R语言六种数据类型
1 向量
1.1 定义向量
向量使用c来赋值,向量中不能混合不同类型的数据
x<-c(2,3,7,6,8) 数值型num
y<-("one","two","three") 字符型chr
z<-c(TRUE,TRUE,FALSE) 逻辑型logi
查看变量的类型:class(x)
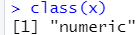
1.2 访问向量
访问中的元素,使用中括号(R语言区分大小写),R语言索引从1开始
访问第二个元素:x[2]
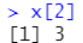
访问第1和第3个元素:x[c(1,3)]
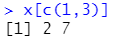
访问第1都第3的元素:x[c(1:3)] 或者x[1:3]

2 矩阵
2.1 定义矩阵
矩阵是二维的,矩阵中的数据类型不能混合
矩阵创建使用matrx():
x<-matrix(1:20,nrow=5,ncol=4)
解释 : 1:20定义了矩阵中的数据是1到20,规定了5行4列,默认情况下矩阵按列填充

添加一个字段byrow=T,是否按行填充,设置为TRUE或者T :
x1<-matrix(1:20,nrow=5,ncol=4,byrow=T)

2.2 矩阵的索引
获取第1行:x1[1,]
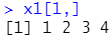
获取第3列:x1[,3]
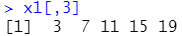
获取第3行第4列:x1[3,4]
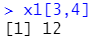
获取第3行第1,2列:x1[3,c(1,2)]

3 数组
3.1 定义数组
数组可以是二维,三维,使用array创建,定义2行3列的4张表
定义变量:
d1<-c("m1","m2")
d2<-c("n2","n2","n3")
d3<-c("p1","p2","p3","p4")
使用array组合成数组:
x2<-array(1:24,c(2,3,4),dimnames = list(d1,d2,d3))
解释: 1:24用来个创建的数组填充数据,c(2,3,4)用来确定数组的维度,dimnames用来给创建的数组取名字(以下是部分截图)

4 数据框
4.1 定义数据框
数据框可以混合不同类型的数据
首先定义几个变量:
patientID<-c(1,2,3,4)
age<-c(26,30,27,48)
diabetes<-c("type1","type2","type1","type2")
status<-c("poor","improved","excellent","poor")
使用data.frame构成数据框:
pt<-data.frame(patientID,age,diabetes,status)

4.2 访问数据框
访问数据框用中括号,访问第1和第2列:p1<-pt[1:2]

使用列名,访问某列:p2<-pt[c("age","status")]

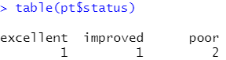
4.3频数表和交叉表
频数分析:table(pt$status)
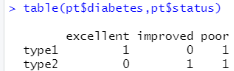
交叉分析:table(pt$diabetes,pt$status)
4.4变量搜索路径指定
(1)用attach将表添加到搜索路径(为了避免每次都要写$):attach(pt)

不需要这个表用detach,语句是:detach(pt)
(2)不想每次写表名,还可以使用with:
with(mtcars,{
+ plot(mpg,disp)
+ plot(mpg,wt)
+ })


在实际应用中建议把表名写清楚,不建议这样做
5 因子factor
5.1名义型变量
diabetes<-c("type1","type2","type1","type2")
diabetes1<-factor(diabetes)

5.2 有序型变量order,值顺序指定level
status<-c("poor","improved","excellent","poor")
status1<-factor(status,ordered = T,levels = c("poor","improved","excellent"))

5.3 案例(作业)
有因子变量在表中:
patientID<-c(1,2,3,4)
age<-c(26,30,27,48)
diabetes<-c("type1","type2","type1","type2")
status<-c("poor","improved","excellent","poor")
diabetes1<-factor(diabetes)
status1<-factor(status,ordered = T,levels = c("poor","improved","excellent"))
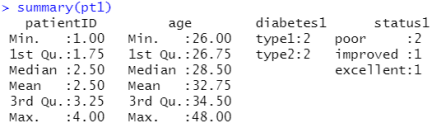
Pt1<-data.frame(patientID,age,diabetes1,status1)
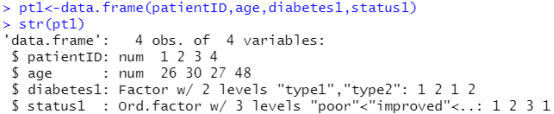
分析这个表使用summary(pt1),patientID和age为数值型,所以计算了它们的最大最小均值等,diabetes1和status1为因子变量,所以统计了它们的属性出现的次数。
6 列表list,可以混合以上各种数据
6.1 列表的定义
首先定义几个变量:
x<-"aaaa"
y<-c(22,44,55)
z<-matrix(1:9,nrow=3)
k<-c("one","two","three")
list1<-list(x,y,z,k)

给列表中的元素赋值:list2<-list(var1=x,var2=y,var3=z,var4=k)

6.2 列表的访问
用两个中括号或者访问名字
list2[[1]]
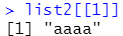
list2[["var1"]]

6.3 列表的用途
R语言的很多分析结果,都是以list形式返回的
R语言六种数据类型的更多相关文章
- 大数据平台R语言web UI应用架构 设计与开发
1. 系统拓扑图 在日常业务分析中,R是非常常用的分析工具,而当数据量较大时,用R语言需要需用更多的时间来完成训练模型,spark作为大规模数据处理框架,采用内存计算,可以短时间内完成大量的数据的处理 ...
- R语言入门(一)简介安装
数据挖掘常用的语言有R语言,python,SQL等,其中R语言最受欢迎.(注:SQL Server包含微软研究院开发的两种数据挖掘算法:Microsoft决策树和Microsoft聚集,此外还支持第三 ...
- 第二章 R语言数据结构
R语言存储数据的结构包括:标量.向量.矩阵.数组.数据框和列表:可以处理的数据类型包括:数值型.字符型.逻辑型.复数型和原生型. 数据结构 向量 向量是用来存储数值型.字符型或逻辑型数据的一维数组.单 ...
- No.1 R语言在生物信息中的应用——序列读取及格式化输出
目的:读入序列文件(fasta格式),返回一个数据框,内容包括--存储ID.注释行(anno).长度(len).序列内容(content) 一.问题思考: 1. 如何识别注释行和序列内容行 2. 如何 ...
- R语言 数据类型
R语言数据类型 通常,在使用任何编程语言进行编程时,您需要使用各种变量来存储各种信息. 变量只是保留值的存储位置. 这意味着,当你创建一个变量,你必须在内存中保留一些空间来存储它们. 您可能想存储各种 ...
- R语言编程艺术# 数据类型向量(vector)
R语言最基本的数据类型-向量(vector) 1.插入向量元素,同一向量中的所有的元素必须是相同的模式(数据类型),如整型.数值型(浮点数).字符型(字符串).逻辑型.复数型等.查看变量的类型可以用t ...
- R语言数据类型
R语言数据类型[转!!]Zhao-Pace https://www.cnblogs.com/zhao441354231/p/5970544.html R语言用来存储数据的对象包括: 向量, 因子 ...
- R语言编程艺术#01#数据类型向量(vector)
R语言最基本的数据类型-向量(vector) 1.插入向量元素,同一向量中的所有的元素必须是相同的模式(数据类型),如整型.数值型(浮点数).字符型(字符串).逻辑型.复数型等.查看变量的类型可以用t ...
- R语言数据类型与数据结构
一.数据类型 5种 1.character 字符 2.numeric 数值 3.integer 整数 一般数字的存储会默认为数值类型,如果要强调是整数,需要在变量值后面加上 L. x <- 5L ...
随机推荐
- 三分钟了解B2B CRM系统的特点
最近很多朋友想了解什么是B2B CRM系统,说到这里小Z先来给大家说说什么是B2B--B2B原本写作B to B,是Business-to-Business的缩写.正常来说就是企业与企业之间的生意往来 ...
- Gin框架介绍与使用
Gin // 初识 Gin框架 //下载(可能会下载不全.缺什么get什么即可) //go get -u -v github.com/gin-gonic/gin package main import ...
- U盘PE重装系统导致D、E、F盘消失
U盘PE重装系统导致D.E.F盘消失 听语音 原创 | 浏览:1251 | 更新:2014-08-18 18:46 | 标签:u盘 重装 解决使用U盘PE重装系统导致的错误问题 工具/原料 制作好 ...
- centos下查看网卡,主板,CPU,显卡,硬盘型号等硬件信息
centos下查看网卡,主板,CPU,显卡,硬盘型号等硬件信息 rose_willow rose_willow 发布于 2016/06/16 11:32 字数 902 阅读 405 收藏 0 点赞 0 ...
- rsync同步遇到的报错和解决办法
rsync同步遇到的报错和解决办法 科技小能手 2017-11-12 18:27:00 浏览1125 配置 code 同步 open stream file read 在同步的客户端操作: [ ...
- mysql基础之mysql主从架构半同步复制
一.概念 1.异步复制(Asynchronous replication) MySQL默认的复制即是异步的,主库在执行完客户端提交的事务后会立即将结果返给给客户端,并不关心从库是否已经接收并处理,这样 ...
- 常用Python第三方库简介
如果说强大的标准库奠定了Python发展的基石,丰富的第三方库则是python不断发展的保证,随着python的发展一些稳定的第三库被加入到了标准库里面,这里有6000多个第三方库的介绍 下表中加粗并 ...
- systemverilog数组类型
- 【分布式】-- 微服务抽奖系统后台整合MyBatis-Plus
1.整合MyBatis-Plus背景 [分布式]-- 基于Nacos.OpenFeign搭建的微服务抽奖系统后台小案例 本篇是基于上一篇博文微服务抽奖系统后台对持久层MyBatis进行更换,并整合My ...
- Runtime PM 处理不当导致的 external abort on non-linefetch 案例分享
硬件平台:某ARM SoC 软件平台:Linux 1 Runtime PM 简介 在介绍 Runtime PM 之前,不妨先看看传统的电源管理.传统的电源管理机制,称之为 System PM(Syst ...