python中常用的导包的方法和常用的库
python中常用的导包的方法
导入包和包名的方法:1、import package.module
2、from package.module import *
例一:
#second.py def register():
print('this is a register page')
#first.py页面调用registe()方法时 #1、
import zero.second zero.second.register() #2、
from zero.second import * register()
输出结果:
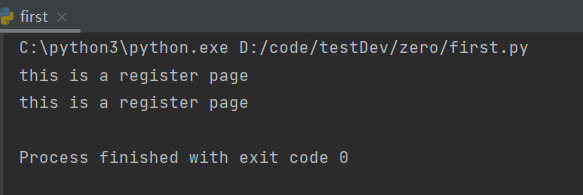
例二:
#func.py def logout():
print('this is a logout function') class Logout(object):
def profile(self): #实例化
print('this is a profile method')
#second.py def register():
print('this is a register page')
常用的导包方式:1、from package.modlue import *
2、from package.package.modlue import *
from zero.first import login
from zero.second import register
from zero.one.func import logout,Logout
#导入包后,可直接调用下面的方法,来获取这些方法里面的内容
login()
register()
logout()
obj=Logout()
obj.profile()
输出结果:
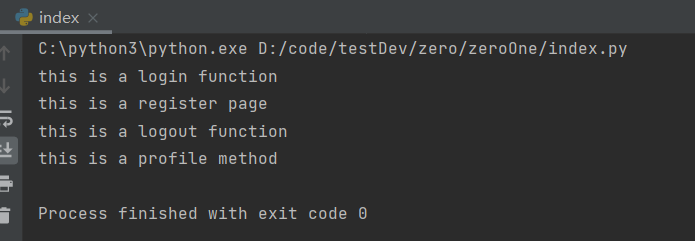
sys库实战
PS:有时候导入包以后,还是会提示报错,提示找不到路径,用一下的方法解决:
import sys
import os '''提示first的模块不存在,找不到错误的解决方案'''
base_dir=os.path.dirname(os.path.dirname(__file__)) #先定义base_dir,输出D:\code\testDev\zero路径 sys.path.append(os.path.join(base_dir,'zero')) for item in sys.path:
print(item) from first import login
login()
输出结果:
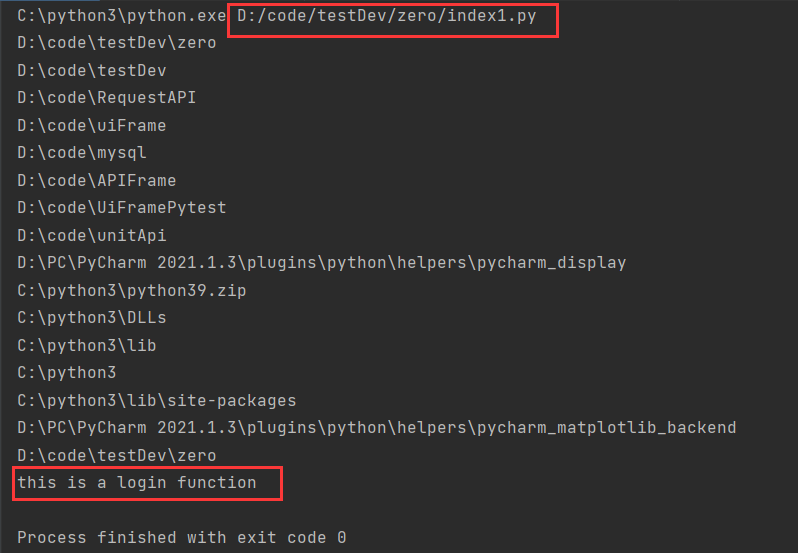
常用的库:
1、json库的应用
在python中,序列化:把python的数据类型(字典、元组、列表)转为str的数据类型;
反序列化:把str的数据类型转为python对象的过程。
序列化和反序列化在列表、元组和字典中的应用:
列表:
import json lists=[1,2,3,4] #序列化
list_str=json.dumps(lists) ##先对lists进行序列化list_str
print('内容:',list_str,'序列化后的列表类型:',type(list_str))
#反序列化
str_list=json.loads(list_str) ##再对list_str进行反序列化str_list
print('内容:',str_list,'反序列化后的列表类型:',type(str_list))
输出结果(输出的内容可能看不出来效果,通过type()查看数据类型就可以看出区别):
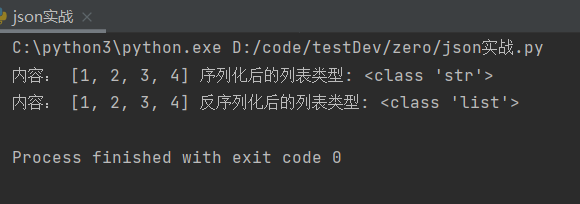
元组:
import json
tuple1=(1,2,3,4) #序列化
tuple_str=json.dumps(tuple1) #格式化的时候
print('内容:',tuple_str,'序列化后的列表类型:',type(tuple_str))
# #反序列化
str_tuple=json.loads(tuple_str)
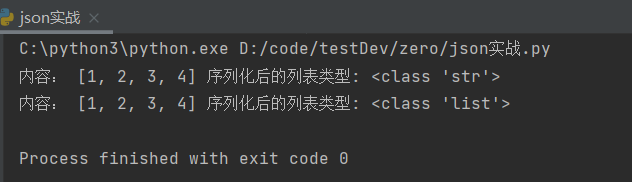
print('内容:',str_tuple,'序列化后的列表类型:',type(str_tuple))
输出结果(输出的内容可能看不出来效果,通过type()查看数据类型就可以看出区别):
字典:
import json
dict1={'name':'lyl','age':18}
# #序列化
dict_str=json.dumps(dict1)
print('内容:',dict_str,'序列化后的列表类型:',type(dict_str))
# #反序列化
str_dict=json.loads(dict_str)
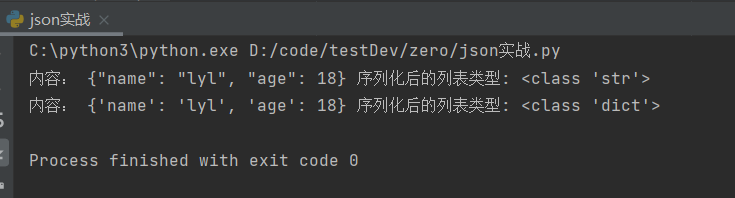
print('内容:',str_dict,'序列化后的列表类型:',type(str_dict))
输出结果(双引号和单引号并不能说明数据类型的转变,通过type()查看数据类型):
dump():把目标数据写到文件里面
load():从文件里面读取数据
import json
dict1={'name':'lyl','age':18,'address':'xian'}
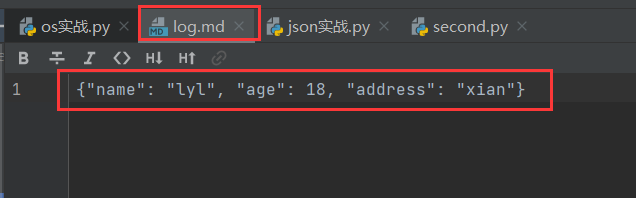
#把dict1的内容用w模式写到log.md里面,
json.dump(dict1,open('log.md','w'))
#读取log.md里面的内容
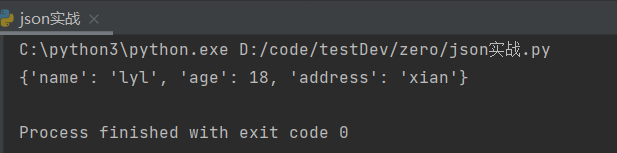
print(json.load(open('log.md','r')))
输出结果:
2、os库实战:
os是针对:1、命令行处理
2、路径处理
1)、命令行处理:
import json
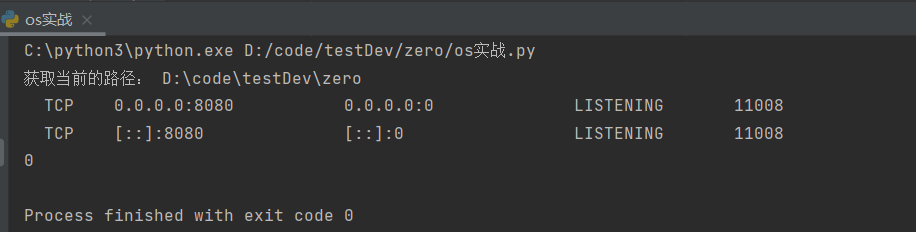
print('获取当前的路径:',os.getcwd())
#查看tomcat端口是不是被占用,当然首先要启动端口,不启动端口不用端口就不存在占用的问题。
print(os.system('netstat -ano | findstr "8080"')) #netstat -ano | findstr "8080"这个命令可以直接再cmd中打开
输出结果:
2)、路径处理
(1)获取路径
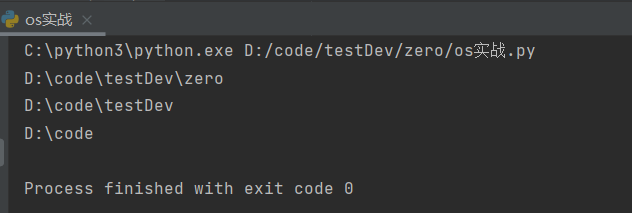
import os '''获取路径 os.path.dirname()'''
#获取D:\code\testDev\zero路径
print(os.path.dirname(__file__))
#获取D:\code\testDev路径
print(os.path.dirname(os.path.dirname(__file__)))
#获取D:\code路径
print(os.path.dirname(os.path.dirname(os.path.dirname(__file__))))
输出结果:
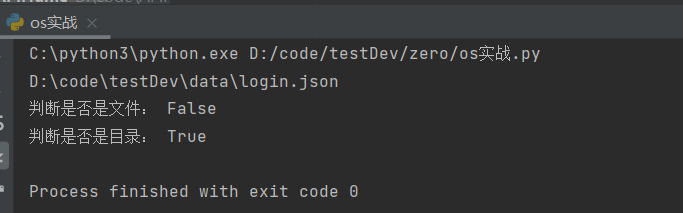
(2)路径的拼接(login.json在别的文件夹下面):
import os '''路径拼接 os.path.join()'''
base_dir=os.path.dirname(os.path.dirname(__file__))
print(os.path.join(base_dir,'data','login.json'))
print('判断是否是文件:',os.path.isfile('D:/code/mysql/utils/')) #os.path.isfile()针对文件路径
print('判断是否是目录:',os.path.exists('D:/code/mysql/utils/yamlUtils.py')) #os.path.exists()针对具体的文件
输出的结果:
3、hashlib库实战
hashlib是设计安全散列和消息摘要,提供多个不同的加密算的接口,如:SHA1、SHA224、SHA256、SHA384、SHA512、MD5等。
针对---字符串的基本用法:
import hashlib
m=hashlib.md5()
m.update('heiheihei'.encode('utf-8'))
print(m.hexdigest())#返回十六进制数字字符串
输出结果:

针对---字典加密的用法:
from urllib import parse
import hashlib
import time def sign():
dict1={'name':'lyl','age':18,'sex':'girl','address':'xian','time':time.time()} #'time':time.time()不加时间每次的加密那个数字都一样,加了时间就每次加密不一样。
data=sorted(dict1.items(),key=lambda item:item[0])
data1=parse.urlencode(data)
#加密
m=hashlib.md5() #创建hash对象,md5(message-Digest Algorithm 5):消息摘要算法,得出一个128位的密文
m.update(data1.encode('utf-8')) #更新data1对象以字符串参数的形式
print(m.hexdigest()) #返回十六进制数字字符串 sign()
输出结果:

python中常用的导包的方法和常用的库的更多相关文章
- Python中异步协程的使用方法介绍
1. 前言 在执行一些 IO 密集型任务的时候,程序常常会因为等待 IO 而阻塞.比如在网络爬虫中,如果我们使用 requests 库来进行请求的话,如果网站响应速度过慢,程序一直在等待网站响应,最后 ...
- 举例详解Python中的split()函数的使用方法
这篇文章主要介绍了举例详解Python中的split()函数的使用方法,split()函数的使用是Python学习当中的基础知识,通常用于将字符串切片并转换为列表,需要的朋友可以参考下 函数:sp ...
- python中执行shell的两种方法总结
这篇文章主要介绍了python中执行shell的两种方法,有两种方法可以在Python中执行SHELL程序,方法一是使用Python的commands包,方法二则是使用subprocess包,这两个包 ...
- Python 中的时间处理包datetime和arrow
Python 中的时间处理包datetime和arrow 在获取贝壳分的时候用到了时间处理函数,想要获取上个月时间包括年.月.日等 # 方法一: today = datetime.date.today ...
- 【转】Android中引入第三方Jar包的方法(java.lang.NoClassDefFoundError解决办法)
原文网址:http://www.blogjava.net/anchor110/articles/355699.html 1.在工程下新建lib文件夹,将需要的第三方包拷贝进来.2.将引用的第三方包,添 ...
- Python中os和shutil模块实用方法集…
Python中os和shutil模块实用方法集锦 类型:转载 时间:2014-05-13 这篇文章主要介绍了Python中os和shutil模块实用方法集锦,需要的朋友可以参考下 复制代码代码如下: ...
- Python中os和shutil模块实用方法集锦
Python中os和shutil模块实用方法集锦 类型:转载 时间:2014-05-13 这篇文章主要介绍了Python中os和shutil模块实用方法集锦,需要的朋友可以参考下 复制代码代码如下: ...
- Python中的str与unicode处理方法
Python中的str与unicode处理方法 2015/03/25 · 基础知识 · 3 评论· Python 分享到:42 原文出处: liuaiqi627 的博客 python2.x中处理 ...
- Python中常见字符串去除空格的方法总结
Python中常见字符串去除空格的方法总结 1:strip()方法,去除字符串开头或者结尾的空格>>> a = " a b c ">>> a.s ...
随机推荐
- Java基础之SPI机制
SPI 机制,全称为 Service Provider Interface,是一种服务发现机制.它通过在 ClassPath 路径下的 META-INF/services 文件夹查找文件,自动加载文件 ...
- Mybatis(四)——
test https://www.cnblogs.com/chiaki/p/14529418.html
- NOIP模拟测试17&18
NOIP模拟测试17&18 17-T1 给定一个序列,选取其中一个闭区间,使得其中每个元素可以在重新排列后成为一个等比数列的子序列,问区间最长是? 特判比值为1的情况,预处理比值2~1000的 ...
- vue+element+echarts饼状图+可折叠列表
html: <div id="echartsDiv" style="width: 48%; height: 430px; float: left;"> ...
- Linux中不用用户可以使用相同的uid
usermod -u 513 -o tom 使得用户tom可以使用uid等于513,即使513已经被其他用户使用了
- PHP的那些魔术方法(二)
上文中介绍了非常常用并且也是面试时的热门魔术方法,而这篇文章中的所介绍的或许并不是那么常用,但绝对是加分项.当你能准确地说出这些方法及作用的时候,相信对方更能对你刮目相看. __sleep()与__w ...
- php_excel导出
1.下载PHPExcel工具 2.解压后放置位置:ThinkPHP\Extend\Vendor\PHPExcel\PHPExcel.php. 3.Common.php代码 public functio ...
- web、app、小程序测试异同点
http://www.spasvo.com/Company/news_show.asp?id=702 https://blog.csdn.net/weixin_43489515/article/det ...
- PHP - 设计模式 - 观察者模式
<?php//观察者模式//抽象通知者abstract class Subject { protected $observer = array() ; //添加观察者 public abstra ...
- pyqt5读取文本框内容,输出到日志框(QTextBrowser)
import sys from PyQt5.QtWidgets import QApplication, QMainWindow, QAction,QLabel,QLineEdit,QPushButt ...