Python之机器学习-波斯顿房价预测
波士顿房价预测
导入模块
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib.font_manager import FontProperties
from sklearn.linear_model import LinearRegression
%matplotlib inline
font = FontProperties(fname='/Library/Fonts/Heiti.ttc')
获取数据
housing-data.txt文件可以加我微信获取:a1171958281
打印数据
df = pd.read_csv('housing-data.txt', sep='\s+', header=0)
df.head()
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| CRIM | ZN | INDUS | CHAS | NOX | RM | AGE | DIS | RAD | TAX | PTRATIO | B | LSTAT | MEDV | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.00632 | 18.0 | 2.31 | 0 | 0.538 | 6.575 | 65.2 | 4.0900 | 1 | 296.0 | 15.3 | 396.90 | 4.98 | 24.0 |
| 1 | 0.02731 | 0.0 | 7.07 | 0 | 0.469 | 6.421 | 78.9 | 4.9671 | 2 | 242.0 | 17.8 | 396.90 | 9.14 | 21.6 |
| 2 | 0.02729 | 0.0 | 7.07 | 0 | 0.469 | 7.185 | 61.1 | 4.9671 | 2 | 242.0 | 17.8 | 392.83 | 4.03 | 34.7 |
| 3 | 0.03237 | 0.0 | 2.18 | 0 | 0.458 | 6.998 | 45.8 | 6.0622 | 3 | 222.0 | 18.7 | 394.63 | 2.94 | 33.4 |
| 4 | 0.06905 | 0.0 | 2.18 | 0 | 0.458 | 7.147 | 54.2 | 6.0622 | 3 | 222.0 | 18.7 | 396.90 | 5.33 | 36.2 |
特征选择
散点图矩阵
使用sns库的pairplot()方法绘制的散点图矩阵可以查看数据集内部特征之间的关系,例如可以观察到特征间分布关系以及离群样本。
本文只绘制了三列(RM、MEDV(标记)、LSTAT)特征和标记之间的联系,有兴趣的可以调用该方法查看其它特征之间的关系。
# 选择三列特征
cols = ['RM', 'MEDV', 'LSTAT']
# 构造三列特征之间的联系即构造散点图矩阵
sns.pairplot(df[cols], height=3)
plt.tight_layout()
plt.show()

上图可以看出第一行(RM)第二列(MEDV)的特征与标记存在线性关系;第二行(MEDV)第二列(MEDV)即MEDV值可能呈正态分布。
关联矩阵
使用sns.heatmap()方法绘制的关联矩阵可以看出特征之间的相关性大小,关联矩阵是包含皮尔森积矩相关系数的正方形矩阵,用来度量特征对之间的线性依赖关系。
# 求解上述三列特征的相关系数
'''
对于一般的矩阵X,执行A=corrcoef(X)后,A中每个值的所在行a和列b,反应的是原矩阵X中相应的第a个列向量和第b个列向量的
相似程度(即相关系数)
'''
cm = np.corrcoef(df[cols].values.T)
# 控制颜色刻度即颜色深浅
sns.set(font_scale=2)
# 构造关联矩阵
hm = sns.heatmap(cm, cbar=True, annot=True, square=True, fmt='.2f', annot_kws={
'size': 20}, yticklabels=cols, xticklabels=cols)
plt.show()
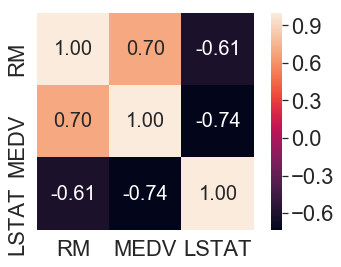
上图可以看出特征LSTAT和标记MEDV的具有最高的相关性-0.74,但是在散点图矩阵中会发现LSTAT和MEDV之间存在着明显的非线性关系;而特征RM和标记MEDV也具有较高的相关性0.70,并且从散点矩阵中会发现特征RM和标记MEDV之间存在着线性关系。因此接下来将使用RM作为线性回归模型的特征。
训练模型
X = df[['RM']].values
y = df['MEDV'].values
lr = LinearRegression()
lr.fit(X, y)
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=None,
normalize=False)
可视化
plt.scatter(X, y, c='r', s=30, edgecolor='white',label='训练数据')
plt.plot(X, lr.predict(X), c='g')
plt.xlabel('平均房间数目[MEDV]', fontproperties=font)
plt.ylabel('以1000美元为计价单位的房价[RM]', fontproperties=font)
plt.title('波士顿房价预测', fontproperties=font, fontsize=20)
plt.legend(prop=font)
plt.show()
print('普通线性回归斜率:{}'.format(lr.coef_[0]))
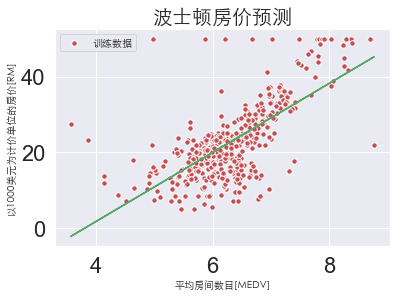
普通线性回归斜率:9.10210898118031
使用RANSAC算法之后可以发现线性回归拟合的线与未用RANSAC算法拟合出来的线的斜率不同,可以说RANSAC算法降低了离群值潜在的影响,但是这并不能说明这种方法对未来新数据的预测性能是否有良性影响。
Python之机器学习-波斯顿房价预测的更多相关文章
- 02-11 RANSAC算法线性回归(波斯顿房价预测)
目录 RANSAC算法线性回归(波斯顿房价预测) 一.RANSAC算法流程 二.导入模块 三.获取数据 四.训练模型 五.可视化 更新.更全的<机器学习>的更新网站,更有python.go ...
- 【udacity】机器学习-波士顿房价预测小结
Evernote Export 机器学习的运行步骤 1.导入数据 没什么注意的,成功导入数据集就可以了,打印看下数据的标准格式就行 用个info和describe 2.分析数据 这里要详细分析数据的内 ...
- 【udacity】机器学习-波士顿房价预测
import numpy as np import pandas as pd from Udacity.model_check.boston_house_price import visuals as ...
- 波士顿房价预测 - 最简单入门机器学习 - Jupyter
机器学习入门项目分享 - 波士顿房价预测 该分享源于Udacity机器学习进阶中的一个mini作业项目,用于入门非常合适,刨除了繁琐的部分,保留了最关键.基本的步骤,能够对机器学习基本流程有一个最清晰 ...
- 机器学习实战二:波士顿房价预测 Boston Housing
波士顿房价预测 Boston housing 这是一个波士顿房价预测的一个实战,上一次的Titantic是生存预测,其实本质上是一个分类问题,就是根据数据分为1或为0,这次的波士顿房价预测更像是预测一 ...
- 使用pmml跨平台部署机器学习模型Demo——房价预测
基于房价数据,在python中训练得到一个线性回归的模型,在JavaWeb中加载模型完成房价预测的功能. 一. 训练.保存模型 工具:PyCharm-2017.Python-39.sklearn2 ...
- Python——决策树实战:california房价预测
Python——决策树实战:california房价预测 编译环境:Anaconda.Jupyter Notebook 首先,导入模块: import pandas as pd import matp ...
- 掌握Spark机器学习库-07.14-保序回归算法实现房价预测
数据集 house.csv 数据集概览 代码 package org.apache.spark.examples.examplesforml import org.apache.spark.ml.cl ...
- python实现机器学习笔记
#课程链接 https://www.imooc.com/video/20165 一.机器学习介绍以及环境部署 1.机器学习介绍及其原理 1)什么是人工智能 人工智能就其本质而言,是机器对人的思维信息过 ...
随机推荐
- springboot(七) 配置嵌入式Servlet容器
github代码地址:https://github.com/showkawa/springBoot_2017/tree/master/spb-demo/spb-brian-query-service ...
- Neighbor House LightOJ - 1047
Neighbor House LightOJ - 1047 #include<cstdio> #include<cstring> #include<algorithm&g ...
- 贪心 Codeforces Round #236 (Div. 2) A. Nuts
题目传送门 /* 贪心:每一次选取最多的线段,最大能放置nuts,直到放完为止,很贪婪! 题目读不懂多读几遍:) */ #include <cstdio> #include <alg ...
- 【LeetCode】297. Serialize and Deserialize Binary Tree
二叉树的序列化与反序列化. 如果使用string作为媒介来存储,传递序列化结果的话,会给反序列话带来很多不方便. 这里学会了使用 sstream 中的 输入流'istringstream' 和 输出流 ...
- hihocoder1705 座位问题
思路: 使用堆模拟.复习了priority_queue自定义结构体比较函数的用法. 实现: #include <bits/stdc++.h> using namespace std; ty ...
- 11 Hash tables
11 Hash tables Many applications require a dynamic set that supports only the dictionary operatio ...
- YOLO模型对图片中车辆的识别比对
1,模型对比结果 ² 标准Yolo v3模型 ² 标准Yolo v3 tiny模型 ² 标准Yolo v2 tiny模型 ² 用户训练yolo ...
- v使用索引的注意事项及常见场景、案例
索引的原理与作用,各种书籍和网络上的介绍可以说是铺天盖地,基本上主流数据库系统的也都是一致的.选择索引字段的原则,比如外键字段.数据类型较小的字段.经常用于查询或排序的字段.表关联的字段等等,在此不做 ...
- uoj #15. 【NOIP2014】生活大爆炸版石头剪刀布
石头剪刀布是常见的猜拳游戏:石头胜剪刀,剪刀胜布,布胜石头.如果两个人出拳一 样,则不分胜负.在<生活大爆炸>第二季第 8 集中出现了一种石头剪刀布的升级版游戏. 升级版游戏在传统的石头剪 ...
- MySql 基础知识-常用命令及sql语句
一.常用mysql命令行命令 1,启动mysql服务 net start mysql. 停止mysql服务 net stop mysql 2,netstart -na|findstr 330 ...