负责处理被spider提取出来的item。典型的处理有清理、 验证及持久化(例如存取到数据库中)。
下载器中间件(Downloader middlewares)
下载器中间件是在引擎及下载器之间的特定钩子(specific hook),处理Downloader传递给引擎的response。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。
Spider中间件(Spider middlewares)Spider中间件是在引擎及Spider之间的特定钩子(specific hook),处理spider的输入(response)和输出(items及requests)。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。
数据流过程
- 引擎打开一个网站
(open a domain),找到处理该网站的Spider并向该spider请求第一个要爬取的URL(s)。 - 引擎从
Spider中获取到第一个要爬取的URL并在调度器(Scheduler)以Request调度。 - 引擎向调度器请求下一个要爬取的URL。
- 调度器返回下一个要爬取的URL给引擎,引擎将URL通过下载中间件(请求
(request)方向)转发给下载器(Downloader)。 - 一旦页面下载完毕,下载器生成一个该页面的
Response,并将其通过下载中间件(返回(response)方向)发送给引擎。 - 引擎从下载器中接收到
Response并通过Spider中间件(输入方向)发送给Spider处理。 Spider处理Response并返回爬取到的Item及(跟进的)新的Request给引擎。- 引擎将(Spider返回的)爬取到的Item给
Item Pipeline,将(Spider返回的)Request给调度器。 - (从第二步)重复直到调度器中没有更多地
request,引擎关闭该网站。
python爬虫之Scrapy学习的更多相关文章
- Python爬虫框架Scrapy学习笔记原创
字号 scrapy [TOC] 开始 scrapy安装 首先手动安装windows版本的Twisted https://www.lfd.uci.edu/~gohlke/pythonlibs/#twi ...
- 《精通Python爬虫框架Scrapy》学习资料
<精通Python爬虫框架Scrapy>学习资料 百度网盘:https://pan.baidu.com/s/1ACOYulLLpp9J7Q7src2rVA
- 《Python3网络爬虫开发实战》PDF+源代码+《精通Python爬虫框架Scrapy》中英文PDF源代码
下载:https://pan.baidu.com/s/1oejHek3Vmu0ZYvp4w9ZLsw <Python 3网络爬虫开发实战>中文PDF+源代码 下载:https://pan. ...
- 0.Python 爬虫之Scrapy入门实践指南(Scrapy基础知识)
目录 0.0.Scrapy基础 0.1.Scrapy 框架图 0.2.Scrapy主要包括了以下组件: 0.3.Scrapy简单示例如下: 0.4.Scrapy运行流程如下: 0.5.还有什么? 0. ...
- 教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http://www.xiaohuar.com/,让你体验爬取校花的成就感. Scr ...
- 【转载】教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
原文:教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神 本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http:/ ...
- Linux 安装python爬虫框架 scrapy
Linux 安装python爬虫框架 scrapy http://scrapy.org/ Scrapy是python最好用的一个爬虫框架.要求: python2.7.x. 1. Ubuntu14.04 ...
- Python爬虫框架Scrapy实例(三)数据存储到MongoDB
Python爬虫框架Scrapy实例(三)数据存储到MongoDB任务目标:爬取豆瓣电影top250,将数据存储到MongoDB中. items.py文件复制代码# -*- coding: utf-8 ...
- Python爬虫框架Scrapy教程(1)—入门
最近实验室的项目中有一个需求是这样的,需要爬取若干个(数目不小)网站发布的文章元数据(标题.时间.正文等).问题是这些网站都很老旧和小众,当然也不可能遵守 Microdata 这类标准.这时候所有网页 ...
随机推荐
- nodejs,npm 安装配置步骤
http://xiaoyaojones.blog.163.com/blog/static/28370125201351501113581/ 参照上述网址中的方法 特别强调一下,在第三步的时候,在命令行 ...
- 网络编程 TCP协议:三次握手,四次回收,反馈机制 socket套接字通信 粘包问题与解决方法
TCP协议:传输协议,基于端口工作 三次握手,四次挥手 TCP协议建立双向通道. 三次握手, 建连接: 1:客户端向服务端发送建立连接的请求 2:服务端返回收到请求的信息给客户端,并且发送往客户端建立 ...
- Ant Design Pro 鉴权/ 权限管理
https://pro.ant.design/docs/authority-management-cn ant-design-pro 1.0.0 V4 最近需要项目需要用扫码登录,因此就使用antd ...
- redis主从+redis的哨兵模式
三台机器分布 192.168.189.129 // master的角色 192.168.189.130 // slave1的角色 192.168.189.131 // salve2的角色 ...
- 【JZOJ6239】【20190629】智慧树
题目 一颗\(n\)个节点的树,每个点有一个权值\(a_i\) 询问树上连通块权值之和对 \(m\) 取模为$ x $ 的方案数 答案对\(950009857\) 取模,满足\(m | 9500098 ...
- Ajax运用与分页
目录 django与ajax的分页处理 ajax + sweetAlert 实现再次确认: 批量数据插入 分页: django与ajax的分页处理 ajax + sweetAlert 实现再次确认: ...
- 使Jackson和Mybatis支持JSR310标准
1.首先要确保Jackson和Mybatis正确地整合进项目了 2.添加额外的依赖 <dependency> <groupId>org.mybatis</groupId& ...
- UA记录
安卓QQ内置浏览器UA: Mozilla/5.0 (Linux; Android 5.0; SM-N9100 Build/LRX21V) AppleWebKit/537.36 (KHTML, like ...
- 浅谈[0,1]区间内的n个随机实数变量中增加偏序关系类题目的解法
浅谈[0,1]区间内的n个随机实数变量中增加偏序关系类题目的解法 众所周知,把[0,1]区间内的n个随机.相互独立的实数变量\(x_i\)之间的大小关系写成一个排列\(\{p_i\}\),使得\(\f ...
- Salesforce 开发整理(五)代码开发最佳实践
在Salesforce项目实施过程中,对项目代码的维护可以说占据极大的精力,无论是因为项目的迭代,还是需求的变更,甚至是项目组成员的变动,都不可避免的需要维护之前的老代码,而事实上,几乎没有任何一个项 ...