Java 并发之 Fork/Join 框架
什么是 Fork/Join 框架
Fork/Join 框架是一种在 JDk 7 引入的线程池,用于并行执行把一个大任务拆成多个小任务并行执行,最终汇总每个小任务结果得到大任务结果的特殊任务。通过其命名也很容易看出框架主要分为 Fork 和 Join 两个阶段,第一阶段 Fork 是把一个大任务拆分为多个子任务并行的执行,第二阶段 Join 是合并这些子任务的所有执行结果,最后得到大任务的结果。
这里不难发现其执行主要流程:首先判断一个任务是否足够小,如果任务足够小,则直接计算,否则,就拆分成几个更小的小任务分别计算,这个过程可以反复的拆分成一系列小任务。Fork/Join 框架是一种基于 分治 的算法,通过拆分大任务成多个独立的小任务,然后并行执行这些小任务,最后合并小任务的结果得到大任务的最终结果,通过并行计算以提高效率。。
Fork/Join 框架使用示例
下面通过一个计算列表中所有元素的总和的示例来看看 Fork/Join 框架是如何使用的,总的思路是:将这个列表分成许多子列表,然后对每个子列表的元素进行求和,然后,我们再计算所有这些值的总和就得到原始列表的和了。Fork/Join 框架中定义了 ForkJoinTask 来表示一个 Fork/Join 任务,其提供了 fork()、join() 等操作,通常情况下,我们并不需要直接继承这个 ForkJoinTask 类,而是使用框架提供的两个 ForkJoinTask 的子类:
- RecursiveAction 用于表示没有返回结果的 Fork/Join 任务。
- RecursiveTask 用于表示有返回结果的 Fork/Join 任务。
很显然,在这个示例中是需要返回结果的,可以定义 SumAction 类继承自 RecursiveTask,代码入下:
/**
* @author mghio
* @since 2021-07-25
*/
public class SumTask extends RecursiveTask<Long> {
private static final int SEQUENTIAL_THRESHOLD = 50;
private final List<Long> data;
public SumTask(List<Long> data) {
this.data = data;
}
@Override
protected Long compute() {
if (data.size() <= SEQUENTIAL_THRESHOLD) {
long sum = computeSumDirectly();
System.out.format("Sum of %s: %d\n", data.toString(), sum);
return sum;
} else {
int mid = data.size() / 2;
SumTask firstSubtask = new SumTask(data.subList(0, mid));
SumTask secondSubtask = new SumTask(data.subList(mid, data.size()));
// 执行子任务
firstSubtask.fork();
secondSubtask.fork();
// 等待子任务执行完成,并获取结果
long firstSubTaskResult = firstSubtask.join();
long secondSubTaskResult = secondSubtask.join();
return firstSubTaskResult + secondSubTaskResult;
}
}
private long computeSumDirectly() {
long sum = 0;
for (Long l : data) {
sum += l;
}
return sum;
}
public static void main(String[] args) {
Random random = new Random();
List<Long> data = random
.longs(1_000, 1, 100)
.boxed()
.collect(Collectors.toList());
ForkJoinPool pool = new ForkJoinPool();
SumTask task = new SumTask(data);
pool.invoke(task);
System.out.println("Sum: " + pool.invoke(task));
}
}
这里当列表大小小于 SEQUENTIAL_THRESHOLD 变量的值(阈值)时视为小任务,直接计算求和列表元素结果,否则再次拆分为小任务,运行结果如下:
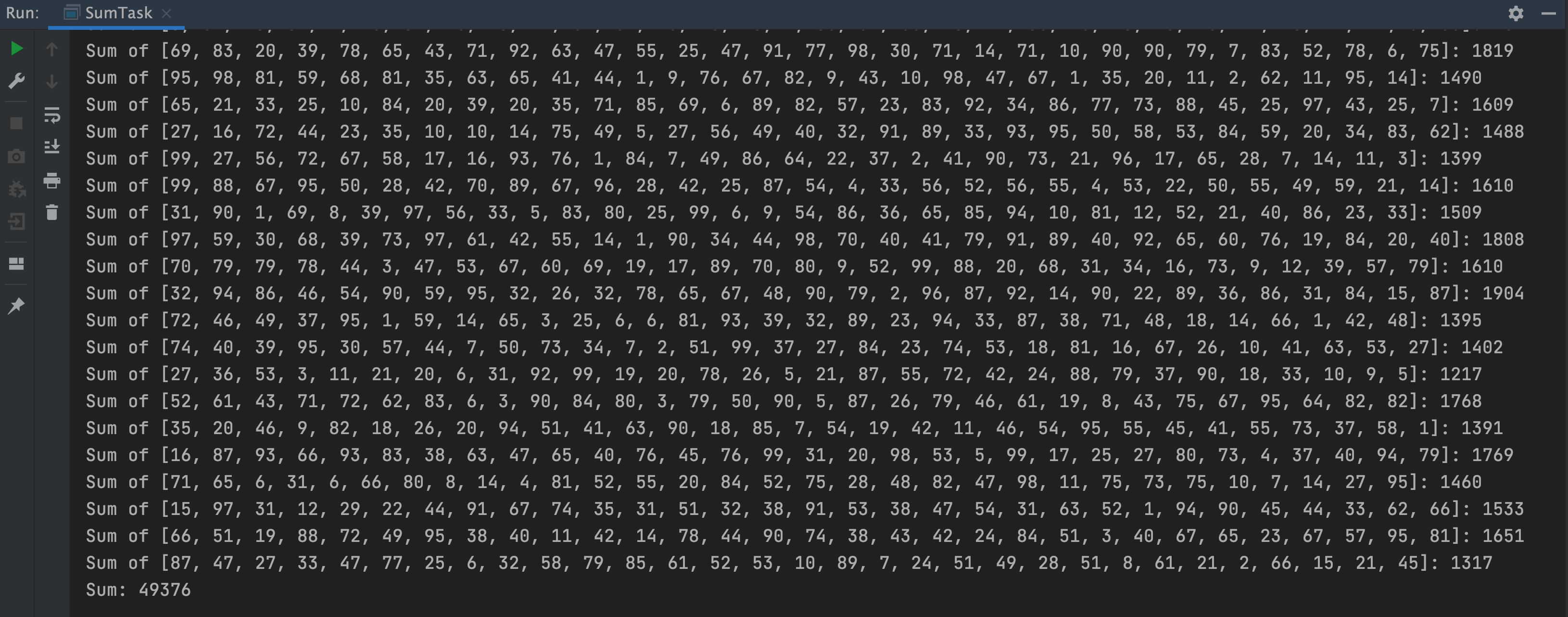
通过这个示例代码可以发现,Fork/Join 框架 中 ForkJoinTask 任务与平常的一般任务的主要不同点在于:ForkJoinTask 需要实现抽象方法 compute() 来定义计算逻辑,在这个方法里一般通用的实现模板是,首先先判断当前任务是否是小任务,如果是,就执行执行任务,如果不是小任务,则再次拆分为两个子任务,然后当每个子任务调用 fork() 方法时,会再次进入到 compute() 方法中,检查当前任务是否需要再拆分为子任务,如果已经是小任务,则执行当前任务并返回结果,否则继续分割,最后调用 join() 方法等待所有子任务执行完成并获得执行结果。伪代码如下:
if (problem is small) {
directly solve problem.
} else {
Step 1. split problem into independent parts.
Step 2. fork new subtasks to solve each part.
Step 3. join all subtasks.
Step 4. compose result from subresults.
}
Fork/Join 框架设计
Fork/Join 框架核心思想是把一个大任务拆分成若干个小任务,然后汇总每个小任务的结果最终得到大任务的结果,如果让你设计一个这样的框架,你会如何实现呢?(建议思考一下),Fork/Join 框架的整个流程正如其名所示,分为两个步骤:
- 大任务分割 需要有这么一个的类,用来将大任务拆分为子任务,可能一次拆分后的子任务还是比较大,需要多次拆分,直到拆分出来的子任务符合我们定义的小任务才结束。
- 执行任务并合并任务结果 第一步拆分出来的子任务分别存放在一个个 双端队列 里面(P.S. 这里为什么要使用双端队列请看下文),然后每个队列启动一个线程从队列中获取任务执行。这些子任务的执行结果都会放到一个统一的队列中,然后再启动一个线程从这个队列中拿数据,最后合并这些数据返回。
Fork/Join 框架使用了如下两个类来完成以上两个步骤:
- ForkJoinTask 类 在上文的实例中也有提到,表示 ForkJoin 任务,在使用框架时首先必须先定义任务,通常只需要继承自 ForkJoinTask 类的子类 RecursiveAction(无返回结果) 或者 RecursiveTask(有返回结果)即可。
- ForkJoinPool 从名字也可以猜到一二了,就是用来执行 ForkJoinTask 的线程池。大任务拆分出的子任务会添加到当前线程的双端队列的头部。
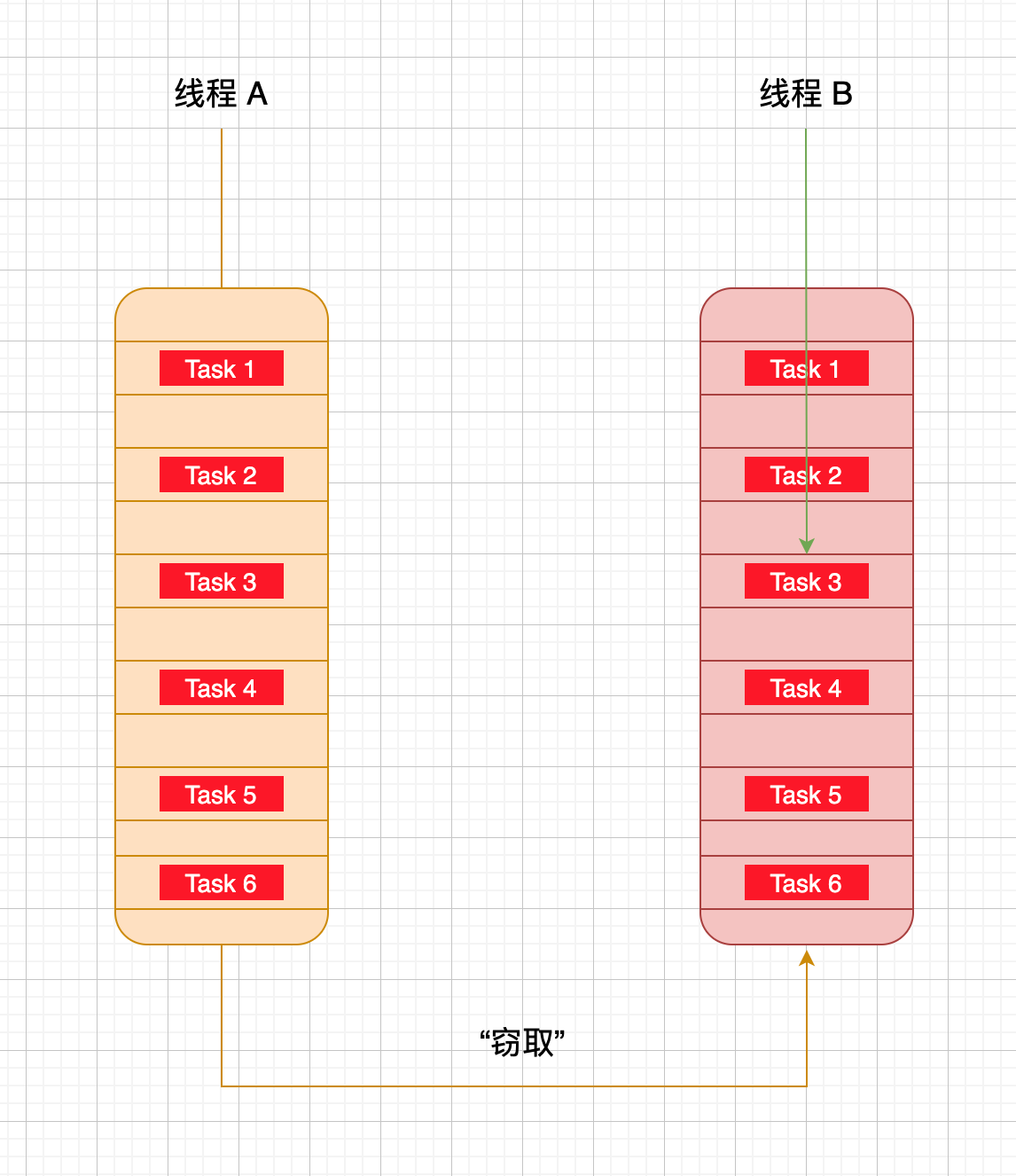
喜欢思考的你,心中想必会想到这么一种场景,当我们需要完成一个大任务时,会先把这个大任务拆分为多个独立的子任务,这些子任务会放到独立的队列中,并为每个队列都创建一个单独的线程去执行队列里的任务,即这里线程和队列时一对一的关系,那么当有的线程可能会先把自己队列的任务执行完成了,而有的线程则没有执行完成,这就导致一些先执行完任务的线程干等了,这是个好问题。
既然是做并发的,肯定要最大程度压榨计算机的性能,对于这种场景并发大师 Doug Lea 使用了工作窃取算法处理,使用工作窃取算法后,先完成自己队列中任务的线程会去其它线程的队列中”窃取“一个任务来执行,哈哈,一方有难,八方支援。但是此时这个线程和队列的持有线程会同时访问同一个队列,所以为了减少窃取任务的线程和被窃取任务的线程之间的竞争,ForkJoin 选择了双端队列这种数据结构,这样就可以按照这种规则执行任务了:被窃取任务的线程始终从队列头部获取任务并执行,窃取任务的线程使用从队列尾部获取任务执行。这个算法在绝大部分情况下都可以充分利用多线程进行并行计算,但是在双端队列里只有一个任务等极端情况下还是会存在一定程度的竞争。
Fork/Join 框架实现原理
Fork/Join 框架的实现核心是 ForkJoinPool 类,该类的重要组成部分为 ForkJoinTask 数组和 ForkJoinWorkerThread 数组,其中 ForkJoinTask 数组用来存放框架使用者给提交给 ForkJoinPool 的任务,ForkJoinWorkerThread 数组则负责执行这些任务。任务有如下四种状态:
- NORMAL 已完成
- CANCELLED 被取消
- SIGNAL 信号
- EXCEPTIONAL 发生异常
下面来看看这两个类的核心方法实现原理,首先来看 ForkJoinTask 的 fork() 方法,源码如下:
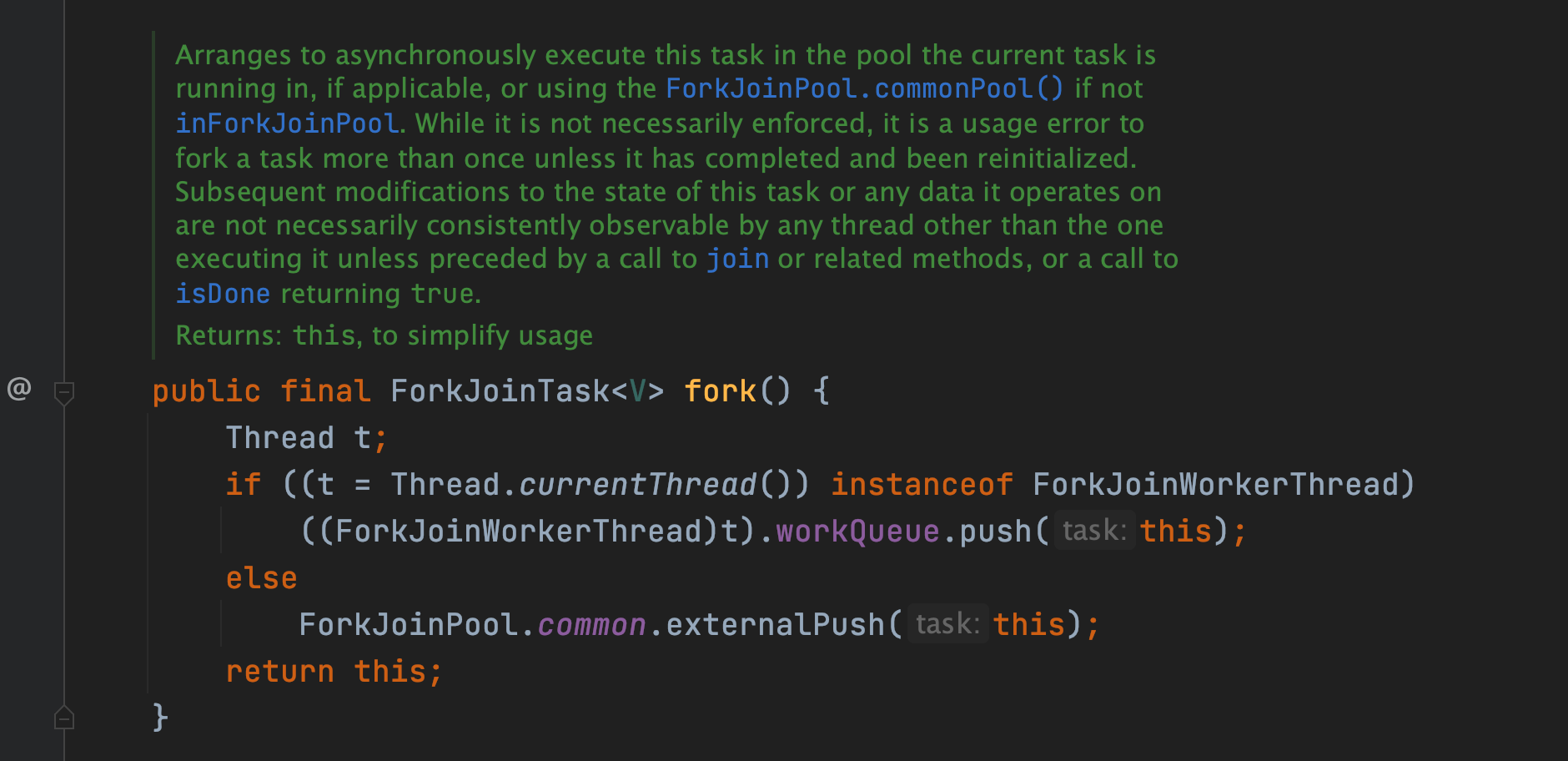
方法对于 ForkJoinWorkerThread 类型的线程,首先会调用 ForkJoinWorkerThread 的 workQueue 的 push() 方法异步的去执行这个任务,然后马上返回结果。继续跟进 ForkJoinPool 的 push() 方法,源码如下:
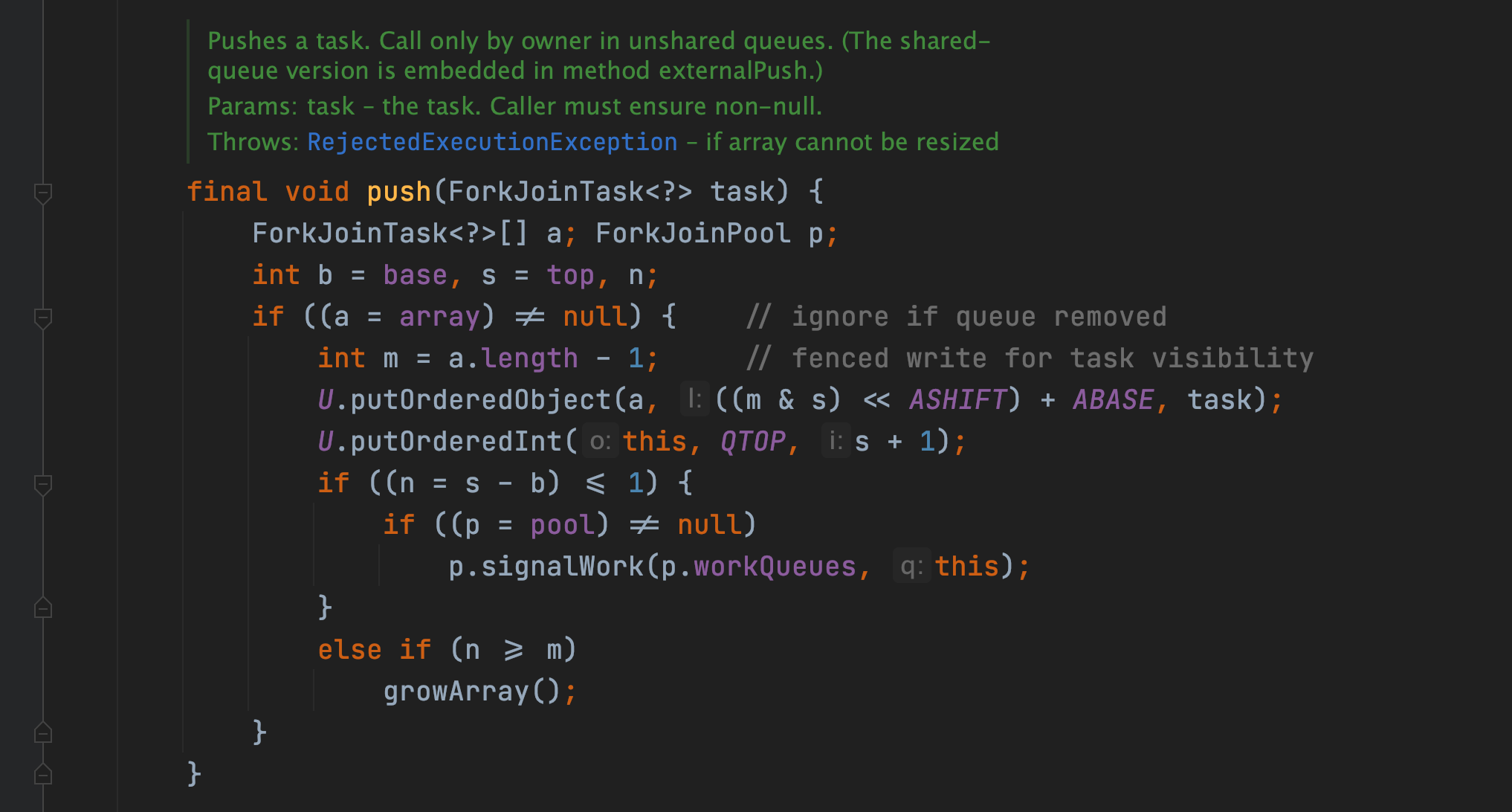
方法将当前任务添加到 ForkJoinTask 任务队列数组中,然后再调用 ForkJoinPool 的 signalWork 方法创建或者唤醒一个工作线程来执行该任务。然后再来看看 ForkJoinTask 的 join() 方法,方法源码如下:


方法首先调用了 doJoin() 方法,该方法返回当前任务的状态,根据返回的任务状态做不同的处理:
- 已完成状态则直接返回结果
- 被取消状态则直接抛出异常(CancellationException)
- 发生异常状态则直接抛出对应的异常
继续跟进 doJoin() 方法,方法源码如下:
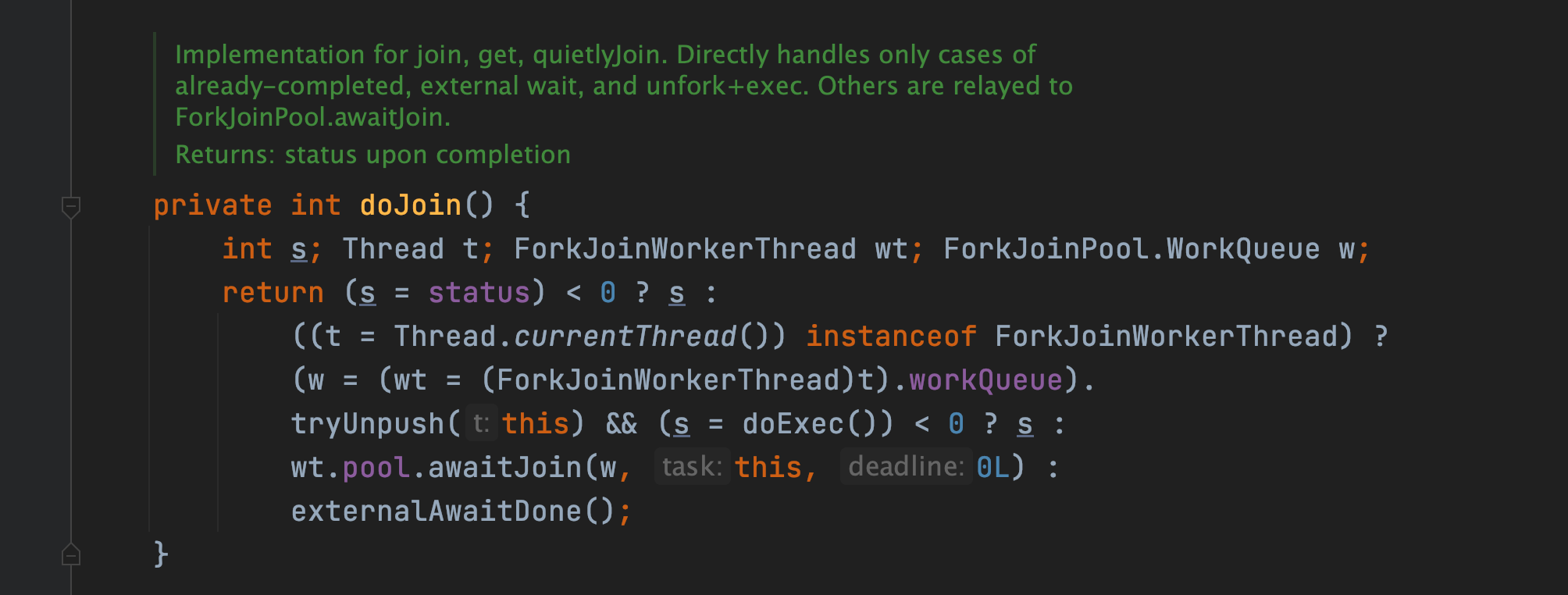
方法首先判断当前任务状态是否已经执行完成,如果执行完成则直接返回任务状态。如果没有执行完成,则从任务数组中(workQueue)取出任务并执行,任务执行完成则设置任务状态为 NORMAL,如果出现异常则记录异常并设置任务状态为 EXCEPTIONAL(在 doExec() 方法中)。
总结
本文主要介绍了 Java 并发框架中的 Fork/Join 框架的基本原理和其使用的工作窃取算法(work-stealing)、设计方式和部分实现源码。Fork/Join 框架在 JDK 的官方标准库中也有应用。比如 JDK 1.8+ 标准库提供的 Arrays.parallelSort(array) 可以进行并行排序,它的原理就是内部通过 Fork/Join 框架对大数组分拆进行并行排序,可以提高排序的速度,还有集合中的 Collection.parallelStream() 方法底层也是基于 Fork/Join 框架实现的,最后就是定义小任务的阈值往往是需要通过测试验证才能合理给出,并且保证程序可以达到最好的性能。
Java 并发之 Fork/Join 框架的更多相关文章
- Java 并发编程 -- Fork/Join 框架
概述 Fork/Join 框架是 Java7 提供的一个用于并行执行任务的框架,是一个把大任务分割成若干个小任务,最终汇总每个小任务结果后得到大任务结果的框架.下图是网上流传的 Fork Join 的 ...
- java 中的fork join框架
文章目录 ForkJoinPool ForkJoinWorkerThread ForkJoinTask 在ForkJoinPool中提交Task java 中的fork join框架 fork joi ...
- JAVA中的Fork/Join框架
看了下Java Tutorials中的fork/join章节,整理下. 什么是fork/join框架 fork/join框架是ExecutorService接口的一个实现,可以帮助开发人员充分利用多核 ...
- Java并发编程--Fork/Join框架使用
上篇博客我们介绍了通过CyclicBarrier使线程同步,可是上述方法存在一个问题,那就是假设一个大任务跑了2个线程去完毕.假设线程2耗时比线程1多2倍.线程1完毕后必须等待线程2完毕.等待的过程线 ...
- JAVA 1.7并发之Fork/Join框架
在之前的博文里有说过executor框架,其实Fork/Join就是继承executor的升级版啦 executor用于创建一个线程池,但是需要手动的添加任务,如果需要将大型任务分治,显然比较麻烦 而 ...
- Java并发——Fork/Join框架
为了防止无良网站的爬虫抓取文章,特此标识,转载请注明文章出处.LaplaceDemon/ShiJiaqi. http://www.cnblogs.com/shijiaqi1066/p/4631466. ...
- Java 7 Fork/Join 框架
在 Java7引入的诸多新特性中,Fork/Join 框架无疑是重要的一项.JSR166旨在标准化一个实质上可扩展的框架,以将并行计算的通用工具类组织成一个类似java.util中Collection ...
- 《java.util.concurrent 包源码阅读》22 Fork/Join框架的初体验
JDK7引入了Fork/Join框架,所谓Fork/Join框架,个人解释:Fork分解任务成独立的子任务,用多线程去执行这些子任务,Join合并子任务的结果.这样就能使用多线程的方式来执行一个任务. ...
- Java Fork/Join 框架
简介 从JDK1.7开始,Java提供Fork/Join框架用于并行执行任务,它的思想就是讲一个大任务分割成若干小任务,最终汇总每个小任务的结果得到这个大任务的结果. 这种思想和MapReduce很像 ...
随机推荐
- VB 老旧版本维护系列---有点懵逼的webserver访问
有点懵逼的webserver访问 '定义webserver地址 Dim postUrl As String = "" '定义webserver所需xml字符串参数 Dim xmlR ...
- JVM 内存溢出 实战 (史上最全)
文章很长,建议收藏起来,慢慢读! 疯狂创客圈为小伙伴奉上以下珍贵的学习资源: 疯狂创客圈 经典图书 : <Netty Zookeeper Redis 高并发实战> 面试必备 + 大厂必备 ...
- SpringBoot 结合 Spring Cache 操作 Redis 实现数据缓存
系统环境: Redis 版本:5.0.7 SpringBoot 版本:2.2.2.RELEASE 参考地址: Redus 官方网址:https://redis.io/ 博文示例项目 Github 地址 ...
- 入门实践丨如何在K3s上部署Web应用程序
在本文中,我们将使用Flask和JavaScript编写的.带有MongoDB数据库的TODO应用程序,并学习如何将其部署到Kubernetes上.这篇文章是针对初学者的,如果你之前没有深度接触过Ku ...
- 『心善渊』Selenium3.0基础 — 8、使用CSS选择器定位元素
目录 1.CSS选择器介绍 2.CSS选择器定位语法 3.Selenium中使用CSS选择器定位元素 (1)通过属性定位元素 (2)通过标签定位元素 (3)通过层级关系定位元素 (4)通过索引定位元素 ...
- 使用pdb进行Python调试
调试应用有时是一个不受欢迎的工作,当你长期编码之后,只希望写的代码顺利运行.但是,很多情况下,我们需要学习一个新的语言功能或者实验检测新的方法,从而去理解其中运行的机制原理. 即使不考虑这样的场景,调 ...
- SpringCloud-OAuth2(四):改造篇
本片主要讲SpringCloud Oauth2篇的实战改造,如动态权限.集成JWT.更改默认url.数据库加载client信息等改造. 同时,这应该也是我这系列博客的完结篇. 关于Oauth2,我也想 ...
- testt
一级标题 二级标题 三级标题 四级标题 l 1
- 关于React Native常用技巧
Doctor命令检查所需环境 @2019年11月18日,React Native v新增了一个环境检查和诊断命令行,可以帮助新手修复环境,输出环境依赖报告. 先建好的一个React Native项目, ...
- 痞子衡嵌入式:在串口波特率识别实例里逐步展示i.MXRT上提升代码执行性能的十八般武艺
大家好,我是痞子衡,是正经搞技术的痞子.今天痞子衡给大家介绍的是在串口波特率识别实例里逐步展示i.MXRT上提升代码执行性能的十八般武艺. 恩智浦 MCU SE 团队近期一直在加班加点赶 SBL 项目 ...