AUGMIX : A SIMPLE DATA PROCESSING METHOD TO IMPROVE ROBUSTNESS AND UNCERTAINTY
概
本文介绍AUGMIX算法——对现有的的一些augmentation方法进行混用, 并构建了一个新的损失函数.
主要内容


其中\(\mathrm{Dirichlet}\)为狄利克雷分布.
通过实验指出, Augmentation的混用(增加样本的多样性)以及损失函数的设计都是有利于稳定性以及不确定度的.
\]
其中\(M:= (p_{orig} + p_{augmix1}+p_{augmix2})/3\).
实验的指标
Clean Error: 指在干净样本上的错误率;
\(E_{c,s}\): 指在困难等级\(1 \le s \le 5\), 污染(摄动, corruption) \(c\)下的错误率;
\(CE_c = \sum_{s=1}^5E_{c,s}/ \sum_{s=1}^5 E_{c,s}^{\mathrm{Alexnet}}\);
\(mCE\): \(\mathrm{mean}_{c} \: CE_{c}\);
flip probability (FP): 微小摄动下, 样本预测类改变的概率; 如何估计?
\(mFP\): the mean flip probability (对于所有的\(c\)); -衡量鲁棒性;
\(mFR\): \(mFP\) 比上 Alexnet 的\(mFP\) ;
不确定估计:
\]
其中\(C\)为预测\(\hat{Y}\)正确的\(confidence\)(如果输出是一个概率向量, 那么就应当是对应类别的概率), 采用如下方式估计:
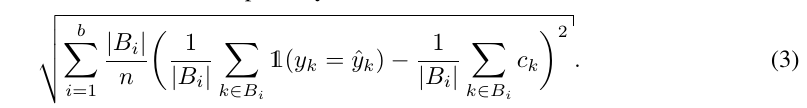
其中\(B_i\), 是我们按照confidence的序来将测试样本分割为\((B_1, B_2, \ldots, B_b)\).
AUGMIX : A SIMPLE DATA PROCESSING METHOD TO IMPROVE ROBUSTNESS AND UNCERTAINTY的更多相关文章
- In-Stream Big Data Processing
http://highlyscalable.wordpress.com/2013/08/20/in-stream-big-data-processing/ Overview In recent y ...
- Linux command line exercises for NGS data processing
by Umer Zeeshan Ijaz The purpose of this tutorial is to introduce students to the frequently used to ...
- [翻译]MapReduce: Simplified Data Processing on Large Clusters
MapReduce: Simplified Data Processing on Large Clusters MapReduce:面向大型集群的简化数据处理 摘要 MapReduce既是一种编程模型 ...
- 用于Simple.Data的ASP.NET Identity Provider
今天推举的这篇文章,本意不是要推举文章的内容,而是据此介绍一下Simple.Data这个很有意思的类ORM工具. 现在大家在.NET开发中如果需要进行数据访问,那么基本都会使用一些ORM工具,比如微软 ...
- Simple Data
Git地址:https://github.com/markrendle/Simple.Data 来源:http://bbs.nfinal.com/read-13
- 学习simple.data之高级篇
一.调用存储过程 1.不带参数 CREATE PROCEDURE ProcedureWithoutParams AS SELECT * FROM ORDER; 调用db.ProcedureWithou ...
- 学习simple.data之基础篇
simple.data是一个轻量级的.动态的数据访问组件,支持.net4.0. 1.必须条件和依赖性: v4.0 or greater of the .NET framework, or v2.10 ...
- 关于Simple.Data.PostgreSql的ExecuteReader没实现非常坑爹的问题
https://github.com/ChrisMH/Simple.Data.PostgreSql/issues/3 github上有个issues...默认从nuget上下载的Simple.Data ...
- SQL Server Reporting Services 自定义数据处理扩展DPE(Data Processing Extension)
最近在做SSRS项目时,遇到这么一个情形:该项目有多个数据库,每个数据库都在不同的服务器,但每个数据库所拥有的数据库对象(table/view/SPs/functions)都是一模一样的,后来结合网络 ...
随机推荐
- 关于java中的安全管理器
最近再查看java的源码的时候看见了这一类代码 final SecurityManager sm = System.getSecurityManager(); 想要了解这个是为了做什么,查看资料之后发 ...
- day07 MySQL索引事务
day07 MySQL索引事务 昨日内容回顾 pymysql模块 # 链接数据库都是使用这个模块的 # 创建链接 import pymysql conn = pymysql.connect( host ...
- Maven 目录结构[转载]
转载至:http://www.cnblogs.com/haippy/archive/2012/07/05/2577233.html Maven 标准目录结构 好的目录结构可以使开发人员更容易理解项目, ...
- Ibatis中SqlMapClientTemplate和SqlMapClient的区别
SqlMapClientTemplate是org.springframework.orm.ibatis下的 而SqlMapClient是ibatis的 SqlMapClientTemplate是Sql ...
- linux-源码软件管理-yum配置
总结如下:1.源码配置软件管理2.配置yum本地源和网络源及yum 工作原理讲解3.计算机硬盘介绍 1.1 源码管理软件 压缩包管理命令: # 主流的压缩格式包括tar.rar.zip.war.gzi ...
- Java SPI机制,你了解过吗?
Life moves pretty fast,if you don't stop and look around once in a while,you will miss it 为什么需要SPI? ...
- DP笔记
这是一篇蒟蒻被大佬踩爆后写的笔记 套路 0.贪心(废话)(排序...) 1.dp预处理出要用的东西 2.两头同时dp 3.化简题目中本质相同的东西 转化模型 4.数学计算优化 5.分析题目数据考虑该从 ...
- podman wsl2在windows重启后出错
1. error joining network namespace for container 如果没有先停止容器就重启windows,极大概率就会出现这个问题 解决方法 先停止停止的容器再启动已退 ...
- 学习整理--flex布局(1)
父元素容器属性 flex-direction: row(默认).row-reverse.column.column-reverse row: 横向正序排列子元素 colimn: 竖向正序排列子元素 r ...
- typeScript基本概念
我一直认为学习是知识的累加,而前端技术也是进步的.所以学习的重点就是,'它有什么不同,它好在哪里'.这要求我们必须结合之前的经验和知识去学习一门新技术,而不是无情的复制粘贴机器. 首先,ts的官方定义 ...