python爬虫之Scrapy学习
在爬虫的路上,学习scrapy是一个必不可少的环节。也许有好多朋友此时此刻也正在接触并学习scrapy,那么很好,我们一起学习。开始接触scrapy的朋友可能会有些疑惑,毕竟是一个框架,上来不知从何学起。从本篇起,博主将开启scrapy学习的系列,分享如何快速入门scrapy并熟练使用它。
本篇作为第一篇,主要介绍和了解scrapy,在结尾会向大家推荐一本关于学习scrapy的书,以及获取的方式。
为什么要用爬虫框架?
如果你对爬虫的基础知识有了一定了解的话,那么是时候该了解一下爬虫框架了。那么为什么要使用爬虫框架?
- 学习框架的根本是学习一种编程思想,而不应该仅仅局限于是如何使用它。从了解到掌握一种框架,其实是对一种思想理解的过程。
- 框架也给我们的开发带来了极大的方便。许多条条框框都已经是写好了的,并不需要我们重复造轮子,我们只需要根据自己的需求定制自己要实现的功能就好了,大大减少了工作量。
- 参考并学习优秀的框架代码,提升编程代码能力。
博主当时是根据这几点来进行爬虫框架的学习的,但是切记核心目标是掌握一种框架思想,一种框架的能力,掌握了这种思想你才能更好的去使用它,甚至扩展它。
scrapy框架的介绍
比较流行的爬虫的框架有scrapy和pyspider,但是被大家所钟爱的我想非scrapy莫属了。scrapy是一个开源的高级爬虫框架,我们可以称它为"scrapy语言"。它使用python编写,用于爬取网页,提取结构性数据,并可将抓取得结构性数据较好的应用于数据分析和数据挖掘。scrapy有以下的一些特点:
scrapy基于事件的机制,利用twisted的设计实现了非阻塞的异步操作。这相比于传统的阻塞式请求,极大的提高了CPU的使用率,以及爬取效率。- 配置简单,可以简单的通过设置一行代码实现复杂功能。
- 可拓展,插件丰富,比如分布式
scrapy + redis、爬虫可视化等插件。 - 解析方便易用,
scrapy封装了xpath等解析器,提供了更方便更高级的selector构造器,可有效的处理破损的HTML代码和编码。
scrapy和requests+bs用哪个好?
有的朋友问了,为什么要使用scrapy,不使用不行吗?用resquests + beautifulsoup组合难道不能完成吗?
不用纠结,根据自己方便来。resquests + beautifulsoup当然可以了,requests + 任何解析器都行,都是非常好的组合。这样用的优点是我们可以灵活的写我们自己的代码,不必拘泥于固定模式。对于使用固定的框架有时候不一定用起来方便,比如scrapy对于反反爬的处理并没有很完善,好多时候也要自己来解决。
但是对于一些中小型的爬虫任务来讲,scrapy确实是非常好的选择,它避免了我们来写一些重复的代码,并且有着出色的性能。我们自己写代码的时候,比如为了提高爬取效率,每次都自己码多线程或异步等代码,大大浪费了开发时间。这时候使用已经写好的框架是再好不过的选择了,我们只要简单的写写解析规则和pipeline就好了。那么具体哪些是需要我们做的呢?看看下面这个图就明白了。
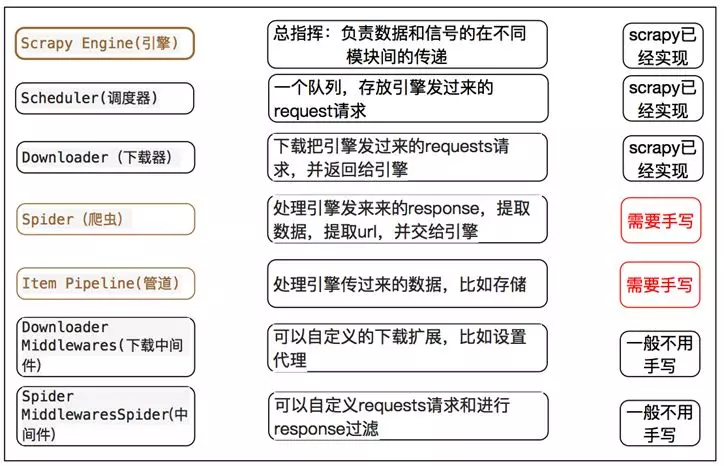
因此,对于该用哪个,根据个人需求和喜好决定。但是至于学习的先后顺序,建议先学学resquests + beautifulsoup,然后再接触Scrapy效果可能会更好些,仅供参考。
scrapy的架构
在学习Scrapy之前,我们需要了解Scrapy的架构,明白这个架构对学习scrapy至关重要。
Scrapy官方文档的图片
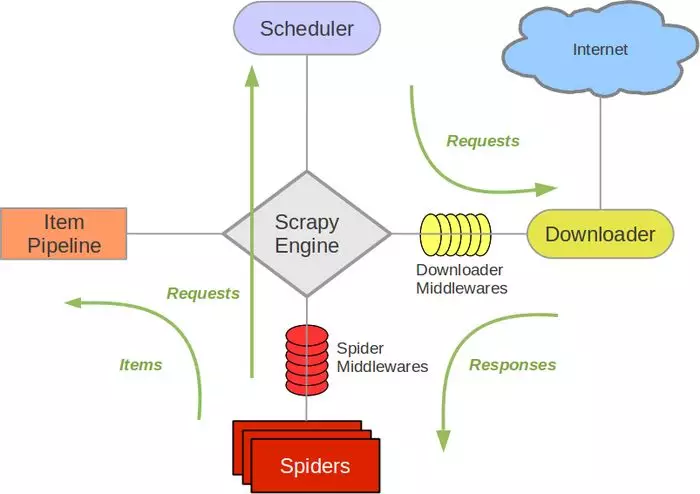
下面的描述引自官方doc文档(在此引用),讲的很清楚明白,对照这个图看就能明白。
组件
Scrapy Engine
引擎负责控制数据流在系统中所有组件中流动,并在相应动作发生时触发事件。 详细内容查看下面的数据流(Data Flow)部分。
调度器(Scheduler)
调度器从引擎接受request并将他们入队,以便之后引擎请求他们时提供给引擎。
下载器(Downloader)
下载器负责获取页面数据并提供给引擎,而后提供给spider。
SpidersSpider是Scrapy用户编写用于分析response并提取item(即获取到的item)或额外跟进的URL的类。 每个spider负责处理一个特定(或一些)网站。
Item PipelineItem Pipeline负责处理被spider提取出来的item。典型的处理有清理、 验证及持久化(例如存取到数据库中)。
下载器中间件(Downloader middlewares)
下载器中间件是在引擎及下载器之间的特定钩子(specific hook),处理Downloader传递给引擎的response。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。
Spider中间件(Spider middlewares)Spider中间件是在引擎及Spider之间的特定钩子(specific hook),处理spider的输入(response)和输出(items及requests)。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。
数据流过程
- 引擎打开一个网站
(open a domain),找到处理该网站的Spider并向该spider请求第一个要爬取的URL(s)。 - 引擎从
Spider中获取到第一个要爬取的URL并在调度器(Scheduler)以Request调度。 - 引擎向调度器请求下一个要爬取的URL。
- 调度器返回下一个要爬取的URL给引擎,引擎将URL通过下载中间件(请求
(request)方向)转发给下载器(Downloader)。 - 一旦页面下载完毕,下载器生成一个该页面的
Response,并将其通过下载中间件(返回(response)方向)发送给引擎。 - 引擎从下载器中接收到
Response并通过Spider中间件(输入方向)发送给Spider处理。 Spider处理Response并返回爬取到的Item及(跟进的)新的Request给引擎。- 引擎将(Spider返回的)爬取到的Item给
Item Pipeline,将(Spider返回的)Request给调度器。 - (从第二步)重复直到调度器中没有更多地
request,引擎关闭该网站。
python爬虫之Scrapy学习的更多相关文章
- Python爬虫框架Scrapy学习笔记原创
字号 scrapy [TOC] 开始 scrapy安装 首先手动安装windows版本的Twisted https://www.lfd.uci.edu/~gohlke/pythonlibs/#twi ...
- 《精通Python爬虫框架Scrapy》学习资料
<精通Python爬虫框架Scrapy>学习资料 百度网盘:https://pan.baidu.com/s/1ACOYulLLpp9J7Q7src2rVA
- 《Python3网络爬虫开发实战》PDF+源代码+《精通Python爬虫框架Scrapy》中英文PDF源代码
下载:https://pan.baidu.com/s/1oejHek3Vmu0ZYvp4w9ZLsw <Python 3网络爬虫开发实战>中文PDF+源代码 下载:https://pan. ...
- 0.Python 爬虫之Scrapy入门实践指南(Scrapy基础知识)
目录 0.0.Scrapy基础 0.1.Scrapy 框架图 0.2.Scrapy主要包括了以下组件: 0.3.Scrapy简单示例如下: 0.4.Scrapy运行流程如下: 0.5.还有什么? 0. ...
- 教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http://www.xiaohuar.com/,让你体验爬取校花的成就感. Scr ...
- 【转载】教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
原文:教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神 本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http:/ ...
- Linux 安装python爬虫框架 scrapy
Linux 安装python爬虫框架 scrapy http://scrapy.org/ Scrapy是python最好用的一个爬虫框架.要求: python2.7.x. 1. Ubuntu14.04 ...
- Python爬虫框架Scrapy实例(三)数据存储到MongoDB
Python爬虫框架Scrapy实例(三)数据存储到MongoDB任务目标:爬取豆瓣电影top250,将数据存储到MongoDB中. items.py文件复制代码# -*- coding: utf-8 ...
- Python爬虫框架Scrapy教程(1)—入门
最近实验室的项目中有一个需求是这样的,需要爬取若干个(数目不小)网站发布的文章元数据(标题.时间.正文等).问题是这些网站都很老旧和小众,当然也不可能遵守 Microdata 这类标准.这时候所有网页 ...
随机推荐
- HDU4747:Mex(线段树区间修改)
传送门 题意: 给出\(n\)个数,然后求\(\sum_{i=1}^n\sum_{j=i}^nmex(i,j)\).\(mex(i,j)\)表示区间\([i,j]\)的\(mex\). 思路: 考虑枚 ...
- 第05节-BLE协议物理层(PHY)
对于软件的人来说,物理层关注的内容会少一点.在前面的博客中,我们以快递员类比物理层,对于快递员来说,道路千万条,这条不通换另外一条.对于物理层来说也是一样的,它有很多频率,这个频率有冲突了,将会切到另 ...
- Selenium请求库
阅读目录 一 介绍 二 安装 三 基本使用 四 等待元素被加载 五 选择器 六 元素交互操作 七 其他 八 项目练习 九 破解登录验证 一 介绍 1.selenium是什么? selenium最初是一 ...
- WebStorm取消默认style样式折叠
WebStorm取消默认style样式折叠: File--->Settings打开一个窗口 Edit--->CodeFolding 把HTML style attribute的前面的钩去掉 ...
- openpose开发(1)官方1.5版本源码编译
环境 WIN10系统,联想Y7000配置,8G内存 VS2019 cuda10 cudnn10 opencv4.11没有扩展库 显卡 1050TI 用到的库(提前下载好的模型,依赖库,user_cod ...
- Jmeter函数助手—自带方法
1.${__time()}---->当前时间,一串数字格式 2.${__time(yyyy-MM-dd)}----->当前日期,年-月-日格式 3.${__time(yyyy-MM-dd ...
- pychram-redis破解
1. Preferences -> Plugins-> 选择右下角Browse repositories 2. 搜索Iedis 3. 找到Iedis插件目录:C:\Users\用户名\.P ...
- [C#]AdvPropertyGrid的使用示例(第三方控件:DevComponents.DotNetBar2.dll)
开发环境:Visual Studio 2019 .NET版本:4.5.2 效果如下: 1.初始化界面: 2.属性“人物”-自定义控件显示: 3.属性“地址”-自定义窗体显示: 4.属性“性别”-枚举显 ...
- 别再说你不会 ElasticSearch 调优了,都给你整理好了
来源:http://tinyurl.com/y4gnzbje 第一部分:调优索引速度 第二部分-调优搜索速度 第三部分:通用的一些建议 英文原文:https://www.elastic.co/guid ...
- 【2019年06月28日】A股最便宜的股票
查看更多A股最便宜的股票:androidinvest.com/CNValueTop/ 经典价值三因子选股: 市盈率PE.市净率PB 和 股息分红率,按照 1:1:1的权重,选择前10大最便宜的股票. ...