[python] ThreadPoolExecutor线程池
初识
Python中已经有了threading模块,为什么还需要线程池呢,线程池又是什么东西呢?在介绍线程同步的信号量机制的时候,举得例子是爬虫的例子,需要控制同时爬取的线程数,例子中创建了20个线程,而同时只允许3个线程在运行,但是20个线程都需要创建和销毁,线程的创建是需要消耗系统资源的,有没有更好的方案呢?其实只需要三个线程就行了,每个线程各分配一个任务,剩下的任务排队等待,当某个线程完成了任务的时候,排队任务就可以安排给这个线程继续执行。
这就是线程池的思想(当然没这么简单),但是自己编写线程池很难写的比较完美,还需要考虑复杂情况下的线程同步,很容易发生死锁。从Python3.2开始,标准库为我们提供了concurrent.futures模块,它提供了ThreadPoolExecutor和ProcessPoolExecutor两个类,实现了对threading和multiprocessing的进一步抽象(这里主要关注线程池),不仅可以帮我们自动调度线程,还可以做到:
- 主线程可以获取某一个线程(或者任务的)的状态,以及返回值。
- 当一个线程完成的时候,主线程能够立即知道。
- 让多线程和多进程的编码接口一致。
实例
简单使用
from concurrent.futures import ThreadPoolExecutor
import time
# 参数times用来模拟网络请求的时间
def get_html(times):
time.sleep(times)
print("get page {}s finished".format(times))
return times
executor = ThreadPoolExecutor(max_workers=2)
# 通过submit函数提交执行的函数到线程池中,submit函数立即返回,不阻塞
task1 = executor.submit(get_html, (3))
task2 = executor.submit(get_html, (2))
# done方法用于判定某个任务是否完成
print(task1.done())
# cancel方法用于取消某个任务,该任务没有放入线程池中才能取消成功
print(task2.cancel())
time.sleep(4)
print(task1.done())
# result方法可以获取task的执行结果
print(task1.result())
# 执行结果
# False # 表明task1未执行完成
# False # 表明task2取消失败,因为已经放入了线程池中
# get page 2s finished
# get page 3s finished
# True # 由于在get page 3s finished之后才打印,所以此时task1必然完成了
# 3 # 得到task1的任务返回值
ThreadPoolExecutor构造实例的时候,传入max_workers参数来设置线程池中最多能同时运行的线程数目。- 使用
submit函数来提交线程需要执行的任务(函数名和参数)到线程池中,并返回该任务的句柄(类似于文件、画图),注意submit()不是阻塞的,而是立即返回。 - 通过
submit函数返回的任务句柄,能够使用done()方法判断该任务是否结束。上面的例子可以看出,由于任务有2s的延时,在task1提交后立刻判断,task1还未完成,而在延时4s之后判断,task1就完成了。 - 使用
cancel()方法可以取消提交的任务,如果任务已经在线程池中运行了,就取消不了。这个例子中,线程池的大小设置为2,任务已经在运行了,所以取消失败。如果改变线程池的大小为1,那么先提交的是task1,task2还在排队等候,这是时候就可以成功取消。 - 使用
result()方法可以获取任务的返回值。查看内部代码,发现这个方法是阻塞的。
as_completed
上面虽然提供了判断任务是否结束的方法,但是不能在主线程中一直判断啊。有时候我们是得知某个任务结束了,就去获取结果,而不是一直判断每个任务有没有结束。这是就可以使用as_completed方法一次取出所有任务的结果。
from concurrent.futures import ThreadPoolExecutor, as_completed
import time
# 参数times用来模拟网络请求的时间
def get_html(times):
time.sleep(times)
print("get page {}s finished".format(times))
return times
executor = ThreadPoolExecutor(max_workers=2)
urls = [3, 2, 4] # 并不是真的url
all_task = [executor.submit(get_html, (url)) for url in urls]
for future in as_completed(all_task):
data = future.result()
print("in main: get page {}s success".format(data))
# 执行结果
# get page 2s finished
# in main: get page 2s success
# get page 3s finished
# in main: get page 3s success
# get page 4s finished
# in main: get page 4s success
as_completed()方法是一个生成器,在没有任务完成的时候,会阻塞,在有某个任务完成的时候,会yield这个任务,就能执行for循环下面的语句,然后继续阻塞住,循环到所有的任务结束。从结果也可以看出,先完成的任务会先通知主线程。
map
除了上面的as_completed方法,还可以使用executor.map方法,但是有一点不同。
from concurrent.futures import ThreadPoolExecutor
import time
# 参数times用来模拟网络请求的时间
def get_html(times):
time.sleep(times)
print("get page {}s finished".format(times))
return times
executor = ThreadPoolExecutor(max_workers=2)
urls = [3, 2, 4] # 并不是真的url
for data in executor.map(get_html, urls):
print("in main: get page {}s success".format(data))
# 执行结果
# get page 2s finished
# get page 3s finished
# in main: get page 3s success
# in main: get page 2s success
# get page 4s finished
# in main: get page 4s success
使用map方法,无需提前使用submit方法,map方法与python标准库中的map含义相同,都是将序列中的每个元素都执行同一个函数。上面的代码就是对urls的每个元素都执行get_html函数,并分配各线程池。可以看到执行结果与上面的as_completed方法的结果不同,输出顺序和urls列表的顺序相同,就算2s的任务先执行完成,也会先打印出3s的任务先完成,再打印2s的任务完成。
wait
wait方法可以让主线程阻塞,直到满足设定的要求。
from concurrent.futures import ThreadPoolExecutor, wait, ALL_COMPLETED, FIRST_COMPLETED
import time
# 参数times用来模拟网络请求的时间
def get_html(times):
time.sleep(times)
print("get page {}s finished".format(times))
return times
executor = ThreadPoolExecutor(max_workers=2)
urls = [3, 2, 4] # 并不是真的url
all_task = [executor.submit(get_html, (url)) for url in urls]
wait(all_task, return_when=ALL_COMPLETED)
print("main")
# 执行结果
# get page 2s finished
# get page 3s finished
# get page 4s finished
# main
wait方法接收3个参数,等待的任务序列、超时时间以及等待条件。等待条件return_when默认为ALL_COMPLETED,表明要等待所有的任务都结束。可以看到运行结果中,确实是所有任务都完成了,主线程才打印出main。等待条件还可以设置为FIRST_COMPLETED,表示第一个任务完成就停止等待。
源码分析
cocurrent.future模块中的future的意思是未来对象,可以把它理解为一个在未来完成的操作,这是异步编程的基础 。在线程池submit()之后,返回的就是这个future对象,返回的时候任务并没有完成,但会在将来完成。也可以称之为task的返回容器,这个里面会存储task的结果和状态。那ThreadPoolExecutor内部是如何操作这个对象的呢?
下面简单介绍ThreadPoolExecutor的部分代码:
init方法
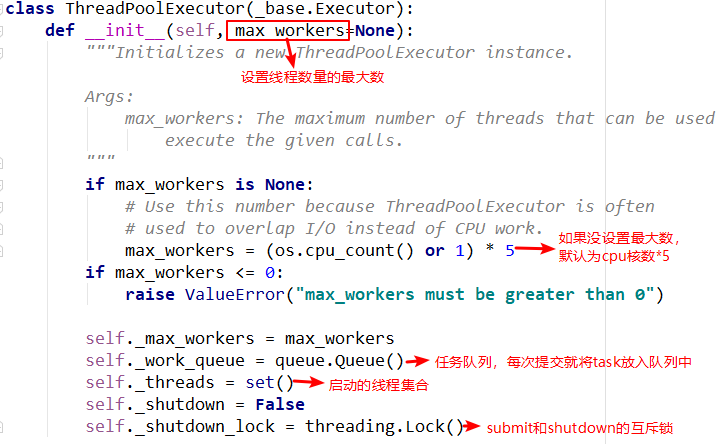
init方法中主要重要的就是任务队列和线程集合,在其他方法中需要使用到。submit方法
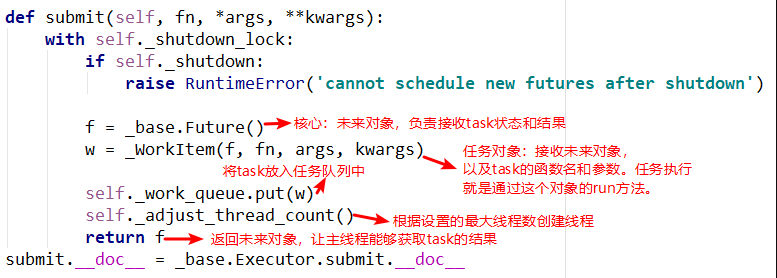
submit中有两个重要的对象,_base.Future()和_WorkItem()对象,_WorkItem()对象负责运行任务和对future对象进行设置,最后会将future对象返回,可以看到整个过程是立即返回的,没有阻塞。adjust_thread_count方法
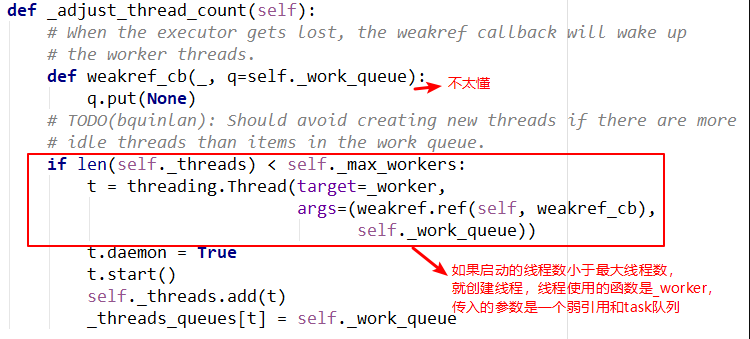
这个方法的含义很好理解,主要是创建指定的线程数。但是实现上有点难以理解,比如线程执行函数中的weakref.ref,涉及到了弱引用等概念,留待以后理解。
_WorkItem对象
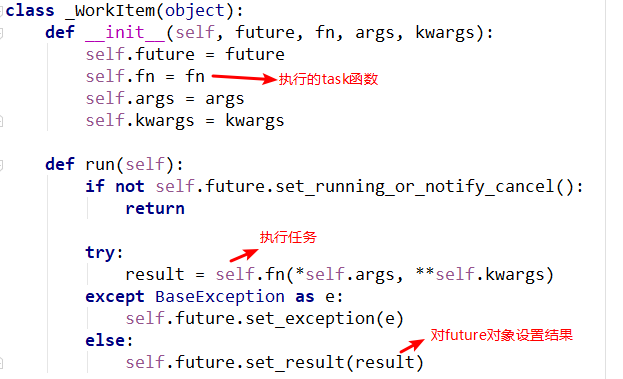
_WorkItem对象的职责就是执行任务和设置结果。这里面主要复杂的还是self.future.set_result(result)。线程执行函数--_worker
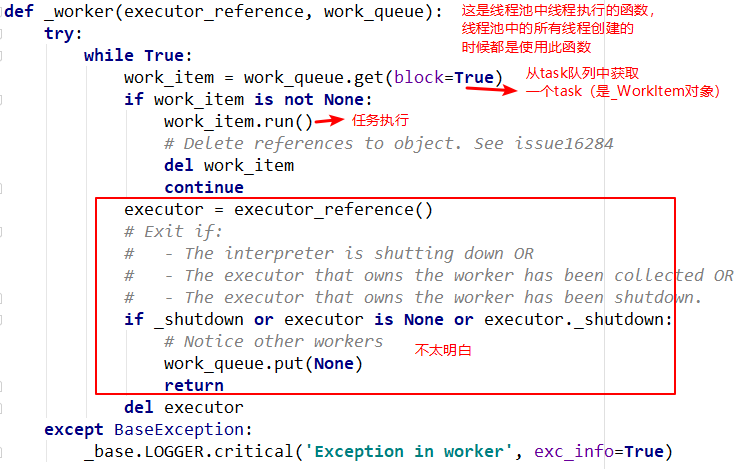
这是线程池创建线程时指定的函数入口,主要是从队列中依次取出task执行,但是函数的第一个参数还不是很明白。留待以后。
总结
- future的设计理念很棒,在线程池/进程池和携程中都存在future对象,是异步编程的核心。
- ThreadPoolExecutor 让线程的使用更加方便,减小了线程创建/销毁的资源损耗,无需考虑线程间的复杂同步,方便主线程与子线程的交互。
- 线程池的抽象程度很高,多线程和多进程的编码接口一致。
未完成
- 对future模块的理解。
- weakref.ref是什么?
- 线程执行函数入口_worker的第一个参数的意思。
参考
[python] ThreadPoolExecutor线程池的更多相关文章
- [python] ThreadPoolExecutor线程池 python 线程池
初识 Python中已经有了threading模块,为什么还需要线程池呢,线程池又是什么东西呢?在介绍线程同步的信号量机制的时候,举得例子是爬虫的例子,需要控制同时爬取的线程数,例子中创建了20个线程 ...
- Python ThreadPoolExecutor 线程池导致内存暴涨
背景 在有200W的任务需要取抓取的时候,目前采用的是线程池去抓取,最终导致内存暴涨. 原因 Threadpoolexcutor默认使用的是无界队列,如果消费任务的速度低于生产任务,那么会把生产任务无 ...
- 13.ThreadPoolExecutor线程池之submit方法
jdk1.7.0_79 在上一篇<ThreadPoolExecutor线程池原理及其execute方法>中提到了线程池ThreadPoolExecutor的原理以及它的execute方法 ...
- ThreadPoolExecutor 线程池的源码解析
1.背景介绍 上一篇从整体上介绍了Executor接口,从上一篇我们知道了Executor框架的最顶层实现是ThreadPoolExecutor类,Executors工厂类中提供的newSchedul ...
- j.u.c系列(01) ---初探ThreadPoolExecutor线程池
写在前面 之前探索tomcat7启动的过程中,使用了线程池(ThreadPoolExecutor)的技术 public void createExecutor() { internalExecutor ...
- Python的线程池实现
# -*- coding: utf-8 -*- #Python的线程池实现 import Queue import threading import sys import time import ur ...
- Java并发——ThreadPoolExecutor线程池解析及Executor创建线程常见四种方式
前言: 在刚学Java并发的时候基本上第一个demo都会写new Thread来创建线程.但是随着学的深入之后发现基本上都是使用线程池来直接获取线程.那么为什么会有这样的情况发生呢? new Thre ...
- ThreadPoolExecutor 线程池
TestThreadPoolExecutorMain package core.test.threadpool; import java.util.concurrent.ArrayBlockingQu ...
- 十、自定义ThreadPoolExecutor线程池
自定义ThreadPoolExecutor线程池 自定义线程池需要遵循的规则 [1]线程池大小的设置 1.计算密集型: 顾名思义就是应用需要非常多的CPU计算资源,在多核CPU时代,我们要让每一个CP ...
随机推荐
- 常用的HTTP测试工具谷歌浏览器插件汇总
网页的开发和测试时最常见的测试就是HTTP测试,作为曾经的测试人员在这方面还是略知一二的.其实做网页测试工作是非常繁琐的时期,有时候甚至是无聊重复的,如果没有网页测试工具的帮助的话,测试人员会越做越怀 ...
- jupyter notebook的插件安装及文本格式修改
jupyter notebook的插件安装及文本格式修改 1.jupyter notebook拓展插件安装 启动jupyter notebook : 打开控制台输入命令 jupyter noteboo ...
- codeforces 372 Complete the Word(双指针)
codeforces 372 Complete the Word(双指针) 题链 题意:给出一个字符串,其中'?'代表这个字符是可变的,要求一个连续的26位长的串,其中每个字母都只出现一次 #incl ...
- mdbtools使用
1.导入数据库到mysql(将key.mdb导入MySQL的test数据库,此时只导入表结构) mdb-schema key.mdb mysql | mysql -u root -p test 2.将 ...
- codevs4419 FFF 团卧底的菊花
题目描述 Description FFF 团卧底在这次出题后就知道他的菊花可能有巨大的危险,于是他提前摆布好了菊花阵,现在菊花阵里有若干朵菊花,出现次数最多的那一朵就是出题人的,你的任务是需要找出出题 ...
- ORA-00604: 递归 SQL 级别 1 出现错误 ORA-01653: 表 SYS.AUD$ 无法通过 8192 (在表空间 SYSTEM 中) 扩展
https://blog.csdn.net/zhangyong329/article/details/53421951
- 5-45 航空公司VIP客户查询 (25分) HASH
不少航空公司都会提供优惠的会员服务,当某顾客飞行里程累积达到一定数量后,可以使用里程积分直接兑换奖励机票或奖励升舱等服务.现给定某航空公司全体会员的飞行记录,要求实现根据身份证号码快速查询会员里程积分 ...
- java int怎么转换为string
1.两种方法,一个是再int后面+“”,就可以转为字符串. 另一个, nt i=12345;String s="";第一种方法:s=i+"";第二种方法:s=S ...
- 创建.m文件一片空白的错误解决方式
今天写代码,想继承一个类,突然发现创建的类文件一片空白,如图 之后各种调试发现都解决不了问题,以为是装了xcode6 beta2 版本号的问题,结果发现事实上是我创建错了 我创建的是 watermar ...
- Oracle移除表空间的数据文件 ora-00604 ora-01426
项目背景:在之前开发环境数据库管理比較乱,在表空间不足时仅仅是加入数据文件,測试完后数据己删除,但数据库表空间所占的空间不能回收,导致数据库的存储文件夹使用率达到97%以上实际使用仅仅有10%, ...