k-means 算法介绍
概述
聚类属于机器学习的无监督学习,在数据中发现数据对象之间的关系,将数据进行分组,组内的相似性越大,组间的差别越大,则聚类效果越好。它跟分类的最主要区别就在于有没有“标签”。比如说我们有一组数据,数据对应着每个“标签”,我们通过这些数据与标签之间的相关性,预测出某些数据属于哪些“标签”,这属于分类;而聚类是没有“标签”的,因此说它属于无监督学习,分类则属于监督学习。
k-means(k-均值)属于聚类算法之一,笼统点说,它的过程是这样的,先设置参数k,通过欧式距离进行计算,从而将数据集分成k个簇。为了更好地理解这个算法,下面更加详细的介绍这个算法的思想。
算法思想
我们先过一下几个基本概念:
(1) K值:即要将数据分为几个簇;
(2) 质心:可理解为均值,即向量各个维度取平均值,这个是我们聚类算法一个重要的指标;
(3) 欧式距离: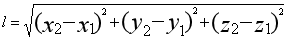
上面的这3条基本概念你大可不必太纠结,因为这是为了让你看下面的内容时,能够更好理解。假如说,我们现在有一堆数据集,在图像上的分布是这样的:

从图像上看,貌似可以直接把他分为3个簇,因此,我们设置 k=3,然后我们随机生成3个点,再通过欧式距离公式,计算每个点到这三个点之间的距离,距离哪个点最近的,就归类,于是它就变成了这样:
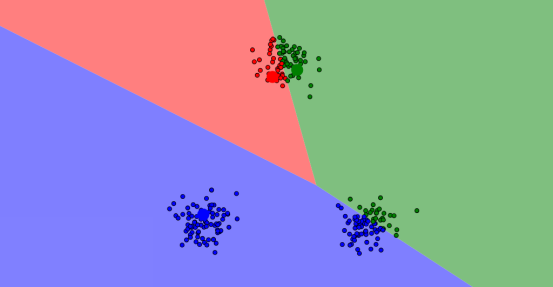
当然,这样还不够,毕竟这三个点只是随机生成的,而且我们还需要不断调整以达到更好的聚类效果;因此我们计算初次分好的簇的均值,即上面提到的质心,让这三个质心替代掉随机点,然后迭代重复上面的过程,以达到最优。

......(重复迭代n次)......
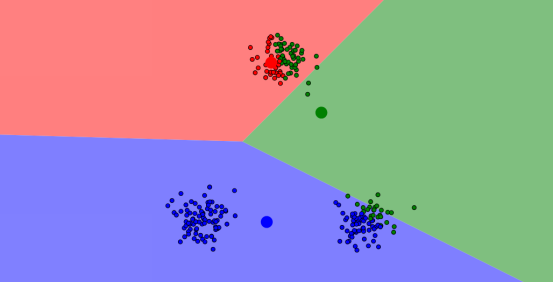
最后,才生成最优解,如图:
上面的图是在这个网站通过演示得到的,可以上这个网址实际操作一波,加深理解。
缺点
几乎每个算法都有其缺点,这个算法也不例外,优点是原理简单,实现容易,缺点如下:
(1)不规则点的聚类结果会有所偏差,如下图,比如我们想分成4个簇,俩眼睛一嘴巴以及外轮廓,但效果总是难以达到。
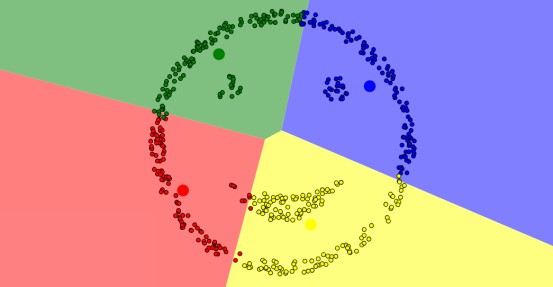
(2)k值难以确定。比如下面这样的图,应该把它从中间分割得到两块呢还是分成左中右三块呢,难以确定。
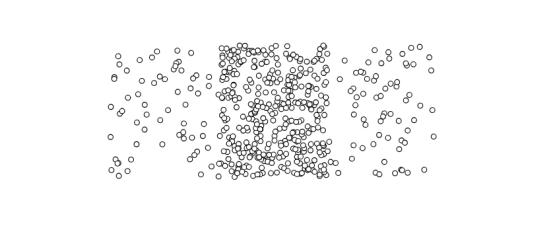
想要第一时间获取更多有意思的推文,可关注公众号: Max的日常操作

k-means 算法介绍的更多相关文章
- KNN 与 K - Means 算法比较
KNN K-Means 1.分类算法 聚类算法 2.监督学习 非监督学习 3.数据类型:喂给它的数据集是带label的数据,已经是完全正确的数据 喂给它的数据集是无label的数据,是杂乱无章的,经过 ...
- K-means算法
K-means算法很简单,它属于无监督学习算法中的聚类算法中的一种方法吧,利用欧式距离进行聚合啦. 解决的问题如图所示哈:有一堆没有标签的训练样本,并且它们可以潜在地分为K类,我们怎么把它们划分呢? ...
- FCM聚类算法介绍
FCM算法是一种基于划分的聚类算法,它的思想就是使得被划分到同一簇的对象之间相似度最大,而不同簇之间的相似度最小.模糊C均值算法是普通C均值算法的改进,普通C均值算法对于数据的划分是硬性的,而FCM则 ...
- 从K近邻算法谈到KD树、SIFT+BBF算法
转自 http://blog.csdn.net/v_july_v/article/details/8203674 ,感谢july的辛勤劳动 前言 前两日,在微博上说:“到今天为止,我至少亏欠了3篇文章 ...
- KNN算法介绍
KNN算法全名为k-Nearest Neighbor,就是K最近邻的意思. 算法描述 KNN是一种分类算法,其基本思想是采用测量不同特征值之间的距离方法进行分类. 算法过程如下: 1.准备样本数据集( ...
- 机器学习03:K近邻算法
本文来自同步博客. P.S. 不知道怎么显示数学公式以及排版文章.所以如果觉得文章下面格式乱的话请自行跳转到上述链接.后续我将不再对数学公式进行截图,毕竟行内公式截图的话排版会很乱.看原博客地址会有更 ...
- Python之常见算法介绍
一.算法介绍 1. 算法是什么 算法是指解题方案的准确而完整的描述,是一系列解决问题的清晰指令,算法代表着用系统的方法描述解决问题的策略机制.也就是说,能够对一定规范的输入,在有限时间内获得所要求的输 ...
- 机器学习(Machine Learning)算法总结-K临近算法
一.算法详解 1.什么是K临近算法 Cover 和 Hart在1968年提出了最初的临近算法 属于分类(classification)算法 邻近算法,或者说K最近邻(kNN,k-NearestNeig ...
- <转>从K近邻算法、距离度量谈到KD树、SIFT+BBF算法
转自 http://blog.csdn.net/likika2012/article/details/39619687 前两日,在微博上说:“到今天为止,我至少亏欠了3篇文章待写:1.KD树:2.神经 ...
- K中心点算法之PAM
一.PAM聚类算法: 选用簇中位置最中心的对象,试图对n个对象给出k个划分:代表对象也被称为是中心点,其他对象则被称为非代表对象:最初随机选择k个对象作为中心点,该算法反复地用非代表对 ...
随机推荐
- time machine不备份指定文件夹
osx中常常会使用timemachine来备份一些文件,timemachine能够使某个文件夹恢复到之前某个时刻的状态,很的方便.但是备份须要空间,特别是有些我们并不想备份一些无关紧要的文件,比方电影 ...
- Expression Tree 学习笔记(一)
大家可能都知道Expression Tree是.NET 3.5引入的新增功能.不少朋友们已经听说过这一特性,但还没来得及了解.看看博客园里的老赵等诸多牛人,将Expression Tree玩得眼花缭乱 ...
- phpExcel大数据量情况下内存溢出解决
版本:1.7.6+ 在不进行特殊设置的情况下,phpExcel将读取的单元格信息保存在内存中,我们可以通过 PHPExcel_Settings::setCacheStorageMethod() 来设置 ...
- ActiveMQ(三) 转
package pfs.y2017.m11.mq.activemq.demo03; import javax.jms.Connection; import javax.jms.ConnectionFa ...
- ios+Appium+Java
To run iOS tests, you can follow these steps : (Note : I am using Java language here in Eclipse IDE ...
- Boost源代码学习---weak_ptr.hpp
weak_ptr是辅助shared_ptr的智能指针. 就像它的名字一样.是个"弱"指针:仅有几个接口.仅能完毕非常少工作.它能够从一个shared_ptr或weak_ptr对象构 ...
- 【Android】Android聊天机器人实现
昨天看到一个Android视频教程讲图灵机器人.那个API接口用起来还是挺方便的,就准备自己动手做一个了. 另外自己还使用了高德地图的API接口用于定位(曾经用过高德的接口,比X度方便) 大体流程: ...
- BootStrap-DualListBox怎样改造成为双树
BootStrap-DualListBox能够实现将所选择的列表项显示到右边,未选的列表项显示到左边. 但是左右两边的下拉框中都是单级列表.如果要实现将两边都是树(缩进树),选择某个节点时,其子节点也 ...
- Golang 现有的哲学中,要求你尽量手工处理所有的错误返回
更优雅的 Golang 错误处理 - Go语言中文网 - Golang中文社区 https://studygolang.com/articles/9407
- java里类方法和实例方法
实例方法相对于静态方法(或者叫类方法)而言没有 static 前缀类般方法被对象拥有(也称之实例方法原因)特点定义时候前面没有 static 前缀本类直接调用时候必须也实例方法内否则调用前必须先实例出 ...