一文带你理解TDengine中的缓存技术
作者 | 王明明,涛思数据软件工程师

小 T 导读:在计算机系统中,缓存是一种常用的技术,既有硬件缓存,比如我们经常听到的 CPU L2 高速缓存,也有软件缓存,比如很多系统里把 Redis 当做数据库的缓存。本文为根据 TDengine 线上 Meetup 第四期王明明的分享《TDengine 缓存技术解析》(视频)整理而成。
TDengine 是一款高性能的物联网大数据平台。为了高效处理时序数据,TDengine 中大量用到了缓存技术,自己实现了哈希表、缓存池等技术。今天我会为大家讲解 TDengine 中用到的这些缓存技术。
首先我会介绍一下什么是缓存,常用的缓存技术,最后重点分享 TDengine 中的相关技术,最好讲一下改进和优化的方向。下面我们正式开始。
什么是缓存?
凡是位于速度相差较大的两种硬件之间,用于协调两者数据传输速度差异的结构,均可称之为缓存。
缓存最早是用来协调 CPU 和主内存之间的速度差异,进化出了目前的 L1/L2/L3 三层 CPU 内部的高速缓存;
在内存和硬盘之间也有 Cache,每次写磁盘时并没有立即刷到磁盘上,而是写入到磁盘缓存中,由操作系统负责 flush 到磁盘;
此外,硬盘与网络之间也有某种意义上的 Cache,比如 CDN 缓存,代理服务器的缓存等等。
缓存工作的原则主要是引用的局部性,包括空间局部性和时间局部性。
空间局部性是指 CPU 在某一时刻需要某个数据,那么很可能下一步就需要其附近的数据,例如加载读磁盘数据的时候,虽然只需要一部分数据,但是每次都加载一个块,那么当需要附近数据的时候就可以直接从内存获取,避免再读取磁盘。
时间局部性是指当某个数据被访问过一次之后,过不了多久时间就会被再一次访问。例如我们手机后台运行程序,会把最近打开的应用缓存在后台,很可能一会儿还会访问相同的应用,这种情况下直接将其从后台调到前台即可。
在使用缓存时要根据系统的架构、性能的要求以及要解决的问题选择合适的缓存位置,比如内存缓存、 磁盘缓存、分布式缓存等。
使用缓存有很多优点:
提高性能,将相应数据存储起来以避免数据的重复创建、处理和传输,可有效提高性能。
提高稳定性,同一个应用中,对同一数据、逻辑功能的多次请求是经常发生的。当请求量很大时,如果每次请求都进行处理,消耗的资源是很大的浪费,也同时造成系统的不稳定。
提高可用性,有时,提供数据信息的服务可能会意外停止,如果使用了缓存技术,可以在一定时间内仍正常提供对最终用户的支持,提高了系统的可用性。
缓存是有状态的,包括时间状态和空间状态。
时间状态:应用程序使用的永久数据; 只在进程周期内有效;和特定的用户会话有关; 处理某个消息的时间内有效。
空间状态:应用程序/进程/线程/单机/分布式/用户/角色。
使用缓存时需要考虑的问题:
安全性:线程安全/权限安全
序列化
缓存数据优化
提前加载/动态加载
过期策略:FIFO/LRU/LFU
管理:效率监控,大小限制
缓存一致性问题:
当使用分布式的缓存时,需要考虑多个缓存的一致性问题,防止由于不一致出现问题。
处理一致性问题时需要根据实际的应用场景兼顾 CAP 原则。根据问题的场景不同,一致性要求也不同,可以强一致性或者弱一致性(最终一致性)。
a. 比如银行转账场景需要强一致性,数据没统一之前,不允许用户进行操作,防止金额出错。
b. 大多数互联网产品为了保证可用性和分区容错性,通常采用弱一致性,比如不同地区的用户看到的同一个排行榜可能有非常短暂的不同,但数据同步成功后,排行榜就相同了,这个延迟通常在几十 ms,对于用户来说是可以接受的。
常用的缓存技术
使用硬件缓存 (CPU Cache)
使用本地内存缓存(双缓冲/环形缓冲/缓冲池)
使用内存映射文件 (mmap)
使用数据库缓存 (Redis/MySQL)
TDengine 中的缓存方案
首先我们来复习一下 TDengine 的整体架构。
数据节点(dnode):服务进程,可以包括多个 vnode 和 mnode,查询数据时需要 dnode 的网络位置来获取数据。
虚拟节点(vnode):存储、查询的基本单位。多个 vnode 组成一个虚拟节点组(VGroup),分布在不同的机器上,起到备份的效果。同时 vnode 也便于水平扩展。
管理节点(mnode):存储数据库的元数据,起到管理集群的功能。
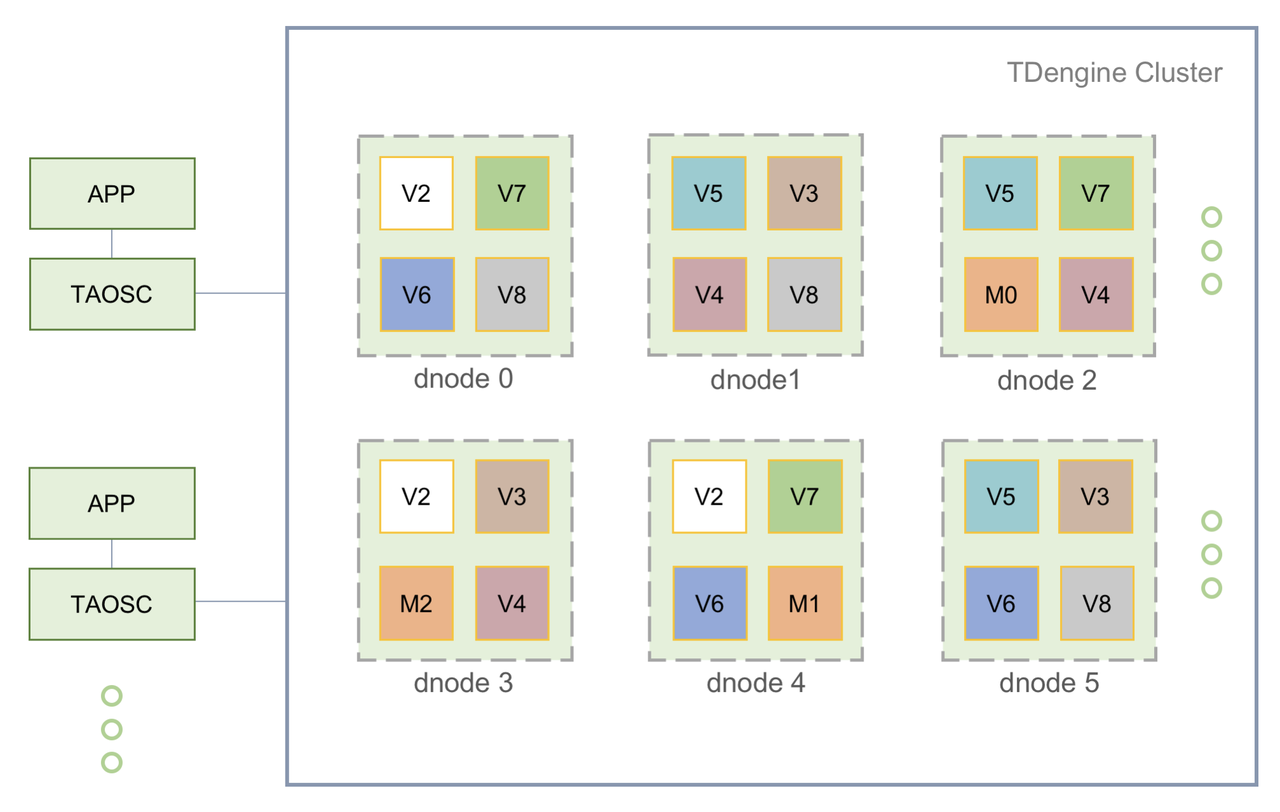
再来看一下 TDengine 的数据模型。
一个采集点一张表(时间戳作为主键,顺序存储)
一张表的数据在文件中以块的形式连续存放
文件中的数据块大小可配
采用 Block Range Index(BRIN)索引块数据
TDengine 中都有哪些数据需要缓存呢?
具体可以分为如下几类:
元数据 (table meta/stable vgroup)
连接数据 (rpc/http session)
查询缓存 (qinfo handle/ show info)
最新数据 (last 和 last_row)
时序数据 (buffer pool/ multilevel storage)
接下来我们就具体看一下 TDengine 中的缓存方案。
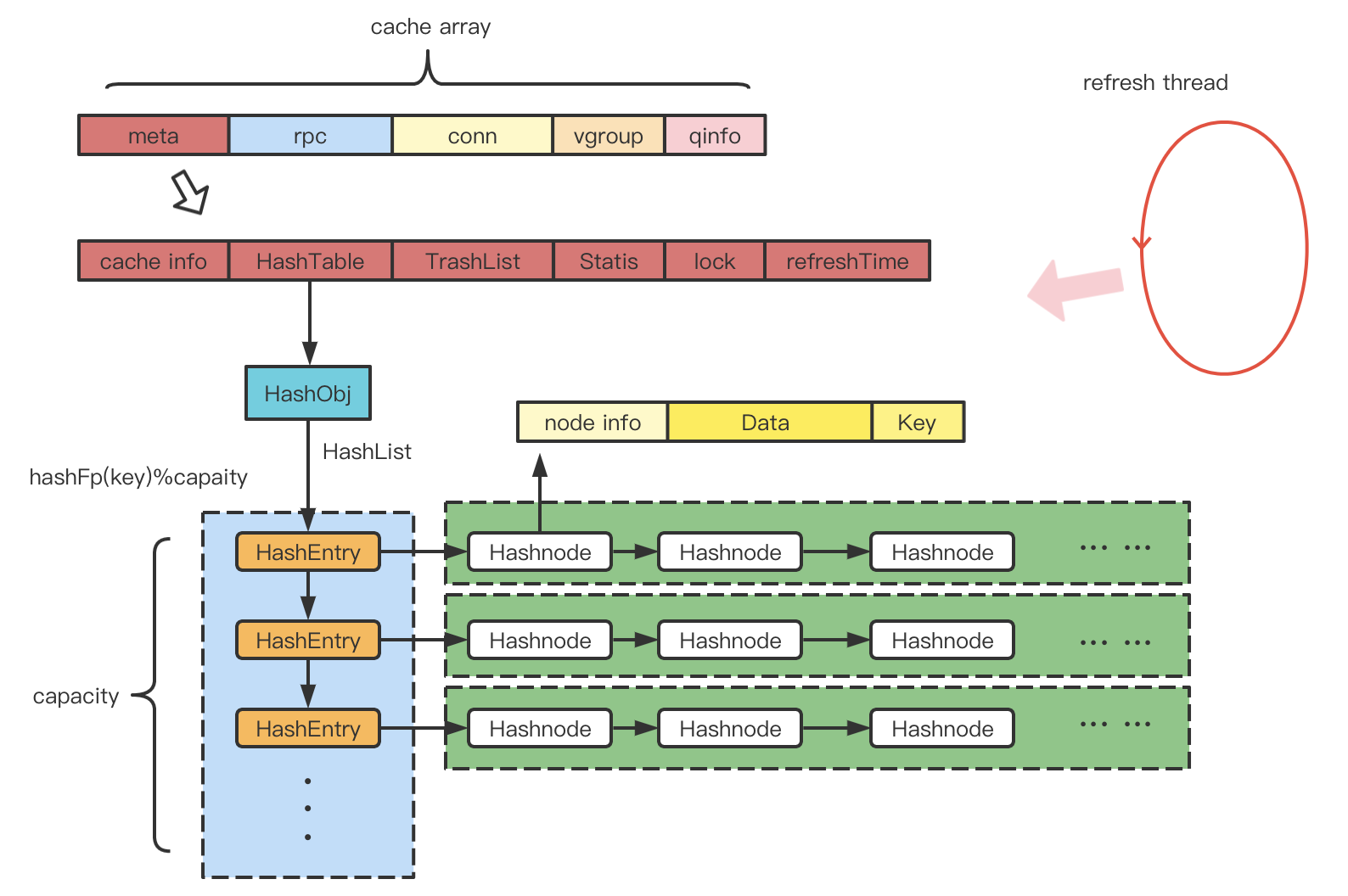
首先是通用的哈希缓存 (meta data/ rpcObj/ qinfo)。
哈希缓存,通过一个列表来管理,每个元素是一个缓存结构,里面包括缓存信息、 哈希表 、垃圾回收链表、统计信息、更新频率、锁等信息。此外,有一个刷新线程定时检测缓存列表中过期的数据,将其删除。
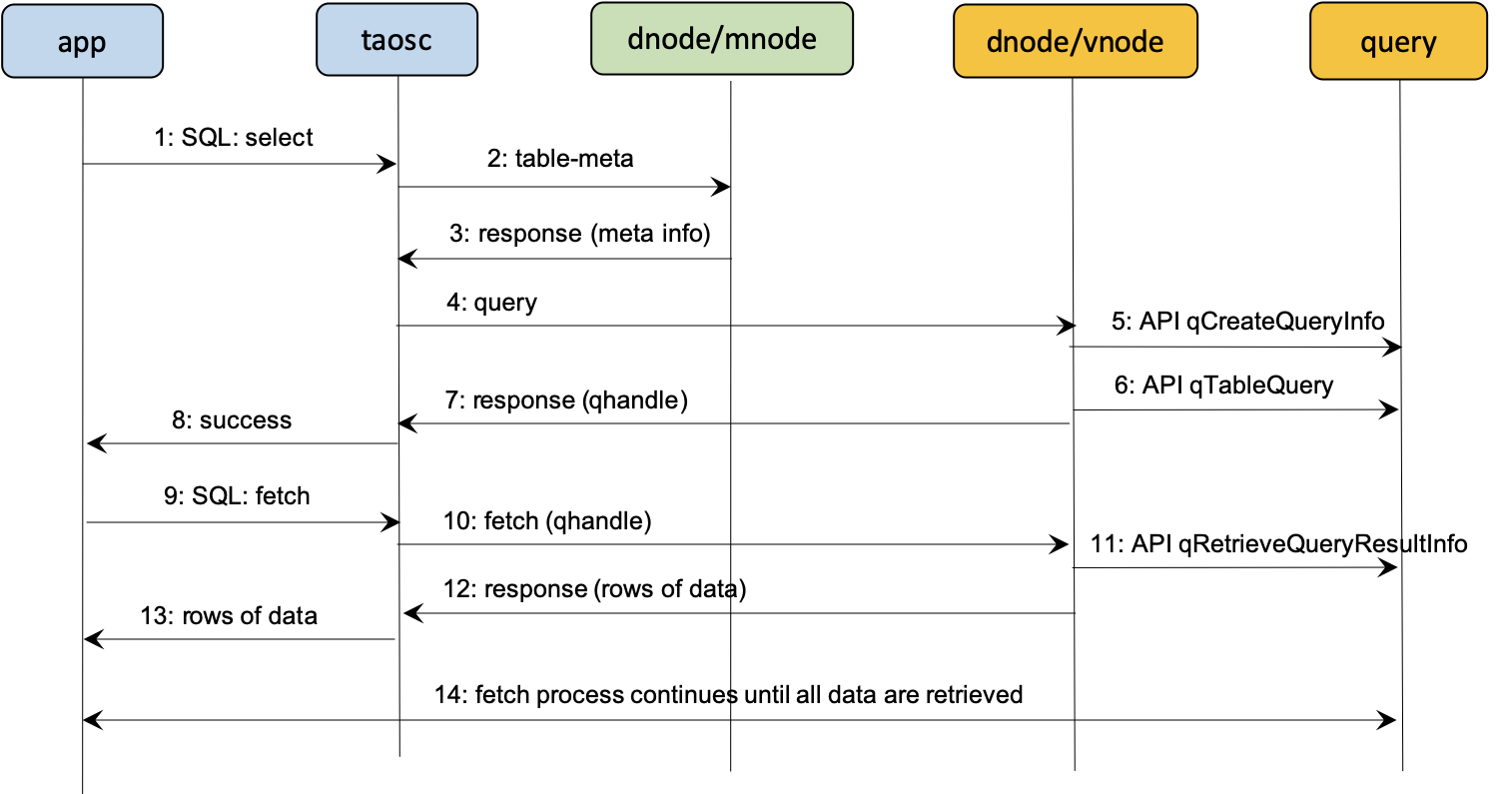
查询计划 id (query handle),query handle 是数据库查询时,server 先生产一个执行计划,返回给 client,然后 client 拿着这个计划 id,分多次去 server 取数据,直到数据查询完。这个缓存是消息时间范围,整个进程内有效的,不需要更新,使用完即释放。
元数据缓存(meta data), meta data 数据主要记录数据表的 scheme,所在的节点地址。通过客户端缓存 meta data 可以避免频繁的向 mnode 取数据。但是 meta 数据需要考虑更新一致性问题。通过版本号来控制。
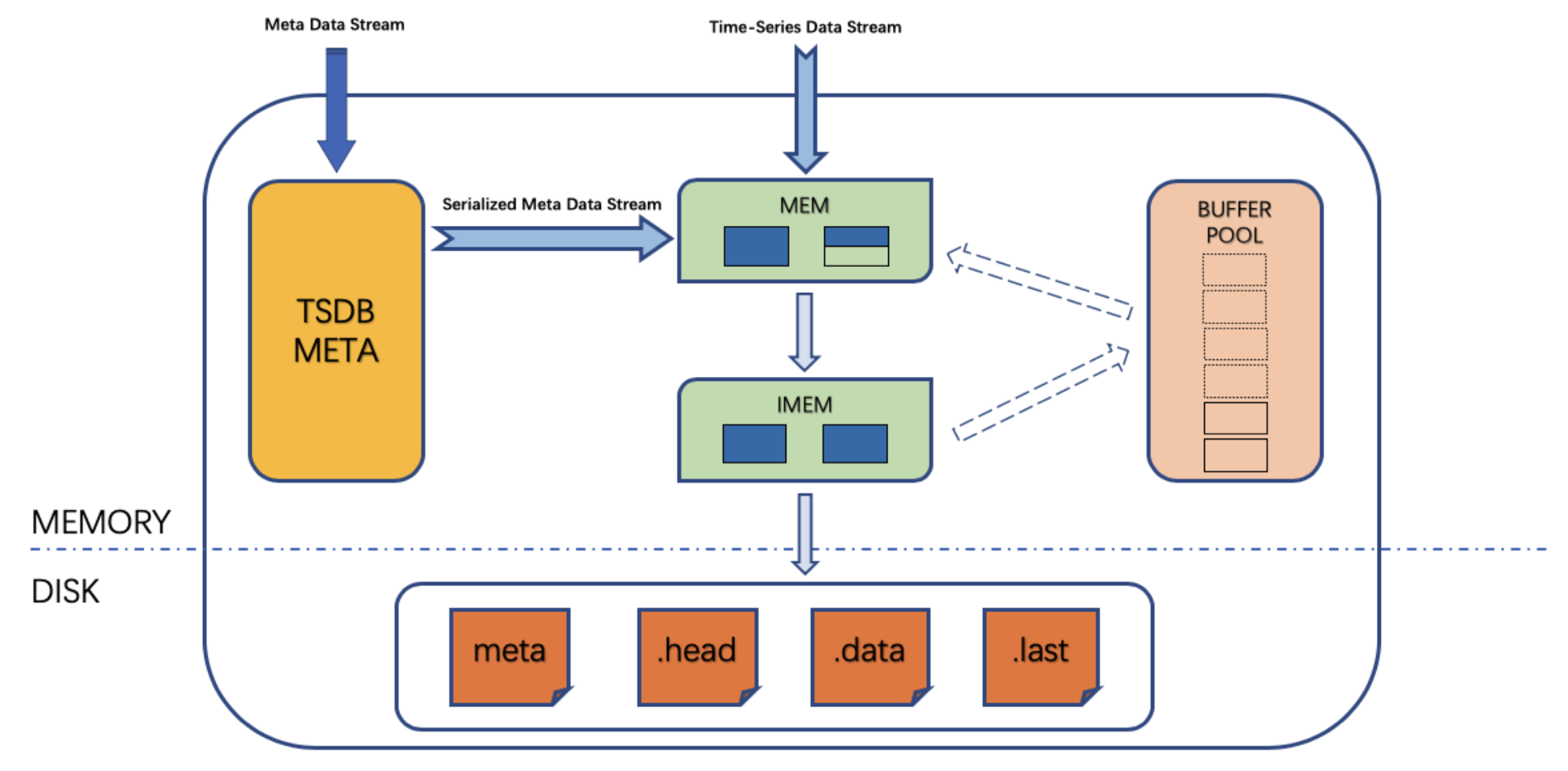
其次是 TSDB 内存块缓存 (double buffer/buffer pool)。
TDengine 提供双缓存/缓存池来优化数据写入查询的性能。预分配 16M*6 的 buffer pool,使用超过 1/3 容量落地,落地时 mem 转化为 imei(不可变更),负责写入磁盘。
直接将最近到达的数据保存在缓存中,可以更加快速地响应用户针对最近数据的查询分析,整体上提供更快的数据库查询响应能力。
TDengine 重启以后系统的缓存将被清空,之前缓存的数据均会被批量写入磁盘,之前缓存的数据不会重新加载到缓存中。
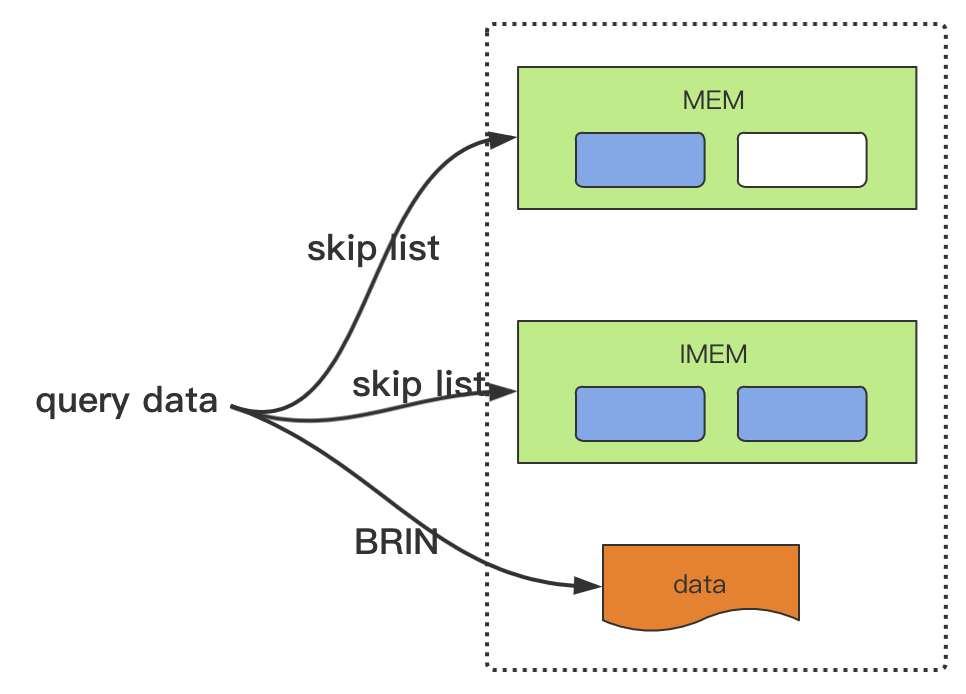
数据查询时首先通过 time range 定位数据所在的位置,因为 MEM 和 IMEM 中都记录有最新、最旧数据的时间戳。然后如果在 MEM 中,通过跳表来快速查询数据位置。在磁盘中,通过磁盘块文件索引查找数据,最后做结果融合返回。
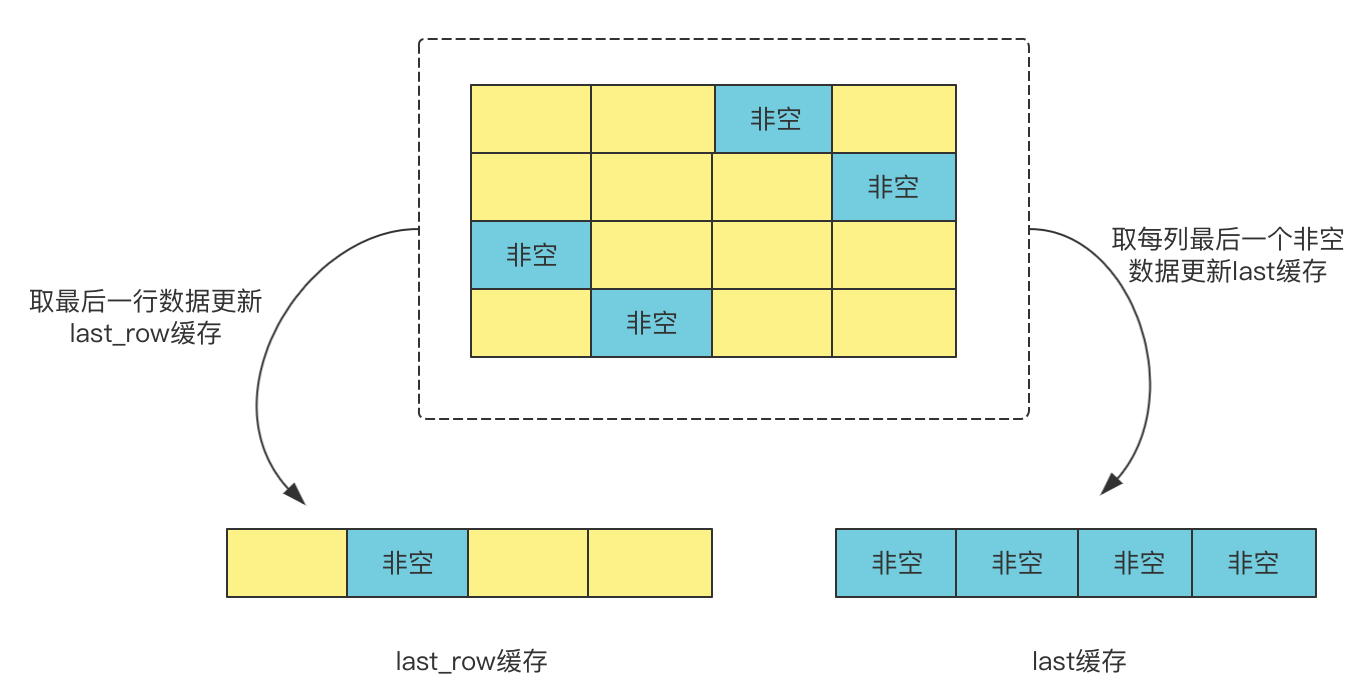
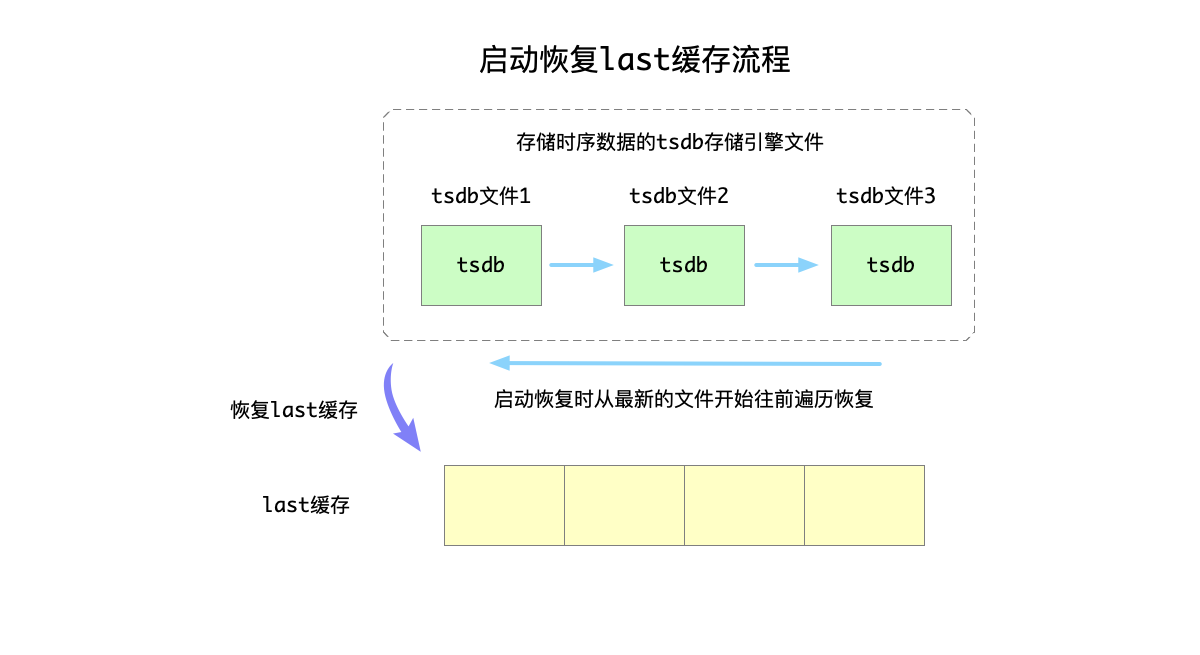
再来看 last 和 last_row 缓存 (local storage)。
时序数据库总是有对最新一行数据或者某列最新一条数据查询的需求,因此设计了 last 和 last_row 缓存来快速响应用户需求。防止每次都去磁盘查询数据。
每个表开辟缓存区缓存该数据,服务启动时会全量加载,插入时会更新,此外在配置更新的时候,也会更新缓存数据。比如,默认是关闭的。用户使用命令开启缓存功能时,就会加载数据,同理关闭开关时,会释放之前的缓存区。
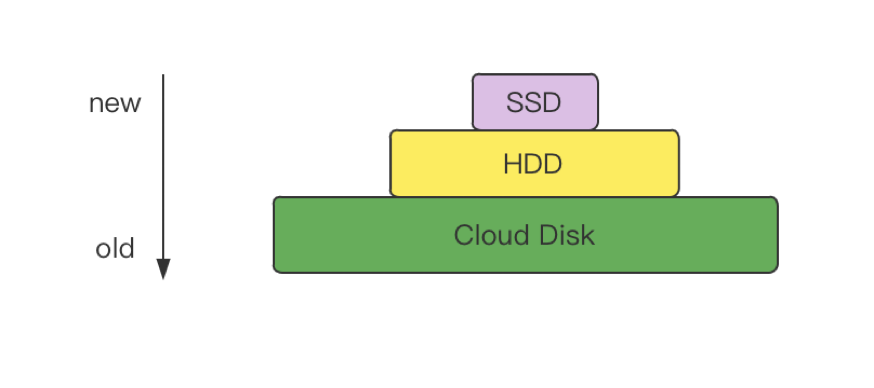
最后我们再来看一下多级存储 (ssd/hdd/cloud)。
由于物联网的数据量是巨大的,为了很好的平衡性能和成本,TDengine 还采用了分级存储的思想,不同热度数据存储在不同的地方。分级存储的这一思想也体现在计算机的体系结构里(寄存器、L1/L2 Cache、内存、硬盘)。
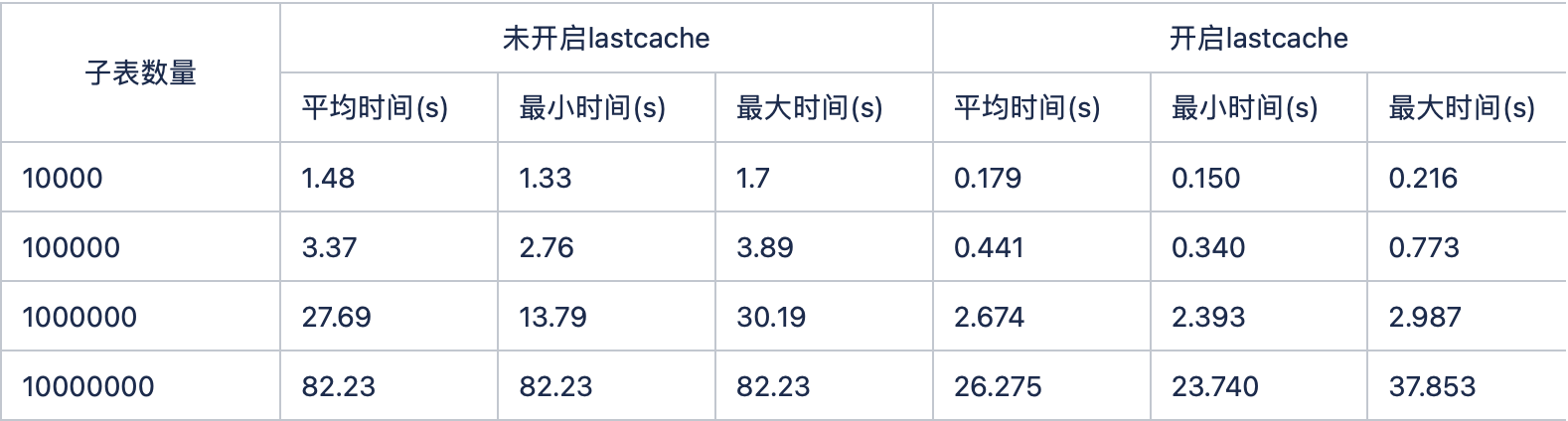
缓存对性能提升举例
测试环境: 12 核 i7 3.2GHz 64GB 4T HDD
last_row 缓存性能对比 (select last_row(*) from stable 查询语句 1000 次,统计查询时间)
last 缓存性能对比 (select last(*) from stable 和 select last_row(*) from stable 查询语句 1000 次,统计查询时间)
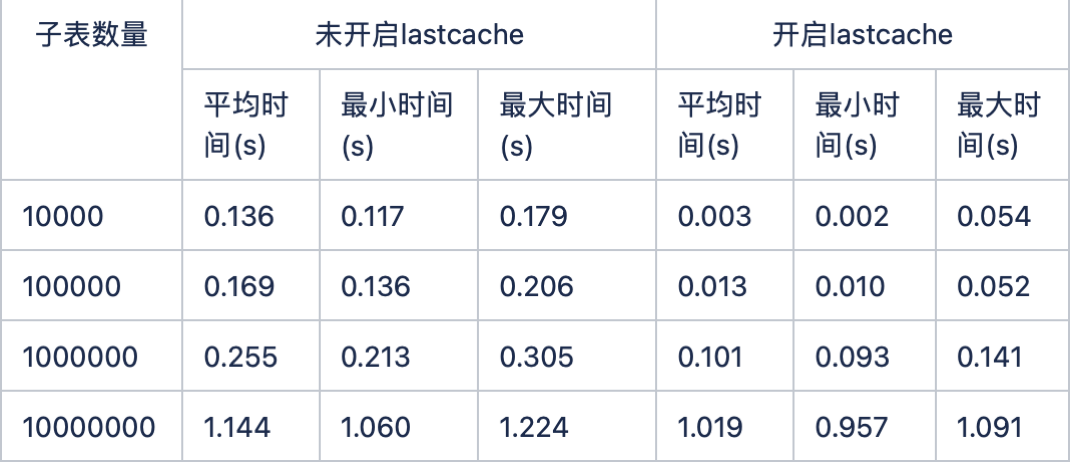
开启缓存性能比不开启缓存提升将近 1 个数量级。缓存对系统性能提升还是很大的,所以,在使用 TDengine 时,可以根据自己的需求,打开或关闭开关
问题及改进优化方向
先来看问题,主要是两点:
mnode 的 meta 数据全量加载,表数量很大时,内存占用大,启动慢;
last 和 last_row 缓存启动全量加载。
最后我们再来看一下优化方向:
全量加载改为动态加载;
预分配缓存大小,通过 LRU 等策略来更新数据;
qhandle 通过对象池管理,避免频繁 calloc。
如果想了解更具体的实现细节,可以在GitHub上查看相关源代码,也期待大家加入进来,一起改进TDengine!
关于作者
王明明,北京邮电大学毕业,主修方向为电子信息、模式识别和图像处理。毕业后入职腾讯,先后在 TEG 魔王工作室卡牌游戏开发、腾讯地图手图后台开发、腾讯看点知识图谱后台开发。对网络编程、RPC 框架原理、Redis 缓存等技术有深入的研究。
一文带你理解TDengine中的缓存技术的更多相关文章
- java中的缓存技术该如何实现
1缓存为什么要存在?2缓存可以存在于什么地方?3缓存有哪些属性?4缓存介质? 搞清楚这4个问题,那么我们就可以随意的通过应用的场景来判断使用何种缓存了. 1. 缓存为什么要存在?一 般情况下,一个网站 ...
- python中的缓存技术
python缓存技术 def console(a,b): print('进入函数') return (a,b) print(console(3,'a')) print(console(2,'b')) ...
- PHP开发中的缓存技术汇总
在PHP开发中,出于对网站服务器负载的考虑,往往需要对页面.数据等内容进行缓存处理,下面就来看看,在PHP开发中有哪些缓存方式吧. 1.页面部分缓存该种方式,是将一个页面中不经常变的部分进行静态缓存, ...
- ASP.NET中各种缓存技术的特点及使用场景
对于一些不经常改变却经常被request的数据,我们喜欢将它们缓存在内存.这样用户请求时先到缓存中去取,如果缓存中没有,再去数据库拿,提高响应速度.缓存一般实现在BLL,这样可以与DAL分离,更换数据 ...
- 从底层带你理解Python中的一些内部机制
下面博文将带你创建一个字节码级别的追踪API以追踪Python的一些内部机制,比如类似YIELDVALUE.YIELDFROM操作码的实现,推式构造列表(List Comprehensions).生成 ...
- 一文带您了解 Elasticsearch 中,如何进行索引管理(图文教程)
欢迎关注笔者的公众号: 小哈学Java, 每日推送 Java 领域干货文章,关注即免费无套路附送 100G 海量学习.面试资源哟!! 个人网站: https://www.exception.site/ ...
- 初探Java设计模式4:一文带你掌握JDK中的设计模式
转自https://javadoop.com/post/design-pattern 行为型模式 策略模式 观察者模式 责任链模式 模板方法模式 状态模式 行为型模式总结 本系列文章将整理到我在Git ...
- 最小生成树算法【图解】--一文带你理解什么是Prim算法和Kruskal算法
假设以下情景,有一块木板,板上钉上了一些钉子,这些钉子可以由一些细绳连接起来.假设每个钉子可以通过一根或者多根细绳连接起来,那么一定存在这样的情况,即用最少的细绳把所有钉子连接起来. 更为实际的情景是 ...
- 一文带你认识Java8中接口的默认方法
Java8是Oracle于2014年3月发布的一个重要版本,其API在现存的接口上引入了非常多的新方法. 例如,Java8的List接口新增了sort方法.在Java8之前,则每个实现了List接口的 ...
随机推荐
- K8s一键安装
安装案例: 系统:Centos可以多台Master(Master不能低于3台)多台Node此案例使用三台Master两台Node,用户名root,密码均为123456 master 192.168.2 ...
- Jmeter导出测试报告
测试数据概述 jemter导出数据 另存为导出csv文件 命令行导出 测试报告的作用: 反馈结果 复现问题,所以需要写明测试场景.数据
- Loj#6503-「雅礼集训 2018 Day4」Magic【分治NTT】
正题 题目链接:https://loj.ac/p/6503 题目大意 \(n\)张卡\(m\)种,第\(i\)种卡有\(a_i\)张,求所有排列中有\(k\)对相邻且相同的卡牌. \(1\leq n\ ...
- windows下如何查看所有端口及占用
1.在windows下查看所有端口: 先点击电脑左下角的开始,然后选择运行选项,接着我们在弹出的窗口中,输入[cmd]命令,进行命令提示符. 然后我们在窗口中输入[netstat -ano]按下回车, ...
- 利用Java Agent进行代码植入
利用Java Agent进行代码植入 Java Agent 又叫做 Java 探针,是在 JDK1.5 引入的一种可以动态修改 Java 字节码的技术.可以把javaagent理解成一种代码注入的方式 ...
- Linux文件系统与inode、Block笔记
Linux文件系统与inode.Block笔记 在Linux下一切都是文件,无论是设备还是接口,亦或是网卡等均被抽象成了文件,并且有相关的内核代码进行调度.然而,在一切都是文件的前提下,最需要进行探讨 ...
- ubuntu20.04安装网易云音乐
Ubuntu20.04安装网易云 进入网易云音乐下载地址 下载对应客户端 进入终端,安装 sudo dpkg -i 软件名.deb
- 微服务+异步工作流+ Serverless,Netflix 决定弃用稳定运行 7 年的旧平台
作者 | Frank San Miguel 策划 | 田晓旭 2021 年,Netflix 会将大部分的工作负载从 Reloaded 转移到 Cosmos 平台.Cosmos 是一个计算平台,它将微服 ...
- 痞子衡嵌入式:i.MXRT全系列下FlexSPI外设AHB Master ID定义与AHB RX Buffer指定的异同
大家好,我是痞子衡,是正经搞技术的痞子.今天痞子衡给大家介绍的是i.MXRT全系列下FlexSPI外设AHB Master ID定义与AHB RX Buffer指定的异同. 因为 i.MXRT 全系列 ...
- Cartography Tools(制图工具)
制图工具 1.制图优化 # Process: 分散标记 arcpy.DisperseMarkers_cartography("", "", "EXPA ...