使用hadoop mapreduce分析mongodb数据
使用hadoop mapreduce分析mongodb数据
(现在很多互联网爬虫将数据存入mongdb中,所以研究了一下,写此文档)
版权声明:本文为yunshuxueyuan原创文章。
如需转载请标明出处: http://www.cnblogs.com/sxt-zkys/
QQ技术交流群:299142667
一、 mongdb的安装和使用
1、 官网下载mongodb-linux-x86_64-rhel70-3.2.9.tgz

2、 解压 (可以配置一下环境变量)
3、 启动服务端
./mongod --dbpath=/opt/local/mongodb/data --logpath=/opt/local/mongodb/logs --logappend --fork(后台启动)
第一种:不带auth认证的
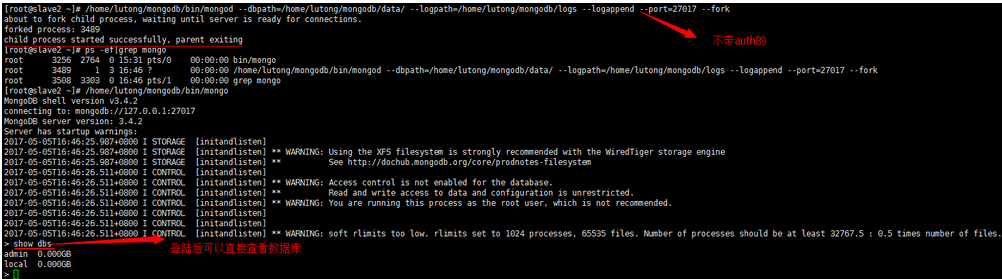
第二种:需要带auth认证的(即需要用户名和密码的)
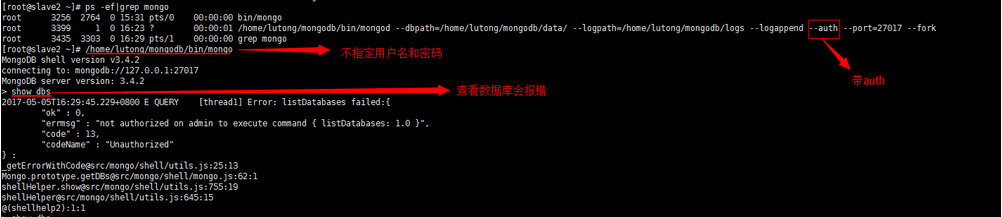
当指定用户名和密码在查看数据,发现就可以看得到了

4、 启动客户端
./mongo

5、客户端shell命令
show dbs 显示mongodb中有哪些数据库
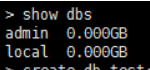
db 显示当前正在用的数据库
use db 你要使用的数据库名
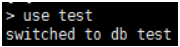
(注:若database不存在,则会创建一个,此时若不做任何操作直接退出,则MongoDB会删除该数据库)
db.auth(username,password) username为用户名,password为密码 登陆你要使用的数据库
db.getCollectionNames() 查看当前数据库有哪些表

db.[collectionName].insert({...}) 给指定数据库添加文档记录

db.[collectionName].findOne() 查找文档的第一条数据
db.[collectionName].find() 查找文档的全部记录

db.[collection].update({查询条件},{$set:{更新内容}}) 更新一条文档记录

db.[collection].drop() 删除数据库中的集合

db.dropDatabase() 删除数据库
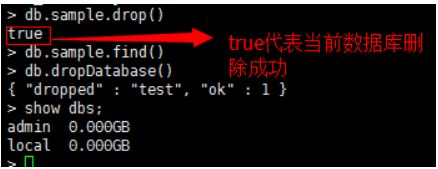
二、 Mapreduce 分析mongodb的数据实例
1、 编写mapreduce的代码前,需要另外添加两个jar包,还有需(jdk1.7以上)


2、 需求介绍与实现
原数据:

结果数据:

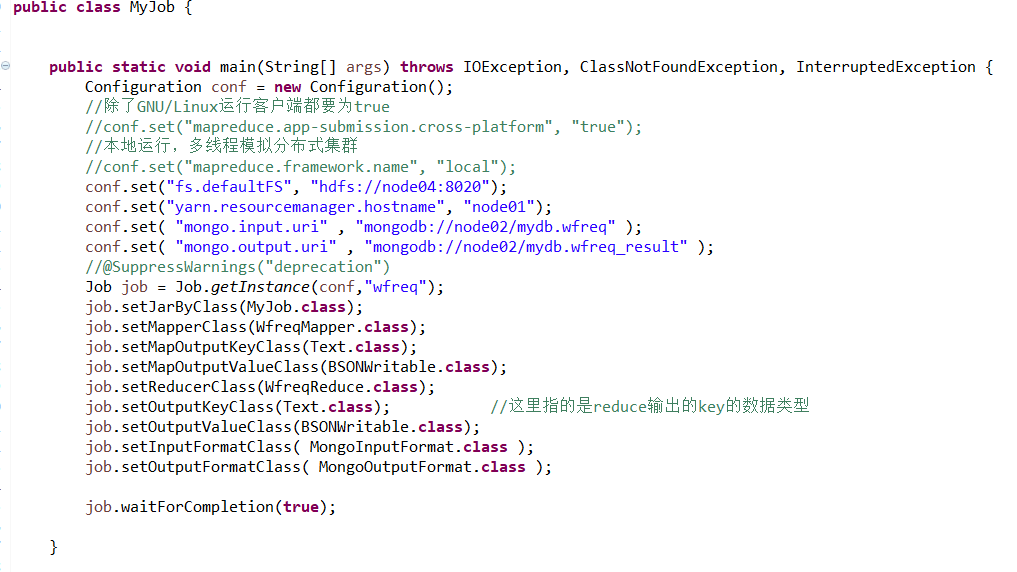
代码编写:
Job:
Mapper:

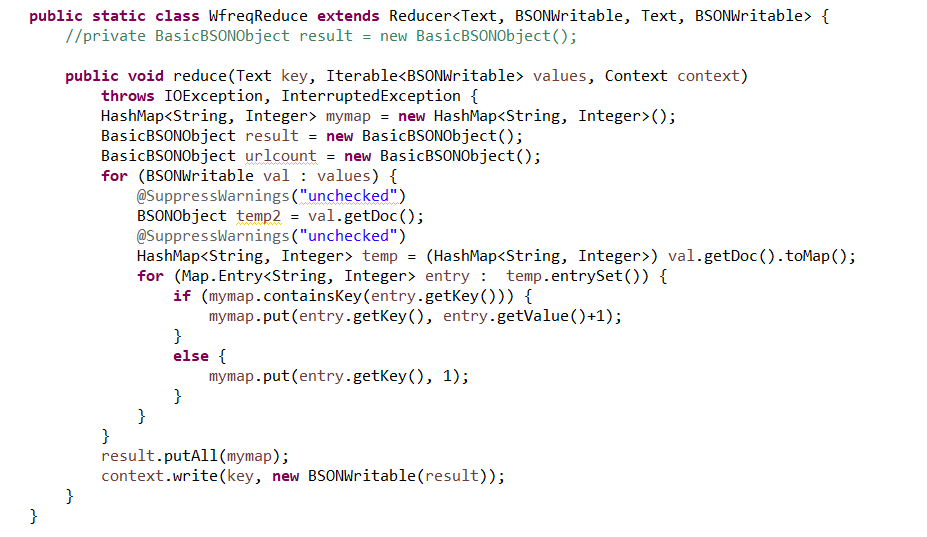
Reduce:
最终的结果数据:
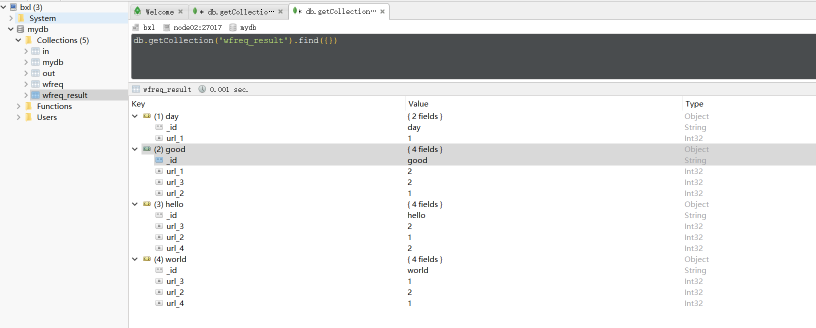
三、 最后给大家推荐一个mongodb数据库的管理工具,挺好用的

版权声明:本文为yunshuxueyuan原创文章。
如需转载请标明出处: http://www.cnblogs.com/sxt-zkys/
QQ技术交流群:299142667
使用hadoop mapreduce分析mongodb数据的更多相关文章
- Hadoop+Hive 操作mongodb数据
Hadoop+Hive 操作mongodb数据 1.版本概述 hadoop-2.7.3.hive-2.2 下载响应的jar包:http://mvnrepository.com/,直接搜索想要的jar包 ...
- hadoop —— MapReduce例子 (数据排序)
参考:http://eric-gcm.iteye.com/blog/1807468 file1.txt: 2 32 654 32 15 756 65223 file2.txt: 5956 22 650 ...
- hadoop —— MapReduce例子 (数据去重)
参考:http://eric-gcm.iteye.com/blog/1807468 例子1: 概要:数据去重 描述:将file1.txt.file2.txt中的数据合并到一个文件中的同时去掉重复的内容 ...
- MapReduce分析明星微博数据
互联网时代的到来,使得名人的形象变得更加鲜活,也拉近了明星和粉丝之间的距离.歌星.影星.体育明星.作家等名人通过互联网能够轻易实现和粉丝的互动,赚钱也变得前所未有的简单.同时,互联网的飞速发展本身也造 ...
- 【Big Data - Hadoop - MapReduce】初学Hadoop之图解MapReduce与WordCount示例分析
Hadoop的框架最核心的设计就是:HDFS和MapReduce.HDFS为海量的数据提供了存储,MapReduce则为海量的数据提供了计算. HDFS是Google File System(GFS) ...
- Hadoop MapReduce执行过程实例分析
1.MapReduce是如何执行任务的?2.Mapper任务是怎样的一个过程?3.Reduce是如何执行任务的?4.键值对是如何编号的?5.实例,如何计算没见最高气温? 分析MapReduce执行过程 ...
- hadoop mapreduce实现数据去重
实现原理分析: map函数数将输入的文本按照行读取, 并将Key--每一行的内容 输出 value--空. reduce 会自动统计所有的key,我们让reduce输出key-> ...
- Hadoop 中利用 mapreduce 读写 mysql 数据
Hadoop 中利用 mapreduce 读写 mysql 数据 有时候我们在项目中会遇到输入结果集很大,但是输出结果很小,比如一些 pv.uv 数据,然后为了实时查询的需求,或者一些 OLAP ...
- hadoop学习;block数据块;mapreduce实现样例;UnsupportedClassVersionError异常;关联项目源代码
对于开源的东东,尤其是刚出来不久,我认为最好的学习方式就是能够看源代码和doc,測试它的样例 为了方便查看源代码,关联导入源代码的项目 先前的项目导入源代码是关联了源代码文件 block数据块,在配置 ...
随机推荐
- Linux修改文件的权限,拥有者,所属组
修改文件的权限,拥有者,所属组 1.设置文件的权限(chmod) ①方式一(建议使用这种方式) 命名:chomd 755 文件名 ②方式二 命名:chomd -R +x 文件名 2.设置文件的拥有者( ...
- 题解报告:poj 2631 Roads in the North(最长链)
Description Building and maintaining roads among communities in the far North is an expensive busine ...
- 1-20StringBuffer简介
StringBuffer是一个字符串缓冲区,如果需要频繁的对字符串进行拼接时,建议使用StringBuffer. 工作原理 StringBuffer的底层是char数组,如果没有明确设定,则系统会默认 ...
- c#学习系列之关键字where
where 子句用于指定类型约束,这些约束可以作为泛型声明中定义的类型参数的变量. 1.接口约束. 例如,可以声明一个泛型类 MyGenericClass,这样,类型参数 T 就 ...
- 在input标签里只能输入数字
<input type='text' onkeyup="(this.v=function(){this.value=this.value.replace(/[^0-9-]+/,''); ...
- 页面html图片按钮多种写法
原地址:http://blog.163.com/weison_hi/blog/static/17680404720118534033788/ 第一种: 在一般情况下按钮提交表单: <form i ...
- JVM(HotSpot)7种垃圾收集器
JVM(HotSpot)7种垃圾收集器 7种垃圾收集器作用于不同的分代,如果两个收集器之间存在连续,就说明他们可以搭配使用. 从JDK1.3到现在,从Serial收集器->Parallel收集器 ...
- ES-自然语言处理之中文分词器
前言 中文分词是中文文本处理的一个基础步骤,也是中文人机自然语言交互的基础模块.不同于英文的是,中文句子中没有词的界限,因此在进行中文自然语言处理时,通常需要先进行分词,分词效果将直接影响词性.句法树 ...
- vue中引入字体图标报错,找不到字体文件
在用vue + webpack进行开发的时候,在引用字体图标遇到字体无法加载的问题: 报以下错误 搞了好久没搞定,最后才找到解决方法(还是没有找到原因) 修改字体图标的css中引入字体文件的路径 以前 ...
- ES6学习笔记(3)----字符串的扩展
参考书<ECMAScript 6入门>http://es6.ruanyifeng.com/ 字符串的扩展ES6之前只能识别\u0000 - \uFFFF 之间的字符,超过此范围,识别会出错 ...