使用hadoop mapreduce分析mongodb数据
使用hadoop mapreduce分析mongodb数据
(现在很多互联网爬虫将数据存入mongdb中,所以研究了一下,写此文档)
版权声明:本文为yunshuxueyuan原创文章。
如需转载请标明出处: http://www.cnblogs.com/sxt-zkys/
QQ技术交流群:299142667
一、 mongdb的安装和使用
1、 官网下载mongodb-linux-x86_64-rhel70-3.2.9.tgz

2、 解压 (可以配置一下环境变量)
3、 启动服务端
./mongod --dbpath=/opt/local/mongodb/data --logpath=/opt/local/mongodb/logs --logappend --fork(后台启动)
第一种:不带auth认证的
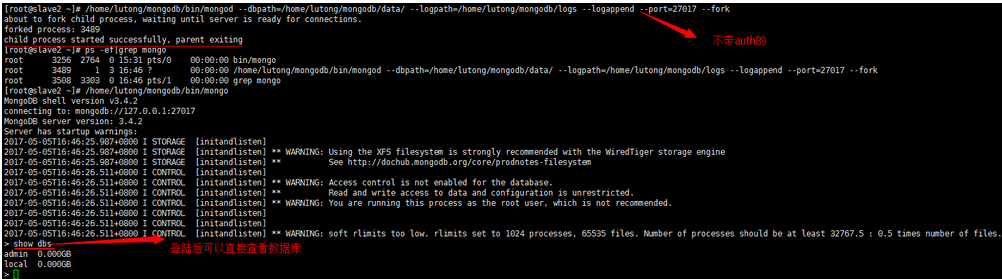
第二种:需要带auth认证的(即需要用户名和密码的)
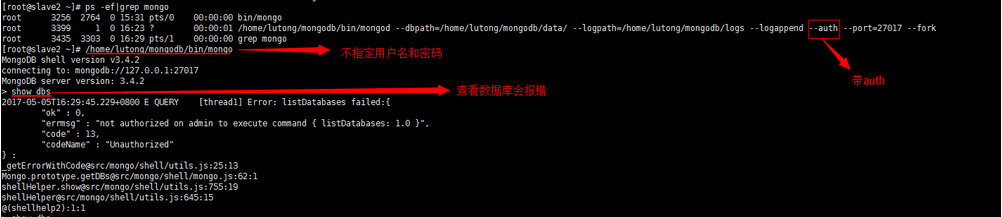
当指定用户名和密码在查看数据,发现就可以看得到了

4、 启动客户端
./mongo

5、客户端shell命令
show dbs 显示mongodb中有哪些数据库
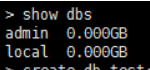
db 显示当前正在用的数据库
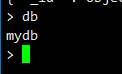
use db 你要使用的数据库名
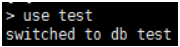
(注:若database不存在,则会创建一个,此时若不做任何操作直接退出,则MongoDB会删除该数据库)
db.auth(username,password) username为用户名,password为密码 登陆你要使用的数据库
db.getCollectionNames() 查看当前数据库有哪些表

db.[collectionName].insert({...}) 给指定数据库添加文档记录

db.[collectionName].findOne() 查找文档的第一条数据
db.[collectionName].find() 查找文档的全部记录

db.[collection].update({查询条件},{$set:{更新内容}}) 更新一条文档记录

db.[collection].drop() 删除数据库中的集合

db.dropDatabase() 删除数据库
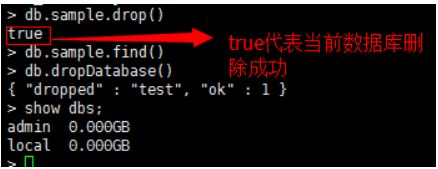
二、 Mapreduce 分析mongodb的数据实例
1、 编写mapreduce的代码前,需要另外添加两个jar包,还有需(jdk1.7以上)


2、 需求介绍与实现
原数据:

结果数据:

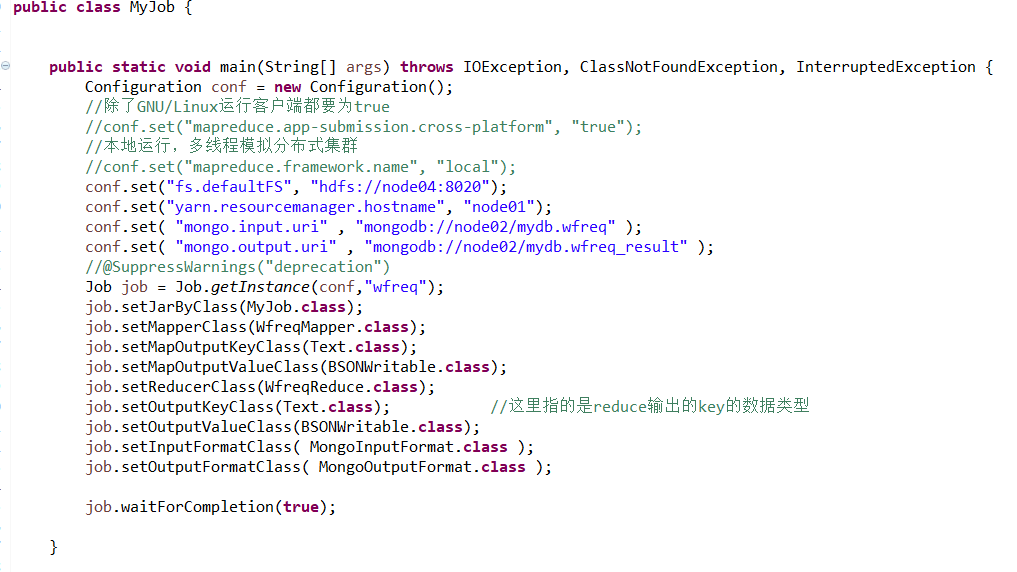
代码编写:
Job:
Mapper:

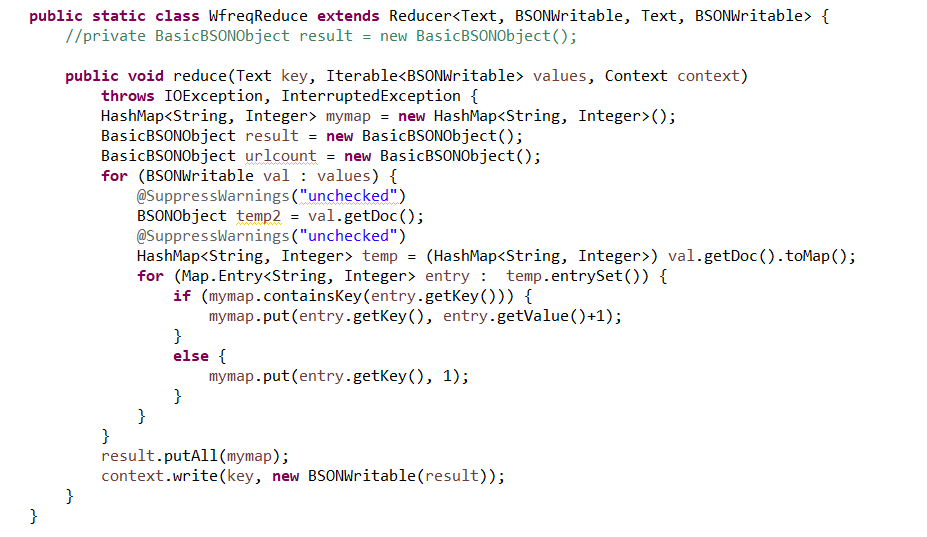
Reduce:
最终的结果数据:
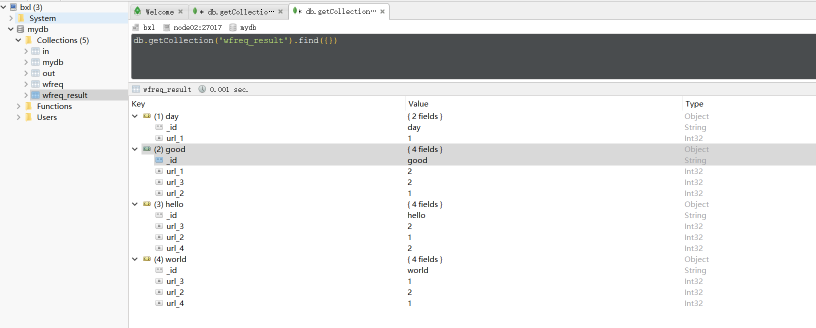
三、 最后给大家推荐一个mongodb数据库的管理工具,挺好用的

版权声明:本文为yunshuxueyuan原创文章。
如需转载请标明出处: http://www.cnblogs.com/sxt-zkys/
QQ技术交流群:299142667
使用hadoop mapreduce分析mongodb数据的更多相关文章
- Hadoop+Hive 操作mongodb数据
Hadoop+Hive 操作mongodb数据 1.版本概述 hadoop-2.7.3.hive-2.2 下载响应的jar包:http://mvnrepository.com/,直接搜索想要的jar包 ...
- hadoop —— MapReduce例子 (数据排序)
参考:http://eric-gcm.iteye.com/blog/1807468 file1.txt: 2 32 654 32 15 756 65223 file2.txt: 5956 22 650 ...
- hadoop —— MapReduce例子 (数据去重)
参考:http://eric-gcm.iteye.com/blog/1807468 例子1: 概要:数据去重 描述:将file1.txt.file2.txt中的数据合并到一个文件中的同时去掉重复的内容 ...
- MapReduce分析明星微博数据
互联网时代的到来,使得名人的形象变得更加鲜活,也拉近了明星和粉丝之间的距离.歌星.影星.体育明星.作家等名人通过互联网能够轻易实现和粉丝的互动,赚钱也变得前所未有的简单.同时,互联网的飞速发展本身也造 ...
- 【Big Data - Hadoop - MapReduce】初学Hadoop之图解MapReduce与WordCount示例分析
Hadoop的框架最核心的设计就是:HDFS和MapReduce.HDFS为海量的数据提供了存储,MapReduce则为海量的数据提供了计算. HDFS是Google File System(GFS) ...
- Hadoop MapReduce执行过程实例分析
1.MapReduce是如何执行任务的?2.Mapper任务是怎样的一个过程?3.Reduce是如何执行任务的?4.键值对是如何编号的?5.实例,如何计算没见最高气温? 分析MapReduce执行过程 ...
- hadoop mapreduce实现数据去重
实现原理分析: map函数数将输入的文本按照行读取, 并将Key--每一行的内容 输出 value--空. reduce 会自动统计所有的key,我们让reduce输出key-> ...
- Hadoop 中利用 mapreduce 读写 mysql 数据
Hadoop 中利用 mapreduce 读写 mysql 数据 有时候我们在项目中会遇到输入结果集很大,但是输出结果很小,比如一些 pv.uv 数据,然后为了实时查询的需求,或者一些 OLAP ...
- hadoop学习;block数据块;mapreduce实现样例;UnsupportedClassVersionError异常;关联项目源代码
对于开源的东东,尤其是刚出来不久,我认为最好的学习方式就是能够看源代码和doc,測试它的样例 为了方便查看源代码,关联导入源代码的项目 先前的项目导入源代码是关联了源代码文件 block数据块,在配置 ...
随机推荐
- 转 OGG Troubleshooting-Database error 1 (ORA-00001: unique constraint ...)
Q5: After imp data to target, when we start replc process, we find the following error: 2011-11-10 0 ...
- ASP.NET Web API FilterAttribute假想
偶然的测试发现API FilterAttribute没用引用只会初始化一次 比如: 如果是 Global Action Filter, 则全局只会初始化一次 针对于不同的Controller级别的Ac ...
- lavarel功能总结
详细可参见笔记:laraval学习笔记(二) 路由 route 绑定模型,绑定参数 模版 blade .blade.php后缀,有laravel自己的模版语法 模型 model 如果用create创建 ...
- [转]Qt 5.5 操作 Excel 的速度 效率问题
转自:http://blog.csdn.net/li494816491/article/details/50274305 1. QAxObject *_excelObject1 =newQAxObje ...
- css3纯手写loading效果
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- 8.3.3 快速系统调用 —— XP SP3上SystemCallStub的奇怪问题
依书上的例子,ReadFile()函数会调用ntdll!NtReadFile(),后者将服务号放到eax之中,然后调用SharedUserData!SystemCallStub(),由此函数执行sys ...
- 如何破解密码的哈希值,破解双MD5密码值
这是关于我如何破解密码的哈希值1亿2200万* John the Ripper和oclHashcat-plus故事. 这是几个月前,当我看到一条推特:从korelogic约含共1亿4600万个密码的密 ...
- app自动化配置信息
caps={ "platformName":"Android",#平台名称 "platformVersion":"6. ...
- 【软件构造】第三章第三节 抽象数据型(ADT)
第三章第三节 抽象数据型(ADT) 3-1节研究了“数据类型”及其特性 ; 3-2节研究了方法和操作的“规约”及其特性:在本节中,我们将数据和操作复合起来,构成ADT,学习ADT的核心特征,以及如何设 ...
- 任务二:零基础HTML及CSS编码(一)
面向人群: 零基础或初学者 难度: 简单 重要说明 百度前端技术学院的课程任务是由百度前端工程师专为对前端不同掌握程度的同学设计.我们尽力保证课程内容的质量以及学习难度的合理性,但即使如此,真正决定课 ...