serialVersionUID序列化版本号与ObjectOutputStream对象输入输出流
1. 观察ObjectOutputStream
我们观察ObjectOutputStream就可以发现该类没有无参构造,只有有参构造,所以他是一个包装流
2. 具体使用:
public static void main(String[] args) throws IOException {
Student stu = new Student(13,"xj",15,"男");
String path = "src/main/java/com/xj/dayio/demo2.txt";
FileOutputStream fos = new FileOutputStream(path);
ObjectOutputStream oos = new ObjectOutputStream(fos);
oos.writeObject(stu);
}
3. 实现Serializable接口
我们在使用ObjectOutputStream的时候,需要为被序列化的对象实现Serializable接口(implements Serializable),意思是此类是“可序列化的”。
否则会抛出异常:Exception in thread "main" java.io.NotSerializableException: com.xj.dayio.Student
public class Student implements Serializable {
private int id;
private String name;
private int age;
private String sex;
构造器。。。
get,set方法
toString方法
}
此时调用ObjectOutputStream对象输出流就可以成功将对象写出到文件
�� sr com.xj.dayio.Student�(U�\jb� I ageI idL namet Ljava/lang/String;L sexq ~ xp
t
xjt 男
4. 使用ObjectInputStream读取
我们在读取的时候也可以使用ObjectInputStream对象输入流来进行读取
public static void main(String[] args) throws IOException {
String path = "src/main/java/com/xj/dayio/demo2.txt";
FileInputStream fis = new FileInputStream(path);
ObjectInputStream ois = new ObjectInputStream(fis);
Object object = ois.readObject();
System.out.println((Student) object);
}
输出:
Student{id=13, name='xj', age=15, sex='男'}
5. 序列化接口的作用
那么我们的序列化接口是主要做什么呢?为什么必须要实现接口才能使用对象输出流
- 序列化指的是把一个对象中所包含的数据按照一定的顺序转化成二进制数据。
- 但是,我们自己定义的类型,JVM没有权力直接对其对象进行序列化。因为一个类型一旦允许被序列化,则意味着该类型对象中保存的数据存在泄露的风险。
- 程序员虽然不需要关心对象的具体序列化过程,但是必须要向JVM授权,告诉它哪个类型是允许被序列化的。
- 向JVM授意的方式:让需要被传输的类型实现一个接口Serializable,该接口代表“可序列化的”。
- Serializable是一个空接口,什么内容都没有。它只是为了起到一个“标识”作用。
注意:需要被IO流传输的对象中所有包含的类型都需要是“可序列化”的。所有的引用类型属性所属类型都必须实现Serializable。(那为什么String对象我们可以直接序列化呢?我们查看String的源码就可以发现String类已经实现过序列化接口)
6. 在反序列化的时候,需要提供对应的.class文件。
- 例如本案例中,写入到文件中的是一个com.xj.dayio.Student类对象
- 该对象所有包含的信息都会被写入到文件中,也包含它的类型信息。
- 在反序列化时,JVM会尝试加载这个类型。
- 如果对应的.class不存在,则类加载失败,反序列化对应也会失败。
- 因为内存中想要出现一个对象,它所属的类型不可能不存在。
7. 需要提供的.class字节码文件未必一定是当时存储时!
我们可以将Student对象输出到文件中后,然后删除掉Student类,然后重写一个Student类,但是这个类必须要与原Student类一样
包括包名、类名、实现的接口、继承的父类、属性、属性的修饰符、属性的名称、属性的类型、属性的默认值、方法、方法的修饰符、方法的返回值、方法的参数、方法的抛出异常……
8. 实际上,我们看到的只是一个表象。
决定是否允许进行反序列化,实际上并不是单纯地、直接地根据类中包含的信息进行判断。
实际上,是由一个叫做serialVersionUID(序列化版本号)字段控制反序列化是否允许执行。
向文件中写入一个对象的时候,也包含一个UID。将来进行反序列化的时候,也会将这个UID读取出来,并且和当前尝试加载的类的该UID字段值进行比较。
- 如果这两个UID是相同的,则允许执行反序列化,生成对象成功。
- 如果这两个UID是不相同的,则不允许执行反序列化,生成对象失败。会抛出异常:java.io.InvalidClassException - 不合法的类型异常
9. serialVersionUID来自哪里
那么serialVersionUID来自哪里呢,我们在程序中并没有写呀。
- 如果我们在类中没有定义该字段,那么JVM会自动计算出一个值来充当该类的该字段值
- 该字段值的计算过程类似哈希过程。意味着只要参与运算的数值相同,那么结果也一定相同。
- 也就是说,只要两个类保证一模一样,计算出来的serialVersionUID肯定是相同的。
10. 自己定义serialVersionUID
但是同样我们也可以自己定义serialVersionUID
只需要在代码中加上这一句即可
public class Student implements Serializable {
private static final long serialVersionUID = -4167987148983999791L;
private int id;
private String name;
private int age;
private String sex;
我们还可以有idea直接生成,但是idea默认是不会提醒的
我们需要修改设置,将其后面的对勾勾上
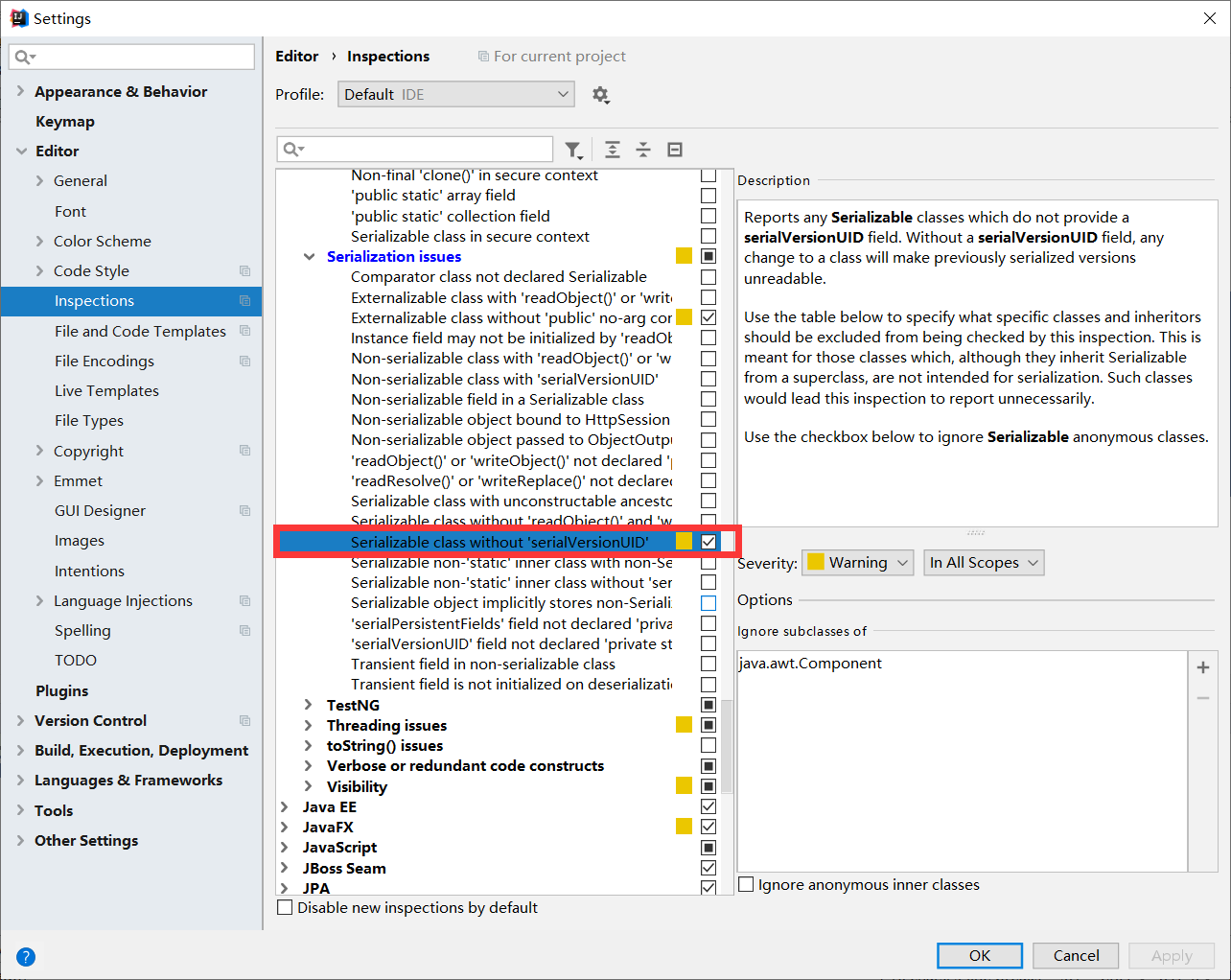
这时如果我们没有写serialVersionUID,ide就会爆出警告
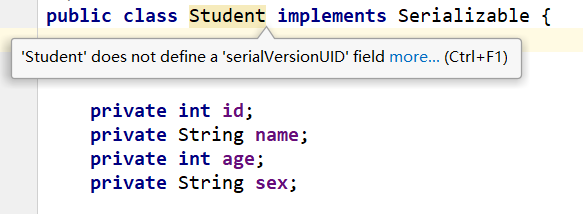
根据提示ide就会自动为我们生成默认的serialVersionUID
11. 定义serialVersionUID为1
我们刚才说了,反序列化是主要根据serialVersionUID 来的,与属性,方法等无关,只是默认serialVersionUID 是由属性,方法生成,但是我们在手动定义serialVersionUID 后,JVM就不会使用默认的,而是使用我们自己的。我们可以定义一个serialVersionUID 为1,那么此时我无论是删除属性,修改方法等,都不会影响反序列化,只是我们如果属性对应不上就无法赋值
例如:若我将name重改为name1
输出:此时name属性就没有被赋值,这也是为什么序列化后数据会有泄露的风险
Student{id=13, name='null', age=15, sex='男'}
比如保存用户名和密码的文件被泄露,此时我只需要写一个类,实现Serializable 后,里面定义很多个变量,如password,passWord,pwd,PassWord等等,此时使用我自己定义的类去使用对象流去读取保存密码的文件时,就有可能将密码提取出来,所以我们应该尽可能的去让序列化版本号serialVersionUID去随机,这样子,序列化版本号不正确,文件也无法被反序列化。
serialVersionUID序列化版本号与ObjectOutputStream对象输入输出流的更多相关文章
- (JAVA)从零开始之--对象输入输出流ObjectInputStream、ObjectOutputStream(对象序列化与反序列化)
对象的输入输出流 : 主要的作用是用于写入对象信息与读取对象信息. 对象信息一旦写到文件上那么对象的信息就可以做到持久化了 对象的输出流: ObjectOutputStream 对象的输入流: Ob ...
- 对象输入输出流ObjectInputStream、ObjectOutputStream(对象序列化与反序列化)
对象的输入输出流 : 主要的作用是用于写入对象信息与读取对象信息. 对象信息一旦写到文件上那么对象的信息就可以做到持久化了 对象的输出流: ObjectOutputStream 对象的输入流: Ob ...
- Day 18:SequenceInputStream、合并切割mp3、对象输入输出流对象
SequenceInputStream用例题讲述用法 需求:1.把a.txt与b.txt 文件的内容合并 2.把a.txt与b.txt .c.txt文件的内容合并 import java.io.Fil ...
- java 对象输入输出流
对象的输入输出流的作用: 用于写入对象 的信息读取对象的信息. 对象的持久化. 比如:用户信息. ObjectInputStream : 对象输入流 ...
- 对象输入输出流ObjectInputStream、ObjectOutputStream(对象的序列化与反序列化)
如题 所有关联的类需要继承Serializable 接口 文件为空,直接反序列化为发生错误; 毕竟对象为null , 序列化到文件里不是空空的! 以下笔记的原文连接: https://www.cnbl ...
- 输入输出流ObjectInputStream、ObjectOutputStream(对象序列化与反序列化)
对象的输入输出流 : 主要的作用是用于写入对象信息与读取对象信息. 对象信息一旦写到文件上那么对象的信息就可以做到持久化了 对象的输出流: ObjectOutputStream 对象的输入流: Ob ...
- Java知多少(69)面向字节的输入输出流
字节流以字节为传输单位,用来读写8位的数据,除了能够处理纯文本文件之外,还能用来处理二进制文件的数据.InputStream类和OutputStream类是所有字节流的父类. InputStream类 ...
- 八. 输入输出(IO)操作4.面向字节的输入输出流
字节流以字节为传输单位,用来读写8位的数据,除了能够处理纯文本文件之外,还能用来处理二进制文件的数据.InputStream类和OutputStream类是所有字节流的父类. InputStream类 ...
- java学习笔记-输入输出流
================File类 =====================InputStream ==================OutputStream ============== ...
随机推荐
- COM笔记-COM库函数
COM在OLE32.DLL和 OLE32.LIB定义了一些常用的函数.在使用这些函数前要先调用CoInitialize来初始化COM库.当进程不再需要使用COM库函数时要调用CoUninitializ ...
- offsetof宏---个人笔记
标准库里面提供的offsetof(t,m)宏,用来计算两个变量在内存中的地址偏移量 #include <stdio.h>//原型: #define offsetof(TYPE, MEMBE ...
- Failed to start LSB: Bring up/down错误解决方法
很多朋友在使用centos7系统时,有时候需要分配多个IP地址,这就涉及到修改网卡配置,但是在修改完网卡配置时,重启网络服务时会出现"Failed to start LSB: Bring u ...
- 何时覆盖hashCode()和equals()方法
The theory (for the language lawyers and the mathematically inclined): equals() (javadoc) must defin ...
- xv6学习笔记(5) : 锁与管道与多cpu
xv6学习笔记(5) : 锁与管道与多cpu 1. xv6锁结构 1. xv6操作系统要求在内核临界区操作时中断必须关闭. 如果此时中断开启,那么可能会出现以下死锁情况: 进程A在内核态运行并拿下了p ...
- IDEA快捷键命令
Ctrl+Alt+T IDEl 抛异常快捷键ctrl +o 继承类时 继承方法快捷键Ctrl+Alt+左右方向键 回到上次光标停留的地方ALt +left/right 快速切换两个页面ctr ...
- mybatis插值,数据提交事务回滚数据库值为空
mybatis插值,数据提交事务回滚数据库值为空 通过sql日志查看sql为:INSERT INTO `quanxian`.`user` ( phone, email, password, times ...
- 痞子衡嵌入式:MCUXpresso Config Tools初体验(Pins, Clocks, Peripherals)
大家好,我是痞子衡,是正经搞技术的痞子.今天痞子衡给大家介绍的是MCUXpresso Config Tools三大件(Pins, Clocks, Peripherals). 不知道大家有没有这样的感受 ...
- RabbitMQ之消息模式2
消费端限流 什么是消费端的限流? 假设一个场景,首先,我们RabbitMQ服务器有上万条未处理的消息,我们随便打开一个消费者客户端,会出现下面情况: 巨量的消息瞬间全部推送过来,但是我们单个客户端无法 ...
- K8S资源编排(yaml)
1.yaml的格式 2.yaml的组成部分 3.yaml常用字段的含义 4.yaml编写方式 (1)方式一:使用kubectl create命令生成yaml文件,然后修改 (2)方式2:在已经部署好的 ...