FastDFS的介绍
FastDFS的介绍
FastDFS
FastDFS是由国人余庆所开发,其项目地址:
https://github.com/happyfish100
FastDFS是一个轻量级的开源分布式文件系统,主要解决了大容量的文件存储和高并发访问的问题,文件存取时实现了负载均衡。
FastDFS是一款类Google FS的开源分布式文件系统,它用纯C语言实现,支持Linux、FreeBSD、AIX等UNIX系统。
FastDFS只能通过专有API对文件进行存取访问,不支持POSIX接口方式,不能mount使用。
准确地讲,Google FS以及FastDFS、mogileFS、 HDFS、TFS等类Google FS都不是系统级的分布式文件系统,而是应用级的分布式文件存储服务。
FastDFS的特性
1》分组存储,灵活简洁、对等结构,不存在单点
2》文件ID由FastDFS生成,作为文件访问凭证,FastDFS不需要传统的name server
3》和流行的web server无缝衔接,FastDFS已提供apache和nginx扩展模块
4》大、中、小文件均可以很好支持,支持海量小文件存储
5》 支持多块磁盘,支持单盘数据恢复
6》 支持相同文件内容只保存一份,节省存储空间
7》 存储服务器上可以保存文件附加属性
8》 下载文件支持多线程方式,支持断点续传
FastDFS架构图
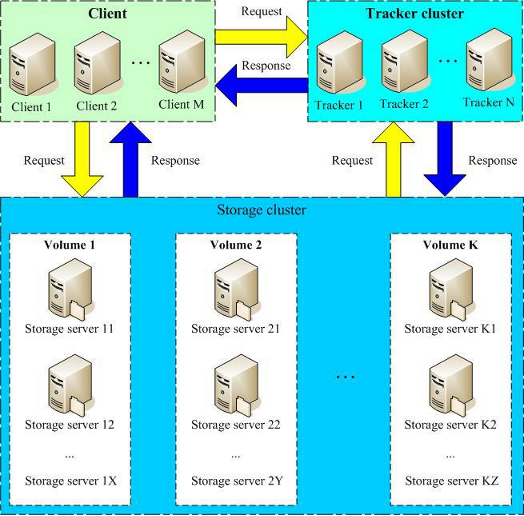
FastDFS架构解读
只有两个角色,tracker server和storage server,不需要存储文件索引信息
所有服务器都是对等的,不存在Master-Slave关系
存储服务器采用分组方式,同组内存储服务器上的文件完全相同(RAID 1)
不同组的storage server之间不会相互通信
由storage server主动向tracker server报告状态信息,tracker server之间通常不会相互通信
系统架构-上传文件流程图
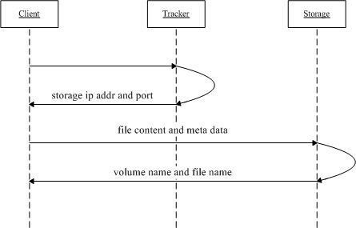
1》client询问tracker上传到的storage;
2》tracker返回一台可用的storage;
3》client直接和storage通信完成文件上传,storage返回文件ID。
系统架构-下载文件流程图
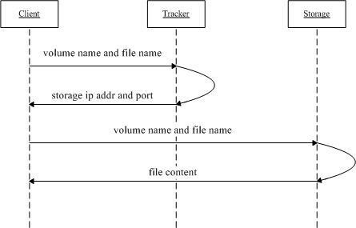
1》client询问tracker下载文件的storage,参数为文件ID(组名和文件名);
2》tracker返回一台可用的storage;
3》client直接和storage通信完成文件下载。
Fast同步机制
采用binlog文件记录更新操作,根据binlog进行文件同步
同一组内的storage server之间是对等的,文件上传、删除等操作可以在任意一台storage server上进行;
文件同步只在同组内的storage server之间进行,采用push方式,即源服务器同步给目标服务器;
源头数据才需要同步,备份数据不需要再次同步,否则就构成环路了;
上述第二条规则有个例外,就是新增加一台storage server时,由已有的一台storage server将已有的所有数据(包括源头数据和备份数据)同步给该新增服务器。
FastDFS用户请求过程
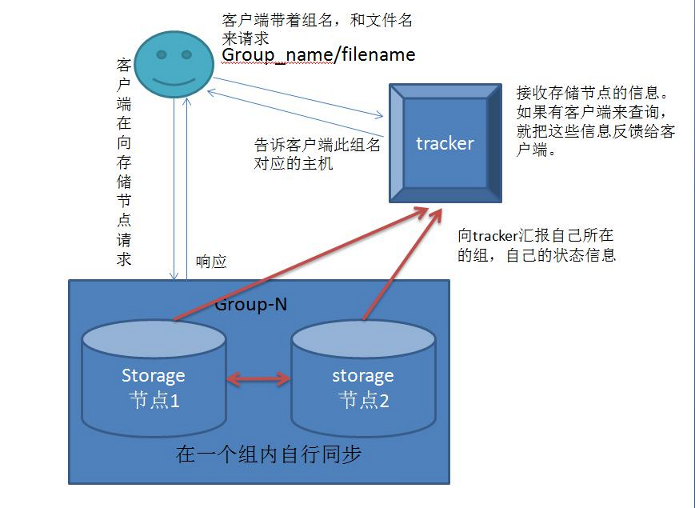
FastDFS核心组件
Tracker:
调度器,负责维持集群的信息,例如各group及其内部的storage node,这些信息也是storage node报告所生成,每个storagenode会周期性向tracker发心跳信息;
storage server:
以group为单位进行组织,任何一个storage server都应该属于某个group,一个group应该包含多个storage server,在同一个group内部,各storage server的数据互相冗余;
FastDFS运行机制
如何在组中挑选storage server:
1》rr;
2》以ip为次序,找第一个,即IP地址较小者;
3》以优先级为序,找第一个;
如何选择磁盘(存储路径):
1》rr;
2》剩余可用空间大者优先;
生成FID:
由源头storage server ip、创建时的时间戳、大小、文件的校验码和一个随机数进行hash计算后生成;
最后基于base64进行文本编码,转换为可打印字符;
groupID/MID/H1ID/H2ID/file_name
groupID:组编号
MID:存储路径(存储设备)编号
H1ID/H2ID:目录分层
file_name:文件名,不同于用户上传时使用文件名,而是由服务器生成hash文件名;
服务器IP、文件创建时的时间戳、文件大小、文件名和扩展名;
文件同步:
每个storage server在文件存储完成后,会将其信息存于binlog, binlog不包含数据,仅包含文件名等元数据信息,binlog可用于同步;
FastDFS配置修改
Tracker:
编辑tracker server配置文件tracker.conf,需要修改内容如下:
disabled=false(默认为false,表示是否无效)
port=22122(默认为22122)
base_path=/data/fastdfs/tracker
storage server:
disabled=false(默认为false,表示是否无效)
port=23000(默认为23000)
base_path=/data/fastdfs/storage
tracker_server=172.18.10.232:22122
store_path0=/data/fastdfs/storage
http.server_port=8888(默认为8888,nginx中配置的监听端口那之一致)
FastDFS常用命令
1》查看存储节点状态
# fdfs_monitor /etc/fdfs/client.conf
2》上传测试
fdfs_test <config_file> upload <local_filename> [FILE | BUFF | CALLBACK]
3》文件上传
fdfs_upload_file /etc/fdfs/client.conf /root/solo-2.2.0.war
4》文件查看
fdfs_file_info /etc/fdfs/client.conf group1/M00/00/00/rBH7vFoax3KANb_FAUlr7-L-yRM9.0.war
5》文件下载
fdfs_download_file /etc/fdfs/client.conf group1/M00/00/00/rBH7vFoax3KANb_FAUlr7-L-yRM9.0.war
FastDFS实现nginx代理
1》安装nginx以及对应模块
2》修改nginx的location配置,映射路径和启动模块
location /group1/M00 {
root /data/fdfs/store/data;
ngx_fastdfs_module;
}
3》修改对应fastdfs模块
url_have_group_name = true
tracker_server=172.17.252.234:22122
FastDFS的介绍的更多相关文章
- 分布式文件系统FastDFS原理介绍
在生产中我们一般希望文件系统能帮我们解决以下问题,如:1.超大数据存储:2.数据高可用(冗余备份):3.读/写高性能:4.海量数据计算.最好还得支持多平台多语言,支持高并发. 由于单台服务器无法满足以 ...
- FastDFS api介绍
1. 命令行api介绍 FastDFS提供了可用于运维测试的命令行api,下面进行介绍: 1.1 fastdfs服务管理 tracker进程服务管理脚本 /etc/init.d/fdfs_tracke ...
- 【转】分布式文件系统FastDFS原理介绍
什么是FastDFS? FastDFS是一个开源的轻量级分布式文件系统.它解决了大数据量存储和负载均衡等问题.特别适合以中小文件(建议范围:4KB < file_size <500MB)为 ...
- FastDFS 原理介绍
1 功能简介 FastDFS是一个开源的轻量级分布式文件系统,它对文件进行管理,功能包括:文件存储.文件同步.文件访问(文件上传.文件下载)等,解决了大容量存储和负载均衡的问题.特别适 ...
- FastDFS介绍和配置过程 二
最近在研究负载均衡和集群,其中涉及到一个主要问题是,如何让集群中的real server共享一套文件系统.在网上查到FastDFS,国人(happy fish,感谢他的开源精神)开发的一套轻量级分 ...
- FastDFS搭建及java整合代码【转】
FastDFS软件介绍 1.什么是FastDFS FastDFS是用C语言编写的一款开源的分布式文件系统.FastDFS为互联网量身定制,充分考虑了冗余备份.负载均衡.线性扩容等机制,并注重高可用.高 ...
- FastDfs 说明、安装、配置
fastdfs是一个开源的,高性能的的分布式文件系统,他主要的功能包括:文件存储,同步和访问,设计基于高可用和负载均衡,fastfd非常适用于基于文件服务的站点,例如图片分享和视频分享网站 fastf ...
- Linux下FastDFS分布式存储-总结及部署记录
一.分布式文件系统介绍分布式文件系统:Distributed file system, DFS,又叫做网络文件系统:Network File System.一种允许文件通过网络在多台主机上分享的文件系 ...
- 轻量级分布式文件系统FastDFS使用安装说明手册(新手入门级)
轻量级分布式文件系统FastDFS使用安装说明手册(新手入门级) 实验室所在的课题组以研究云计算为主,但所有的研究都是在基于理论的凭空想像,缺少分布式环境的平台的实践,云计算神马的都是浮云了.因此,我 ...
随机推荐
- 集训第六周 古典概型 期望 C题
http://acm.hust.edu.cn/vjudge/problem/viewProblem.action?id=30728 一个立体方块,每个单位方块都是关闭状态,每次任两个点,以这两点为对角 ...
- [bzoj1208][HNOI2004][宠物收养所] (平衡树)
Description 最近,阿Q开了一间宠物收养所.收养所提供两种服务:收养被主人遗弃的宠物和让新的主人领养这些宠物.每个领养者都希望领养到自己满意的宠物,阿Q根据领养者的要求通过他自己发明的一个特 ...
- 04002_HTML表单
1.表单标签 (1)表单标签:所有需要提交到服务器的表单项必须使用<form></form>括起来: (2)from标签属性 ①action:整个表单提交的位置,可以是一个页面 ...
- vs2003 刷新项目失败。无法从服务器中检索文件夹信息
环境: 操作系统:windows server 2003 开发工具:Visual stuadio 2003 FrameWork: 1.1 打开web项目的时候报错 提示 项目刷新失败,无法从服务器 ...
- JQuery_九大选择器
JQuery_九大选择器-----https://blog.csdn.net/pseudonym_/article/details/76093261
- js在HTML中的三种写法
1.内联样式 内联样式分为两种,一是直接写入元素的标签内部 <html> <title>js样式内联写法</title> <meta http-equiv=& ...
- POJ3352-Road Construction(边连通分量)
It's almost summer time, and that means that it's almost summer construction time! This year, the go ...
- 营救(洛谷 P1396)
题目描述 “咚咚咚……”“查水表!”原来是查水表来了,现在哪里找这么热心上门的查表员啊!小明感动的热泪盈眶,开起了门…… 妈妈下班回家,街坊邻居说小明被一群陌生人强行押上了警车!妈妈丰富的经验告诉她小 ...
- 2018/3/3 解析ThreadLocal源码
今天听到一个老哥说道ThreadLocal在源码设计上面的一些好处,于是决定把ThreadLocal源码彻底分析一下. 首先,我们来看下set方法 可以看到,这个方法里,先获得了当前线程,之后将当前线 ...
- codeforces Gym 100814 A、B、F、I
A题 先求出来这个数是第几大 阶乘求概率p 然后计算获得胜率的概率 常规解法把所有情况考虑一遍(跳1次,2次,3次……)要用到组合数 数可能太大了会爆的行不通 我们观察发现它有递推性质,从第二大 ...