python大数据工作流程
本文作者:hhh5460
大数据分析,内存不够用怎么办?
当然,你可以升级你的电脑为超级电脑。
另外,你也可以采用硬盘操作。
本文示范了硬盘操作的一种可能的方式。
本文基于:win10(64) + py3.5
本人电脑配置:4G内存
说明:
数据大小:5.6G
数据描述:自2010年以来,纽约的311投诉
数据来源:纽约开放数据官网(NYC's open data portal)
数据下载:https://data.cityofnewyork.us/api/views/erm2-nwe9/rows.csv?accessType=DOWNLOAD
import pandas as pd
import time '''python大数据分析工作流程'''
# 5G大数据文件,csv格式
reader = pd.read_csv('311_Service_Requests_from_2010_to_Present.csv', iterator=True, encoding='utf-8') # HDF5格式文件支持硬盘操作,不需要全部读入内存
store = pd.HDFStore('311_Service_Requests_from_2010_to_Present.h5') # 然后用迭代的方式转换.csv格式为.h5格式
chunkSize = 100000
i = 0
while True:
try:
start = time.clock() # 从csv文件迭代读取
df = reader.get_chunk(chunkSize) # 去除列名中的空格
df = df.rename(columns={c: c.replace(' ', '') for c in df.columns}) # 转换为日期时间格式
df['CreatedDate'] = pd.to_datetime(df['CreatedDate'])
df['ClosedDate'] = pd.to_datetime(df['ClosedDate']) # 感兴趣的列
columns = ['Agency', 'CreatedDate', 'ClosedDate', 'ComplaintType',
'Descriptor', 'TimeToCompletion', 'City']
# 不感兴趣的列
columns_for_drop = list(set(df.columns) - set(columns))
df.drop(columns_for_drop, inplace=True, axis=1, errors='ignore') # 转到h5文件
# 通过指定data_columns,建立额外的索引器,可提升查询速度
store.append('df', df, data_columns = ['ComplaintType', 'Descriptor', 'Agency']) # 计时
i += 1
end = time.clock()
print('{} 秒: completed {} rows'.format(end - start, i * chunksize))
except StopIteration:
print("Iteration is stopped.")
break # 转换完成之后,就可以选出想要进行数据分析的行,将其从硬盘导入到内存,如:
# 导入前三行
#store.select('df', "index<3") # 导入 ComplaintType, Descriptor, Agency这三列的前十行
#store.select('df', "index<10 & columns=['ComplaintType', 'Descriptor', 'Agency']") # 导入 ComplaintType, Descriptor, Agency这三列中满足Agency=='NYPD'的前十行
#store.select('df', "columns=['ComplaintType', 'Descriptor', 'Agency'] & Agency=='NYPD'").head(10) # 导入 ComplaintType, Descriptor, Agency这三列中满足Agency IN ('NYPD', 'DOB')的前十行
#store.select('df', "columns=['ComplaintType', 'Descriptor', 'Agency'] & Agency IN ('NYPD', 'DOB')")[:10] # ======================================
# 下面示范一个groupby操作
# 说明:由于数据太大,远超内存。因此无法全部导入内存。
# ======================================
# 硬盘操作:导入所有的 City 名称
cities = store.select_column('df','City').unique()
print("\ngroups:%s" % cities) # 循环读取 city
groups = []
for city in cities:
# 硬盘操作:按City名称选取
group = store.select('df', 'City=%s' % city) # 这里进行你想要的数据处理
groups.append(group[['ComplaintType', 'Descriptor', 'Agency']].sum()) print("\nresult:\n%s" % pd.concat(groups, keys = cities)) # 最后,记得关闭
store.close()
附:
运行过程中出现了一个错误
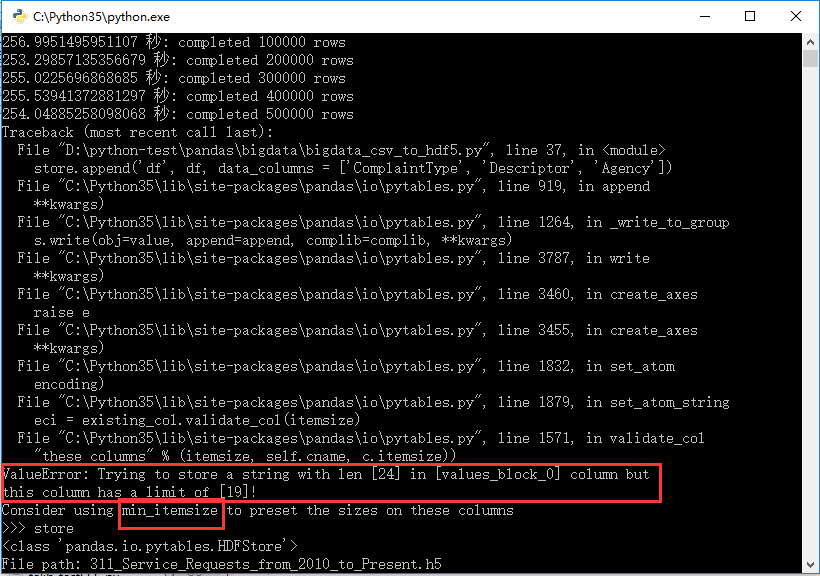
把上面的:
# 转到h5文件
# 通过指定data_columns,建立额外的索引器
store.append('df', df, data_columns = ['ComplaintType', 'Descriptor', 'Agency'])
改为:
# 转到h5文件
# 通过指定data_columns,建立额外的索引器
# 通过指定min_itemsize,设定存储混合类型长度
store.append('df', df, data_columns = ['ComplaintType', 'Descriptor', 'Agency'], min_itemsize = {'values': 50})
关于min_itemsize详情,见:http://pandas.pydata.org/pandas-docs/stable/io.html#storing-types
参考:
https://plot.ly/python/big-data-analytics-with-pandas-and-sqlite/
http://stackoverflow.com/questions/14262433/large-data-work-flows-using-pandas
http://python.jobbole.com/84118/
python大数据工作流程的更多相关文章
- 《零起点,python大数据与量化交易》
<零起点,python大数据与量化交易>,这应该是国内第一部,关于python量化交易的书籍. 有出版社约稿,写本量化交易与大数据的书籍,因为好几年没写书了,再加上近期"前海智库 ...
- 零起点Python大数据与量化交易
零起点Python大数据与量化交易 第1章 从故事开始学量化 1 1.1 亿万富翁的“神奇公式” 2 1.1.1 案例1-1:亿万富翁的“神奇公式” 2 1.1.2 案例分析:Python图表 5 1 ...
- 学习推荐《零起点Python大数据与量化交易》中文PDF+源代码
学习量化交易推荐学习国内关于Python大数据与量化交易的原创图书<零起点Python大数据与量化交易>. 配合zwPython开发平台和zwQuant开源量化软件学习,是一套完整的大数据 ...
- Python大数据与机器学习之NumPy初体验
本文是Python大数据与机器学习系列文章中的第6篇,将介绍学习Python大数据与机器学习所必须的NumPy库. 通过本文系列文章您将能够学到的知识如下: 应用Python进行大数据与机器学习 应用 ...
- Cookie&Seesion会话 共享数据 工作流程 持久化 Servlet三个作用域 会话机制
Day37 Cookie&Seesion会话 1.1.1 什么是cookie 当用户通过浏览器访问Web服务器时,服务器会给客户端发送一些信息,这些信息都保存在Cookie中.这样,当该浏览器 ...
- 零基础入门到精通:Python大数据与机器学习之Pandas-数据操作
在这里还是要推荐下我自己建的Python开发学习群:483546416,群里都是学Python开发的,如果你正在学习Python ,小编欢迎你加入,大家都是软件开发党,不定期分享干货(只有Python ...
- python大数据
http://blog.csdn.net/xnby/article/details/50782913 一句话总结:spark是一个基于内存的大数据计算框架, 上层包括了:Spark SQL类似Hive ...
- Python大数据应用
一.三国演义人物出场统计 先检查安装包 1.jieba库基本介绍 (1)jieba库概述 jieba是优秀的中文分词第三方库 中文文本需要通过分词获得单个的词语 jieba是优秀的中文分词第三方库,需 ...
- seo与python大数据结合给文本分词并提取高频词
最近研究seo和python如何结合,参考网上的一些资料,写的这个程序. 目的:分析某个行业(例如:圆柱模板)用户最关心的一些词,根据需求去自动调整TDK,以及栏目,内容页的规划 使用方法: 1.下载 ...
随机推荐
- IOS xib在tableview上的简单应用(通过xib自定义cell)
UITableView是一种常用的UI控件,在实际开发中,由于原生api的局限,自定义UITableViewCell十分重要,自定义cell可以通过代码,也可以通过xib. 这篇随笔介绍的是通过xib ...
- NSString的八条实用技巧
NSString的八条实用技巧 有一篇文章写了:iOS开发之NSString的几条实用技巧 , 今天这篇,我们讲讲NSString的八条实用技巧.大家可以收藏起来,方便开发随时可以复制粘贴. 0.首字 ...
- java 多线程断点下载demo
源码链接 import java.io.BufferedReader; import java.io.File; import java.io.FileInputStream; import java ...
- Android 之 自动匹配字符AutoCompleteTextView
AutoCompleteTextView是自动匹配字符,当我们输入一个单词或一段话的前几个字时,就会自动为你匹配后面的内容看效果图: 下面是代码: MainActivit: package com.e ...
- python 读写、创建 文件
python中对文件.文件夹(文件操作函数)的操作需要涉及到os模块和shutil模块. 得到当前工作目录,即当前Python脚本工作的目录路径: os.getcwd() 返回指定目录下的所有文件和目 ...
- 用C#实现RSS的生成和解析,支持RSS2.0和Atom格式
RSS已经非常流行了,几乎所有有点名气的和没名气的网站都有提供RSS服务. 本文详细教你什么是RSS,如是在.Net中使用RSS. 1.那么什么是RSS呢? RSS是一种消息来源格式规范,用以发布经常 ...
- JavaScript Patterns 3.3 Patterns for Enforcing new
When your constructor has something like this.member and you invoke the constructor without new, ...
- apache 开启zgip 压缩模式
一.Apache开启gzip压缩模式在目录apache\conf\httpd.conf 配置 httpd.conf 文件: #去掉LoadModule deflate_module modules/m ...
- 使用TRACE时 输出 _CrtDbgReport: String too long or IO Error
在VS2010中使用MFC,使用UNICODE 调用TRACE,输出_CrtDbgReport: String too long or IO Error 可尝试使用OutputDebugString函 ...
- 使用O_APPEND标志打开文件对文件进行lseek后进行读写的问题
fd = open("./newfile", O_RDWR|O_CREAT|O_APPEND, S_IRUSR|S_IWUSR); ) { perror("open&qu ...