【转载】 tensorflow中 tf.train.slice_input_producer 和 tf.train.batch 函数
原文地址:
https://blog.csdn.net/dcrmg/article/details/79776876
------------------------------------------------------------------------------------------------------------------
tensorflow数据读取机制
tensorflow中为了充分利用GPU,减少GPU等待数据的空闲时间,使用了两个线程分别执行数据读入和数据计算。
具体来说就是使用一个线程源源不断的将硬盘中的图片数据读入到一个内存队列中,另一个线程负责计算任务,所需数据直接从内存队列中获取。
tf在内存队列之前,还设立了一个文件名队列,文件名队列存放的是参与训练的文件名,要训练 N个epoch,则文件名队列中就含有N个批次的所有文件名。 示例图如下:
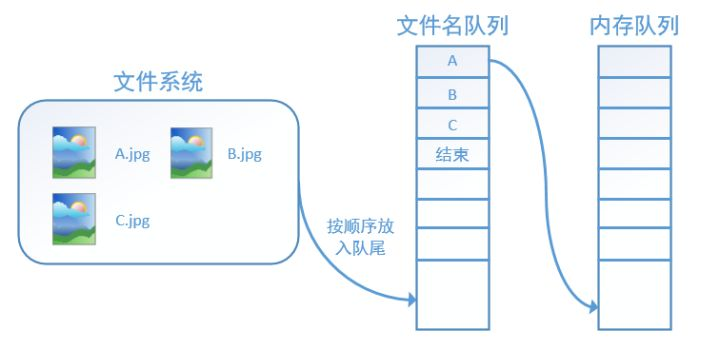
图片来至于 https://zhuanlan.zhihu.com/p/27238630)
在N个epoch的文件名最后是一个结束标志,当tf读到这个结束标志的时候,会抛出一个 OutofRange 的异常,外部捕获到这个异常之后就可以结束程序了。而创建tf的文件名队列就需要使用到 tf.train.slice_input_producer 函数。
tf.train.slice_input_producer
tf.train.slice_input_producer是一个tensor生成器,作用是按照设定,每次从一个tensor列表中按顺序或者随机抽取出一个tensor放入文件名队列。
slice_input_producer(tensor_list, num_epochs=None, shuffle=True, seed=None,
capacity=32, shared_name=None, name=None)
- 第一个参数 tensor_list:包含一系列tensor的列表,表中tensor的第一维度的值必须相等,即个数必须相等,有多少个图像,就应该有多少个对应的标签。
- 第二个参数num_epochs: 可选参数,是一个整数值,代表迭代的次数,如果设置 num_epochs=None,生成器可以无限次遍历tensor列表,如果设置为 num_epochs=N,生成器只能遍历tensor列表N次。
- 第三个参数shuffle: bool类型,设置是否打乱样本的顺序。一般情况下,如果shuffle=True,生成的样本顺序就被打乱了,在批处理的时候不需要再次打乱样本,使用 tf.train.batch函数就可以了;如果shuffle=False,就需要在批处理时候使用 tf.train.shuffle_batch函数打乱样本。
- 第四个参数seed: 可选的整数,是生成随机数的种子,在第三个参数设置为shuffle=True的情况下才有用。
- 第五个参数capacity:设置tensor列表的容量。
- 第六个参数shared_name:可选参数,如果设置一个‘shared_name’,则在不同的上下文环境(Session)中可以通过这个名字共享生成的tensor。
- 第七个参数name:可选,设置操作的名称。
tf.train.slice_input_producer定义了样本放入文件名队列的方式,包括迭代次数,是否乱序等,要真正将文件放入文件名队列,还需要调用tf.train.start_queue_runners 函数来启动执行文件名队列填充的线程,之后计算单元才可以把数据读出来,否则文件名队列为空的,计算单元就会处于一直等待状态,导致系统阻塞。
tf.train.slice_input_producer 和 tf.train.start_queue_runners 使用:
import tensorflow as tf images = ['img1', 'img2', 'img3', 'img4', 'img5']
labels= [1,2,3,4,5] epoch_num=8 f = tf.train.slice_input_producer([images, labels],num_epochs=None,shuffle=False) with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
for i in range(epoch_num):
k = sess.run(f)
print ('************************')
print (i,k) coord.request_stop()
coord.join(threads)
tf.train.slice_input_producer函数中shuffle=False,不对tensor列表乱序,输出:

如果设置shuffle=True,输出乱序:

tf.train.batch
tf.train.batch是一个tensor队列生成器,作用是按照给定的tensor顺序,把batch_size个tensor推送到文件队列,作为训练一个batch的数据,等待tensor出队执行计算。
batch(tensors, batch_size, num_threads=1, capacity=32,
enqueue_many=False, shapes=None, dynamic_pad=False,
allow_smaller_final_batch=False, shared_name=None, name=None)
- 第一个参数tensors:tensor序列或tensor字典,可以是含有单个样本的序列;
- 第二个参数batch_size: 生成的batch的大小;
- 第三个参数num_threads:执行tensor入队操作的线程数量,可以设置使用多个线程同时并行执行,提高运行效率,但也不是数量越多越好;
- 第四个参数capacity: 定义生成的tensor序列的最大容量;
- 第五个参数enqueue_many: 定义第一个传入参数tensors是多个tensor组成的序列,还是单个tensor;
- 第六个参数shapes: 可选参数,默认是推测出的传入的tensor的形状;
- 第七个参数dynamic_pad: 定义是否允许输入的tensors具有不同的形状,设置为True,会把输入的具有不同形状的tensor归一化到相同的形状;
- 第八个参数allow_smaller_final_batch: 设置为True,表示在tensor队列中剩下的tensor数量不够一个batch_size的情况下,允许最后一个batch的数量少于batch_size, 设置为False,则不管什么情况下,生成的batch都拥有batch_size个样本;
- 第九个参数shared_name: 可选参数,设置生成的tensor序列在不同的Session中的共享名称;
- 第十个参数name: 操作的名称;
如果tf.train.batch的第一个参数 tensors 传入的是tenor列表或者字典,返回的是tensor列表或字典,如果传入的是只含有一个元素的列表,返回的是单个的tensor,而不是一个列表。
以下举例: 一共有5个样本,设置迭代次数是2次,每个batch中含有3个样本,不打乱样本顺序:
# -*- coding:utf-8 -*-
import tensorflow as tf
import numpy as np # 样本个数
sample_num=5 # 设置迭代次数
epoch_num = 2 # 设置一个批次中包含样本个数
batch_size = 3 # 计算每一轮epoch中含有的batch个数
batch_total = int(sample_num/batch_size)+1 # 生成4个数据和标签
def generate_data(sample_num=sample_num):
labels = np.asarray(range(0, sample_num))
images = np.random.random([sample_num, 224, 224, 3])
print('image size {},label size :{}'.format(images.shape, labels.shape)) return images,labels def get_batch_data(batch_size=batch_size):
images, label = generate_data() # 数据类型转换为tf.float32
images = tf.cast(images, tf.float32)
label = tf.cast(label, tf.int32) #从tensor列表中按顺序或随机抽取一个tensor
input_queue = tf.train.slice_input_producer([images, label], shuffle=False) image_batch, label_batch = tf.train.batch(input_queue, batch_size=batch_size, num_threads=1, capacity=64) return image_batch, label_batch image_batch, label_batch = get_batch_data(batch_size=batch_size) with tf.Session() as sess:
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess, coord)
try:
for i in range(epoch_num): # 每一轮迭代
print( '************' )
for j in range(batch_total): #每一个batch
print( '--------' )
# 获取每一个batch中batch_size个样本和标签
image_batch_v, label_batch_v = sess.run([image_batch, label_batch])
print(image_batch_v.shape, label_batch_v)
except tf.errors.OutOfRangeError:
print("done")
finally:
coord.request_stop()
coord.join(threads)
输出:

每次生成的batch中含有3个样本,不打乱次序,所以生成的tensor序列是按照‘0,1,2,3,4,0,1,2,3……’排列的。
如果设置每个batch中含有2个样本,打乱次序,即设置 batch_size = 2, tf.train.slice_input_producer函数中 shuffle=True,输出为:
# -*- coding:utf-8 -*-
import tensorflow as tf
import numpy as np # 样本个数
sample_num=5 # 设置迭代次数
epoch_num = 2 # 设置一个批次中包含样本个数
batch_size = 2 # 计算每一轮epoch中含有的batch个数
batch_total = int(sample_num/batch_size)+1 # 生成4个数据和标签
def generate_data(sample_num=sample_num):
labels = np.asarray(range(0, sample_num))
images = np.random.random([sample_num, 224, 224, 3])
print('image size {},label size :{}'.format(images.shape, labels.shape)) return images,labels def get_batch_data(batch_size=batch_size):
images, label = generate_data() # 数据类型转换为tf.float32
images = tf.cast(images, tf.float32)
label = tf.cast(label, tf.int32) #从tensor列表中按顺序或随机抽取一个tensor
input_queue = tf.train.slice_input_producer([images, label], shuffle=True) image_batch, label_batch = tf.train.batch(input_queue, batch_size=batch_size, num_threads=1, capacity=64) return image_batch, label_batch image_batch, label_batch = get_batch_data(batch_size=batch_size) with tf.Session() as sess:
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess, coord)
try:
for i in range(epoch_num): # 每一轮迭代
print( '************' )
for j in range(batch_total): #每一个batch
print( '--------' )
# 获取每一个batch中batch_size个样本和标签
image_batch_v, label_batch_v = sess.run([image_batch, label_batch])
print(image_batch_v.shape, label_batch_v)
except tf.errors.OutOfRangeError:
print("done")
finally:
coord.request_stop()
coord.join(threads)

与tf.train.batch函数相对的还有一个tf.train.shuffle_batch函数,两个函数作用一样,都是生成一定数量的tensor, 组成训练一个batch需要的数据集,区别是tf.train.shuffle_batch会打乱样本顺序。
【转载】 tensorflow中 tf.train.slice_input_producer 和 tf.train.batch 函数的更多相关文章
- tensorflow中 tf.train.slice_input_producer 和 tf.train.batch 函数(转)
tensorflow数据读取机制 tensorflow中为了充分利用GPU,减少GPU等待数据的空闲时间,使用了两个线程分别执行数据读入和数据计算. 具体来说就是使用一个线程源源不断的将硬盘中的图片数 ...
- tensorflow中 tf.train.slice_input_producer 和 tf.train.batch 函数
tensorflow数据读取机制 tensorflow中为了充分利用GPU,减少GPU等待数据的空闲时间,使用了两个线程分别执行数据读入和数据计算. 具体来说就是使用一个线程源源不断的将硬盘中的图片数 ...
- tensorflow数据读取机制tf.train.slice_input_producer 和 tf.train.batch 函数
tensorflow中为了充分利用GPU,减少GPU等待数据的空闲时间,使用了两个线程分别执行数据读入和数据计算. 具体来说就是使用一个线程源源不断的将硬盘中的图片数据读入到一个内存队列中,另一个线程 ...
- [转载]tensorflow中使用tf.ConfigProto()配置Session运行参数&&GPU设备指定
tf.ConfigProto()函数用在创建session的时候,用来对session进行参数配置: config = tf.ConfigProto(allow_soft_placement=True ...
- 【转载】 tf.train.slice_input_producer()和tf.train.batch()
原文地址: https://www.jianshu.com/p/8ba9cfc738c2 ------------------------------------------------------- ...
- tensorflow中使用变量作用域及tf.variable(),tf,getvariable()与tf.variable_scope()的用法
一 .tf.variable() 在模型中每次调用都会重建变量,使其存储相同变量而消耗内存,如: def repeat_value(): weight=tf.variable(tf.random_no ...
- [转载]Tensorflow中reduction_indices 的用法
Tensorflow中reduction_indices 的用法 默认时None 压缩成一维
- tensorflow中数据批次划分示例教程
1.简介 将数据划分成若干批次的数据,使用的函数主要有: tf.train.slice_input_producer(tensor_list,shuffle=True,seed=None,capaci ...
- TensorFlow中读取图像数据的三种方式
本文面对三种常常遇到的情况,总结三种读取数据的方式,分别用于处理单张图片.大量图片,和TFRecorder读取方式.并且还补充了功能相近的tf函数. 1.处理单张图片 我们训练完模型之后,常常要用图片 ...
随机推荐
- MySQL将某个数据库下的所有表的存储引擎修改为InnoDB类型语句
如何将mysql数据库中的MyISAM类型表更改为InnoDB类型的表 改单个表 ALTER TABLE TABLENAME ENGINE=InnoDB; ALTER TABLE TABLENAME ...
- Python爬取网页信息
Python爬取网页信息的步骤 以爬取英文名字网站(https://nameberry.com/)中每个名字的评论内容,包括英文名,用户名,评论的时间和评论的内容为例. 1.确认网址 在浏览器中输入初 ...
- zookeeper先验知识(2PC+paxos)
一.2PC两阶段提交: 在分布式事务中,每个机器节点只能够明确知道自己事务操作的结果,是成功还是失败,而无法获取其他分布式节点的操作结果,因此在事务操作需要跨多个分布式节点时,需要引入一个协调者统一调 ...
- 自用 微信小程序跳小程序
"window": { "navigationBarTextStyle": "black", "navigationBarTitl ...
- zabbix的历史数据存储到elasticsearch中
基本配置项 https://www.jianshu.com/p/bffca8128e8f 官方说这个实验性的功能支持es的版本是5.0.x - > 6.1.x,如果使用早期或更高版本的Elast ...
- C语言函数的定义和使用(2)
一:无参函数 类型说明符 get(){ //函数体 } 二:无参函数 类型说明符 getname(int a,int b){ //函数体 } 三:类型说明符包括: int ,char,float,do ...
- python时间序列数据的对齐和数据库的分批查询
欲直接下载代码文件,关注我们的公众号哦!查看历史消息即可! 0. 前言 在机器学习里,我们对时间序列数据做预处理的时候,经常会碰到一个问题:有多个时间序列存在多个表里,每个表的的时间轴不完全相同,要如 ...
- jvm指令手册查看
00-JVM指令手册 栈和局部变量操作 将常量压入栈的指令 aconst_null 将null对象引用压入栈 iconst_m1 将int类型常量-1压入栈 iconst_0 将int类型常量0压入栈 ...
- 坑:找到LoadRunner中Recording Options和 Run Time Settings配置选项确实的原因
在loadrunner安装好后,打开页面查看发现分别的缺失内容如下: 现象: 1. Recording Options 2.Run Time Settings 3.解决 原因是LR是付费的,你的安装包 ...
- Python里面如何生成随机数?
import randomrandom.random()它会返回一个随机的0和1之间的浮点数