深度强化学习中稀疏奖励问题Sparse Reward
Sparse Reward
推荐资料
强化学习算法在被引入深度神经网络后,对大量样本的需求更加明显。如果智能体在与环境的交互过程中没有获得奖励,那么该样本在基于值函数和基于策略梯度的损失中的贡献会很小。
针对解决稀疏奖励问题的研究主要包括:1
Reward Shaping:奖励设计与学习
经验回放机制
探索与利用
多目标学习和辅助任务
1. Reward Shaping
人为设计的 “密集”奖励。
例如,在机械臂“开门”的任务中,原始的稀疏奖励设定为:若机械臂把门打开,则给予“+1”奖励,其余情况下均给予“0”奖励。然而,由于任务的复杂性,机械臂从随机策略开始,很难通过自身探索获得奖励。为了简化训练过程,可以使用人为设计的奖励:1)在机械臂未碰到门把手时,将机械臂与门把手距离的倒数作为奖励;2)当机械臂接触门把手时,给予“+0.1”奖励;3)当机械臂转动门把手时,给予“+0.5”奖励;4)当机械臂完成开门时,给予“+1”奖励。这样,通过人为设计的密集奖励,可以引导机械臂完成开门的操作,简化训练过程。
2. 逆向强化学习
针对人为设计奖励中存在的问题,Ng等2提出了从最优交互序列中学习奖励函数的思路,此类方法称为”逆强化学习”。
3. 探索与利用(好奇法):
在序列决策中,智能体可能需要牺牲当前利益来选择非最优动作,期望能够获得更大的长期回报。
在 DRL领域中使用的探索与利用方法主要包括两类:基于计数的方法和基于内在激励的方法。其目的是构造虚拟奖励,用于和真实奖励函数共同学习。由于真实的奖励是稀疏的,使用虚拟奖励可以加快学习的进程。
ICM3(逆环境模型)—— 改进的基于内在激励的方法
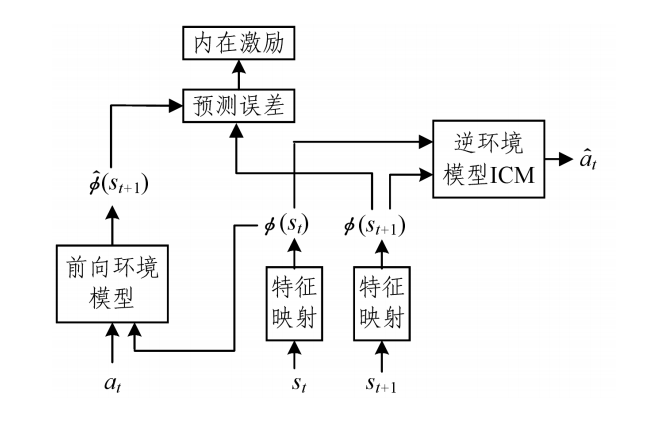
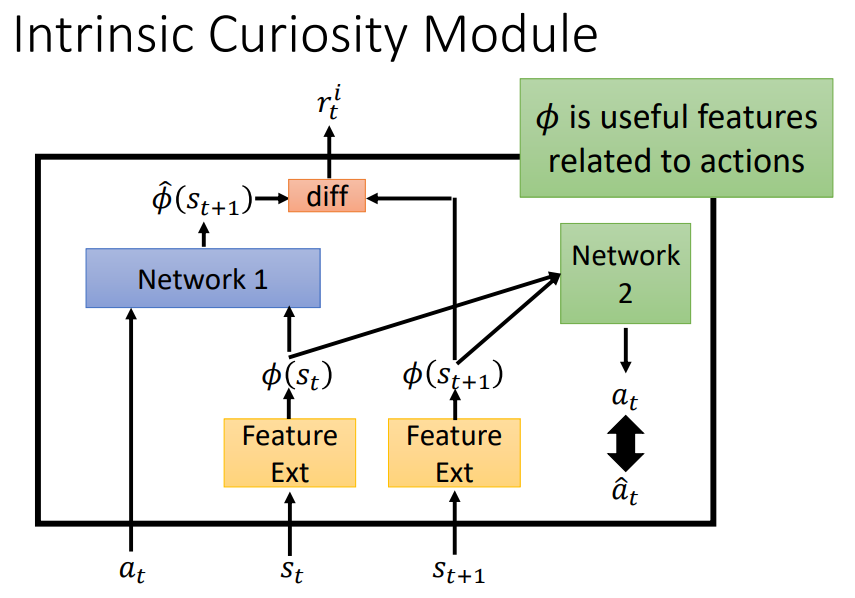
- Network 1:预测的状态S与实际状态S差别越大,回报r越大,鼓励冒险
- Network 2:输入 \(S_t\) 和 \(S_{t+1}\) ,预测动作 \(a_t\) ,与真实动作差别大时,表示无关紧要的状态。
- ICM 通过学习可以在特征空间中去除与预测动作无关的状态特征,在特征空间中构建环境模型可以去除环境噪声。
4. 多目标学习——层次强化学习
- 智能体可以从已经到达的位置来获得奖励。在训练中使用虚拟目标替代原始目标,使智能体即使在训练初期也能很快获得奖励,极大地加速了学习过程。
- 将一个单一目标,拆解为多个阶段的多层级的目标。
5. 辅助任务
在稀疏奖励情况下,当原始任务难以完成时,往往可以通过设置辅助任务的方法加速学习和训练。
Curriculum Learning,“课程式”强化学习:
当完成原始任务较为困难时,奖励的获取是困难的。此时,智能体可以先从简单的、相关的任务开始学习,然后不断增加任务的难度,逐步学习更加复杂的任务。
- 直接添加辅助任务:第二类方法是直接在原任务的基础上添加并行的辅助任 务,原任务和辅助任务共同学习。
参考文献
深度强化学习中稀疏奖励问题Sparse Reward的更多相关文章
- (转) 深度强化学习综述:从AlphaGo背后的力量到学习资源分享(附论文)
本文转自:http://mp.weixin.qq.com/s/aAHbybdbs_GtY8OyU6h5WA 专题 | 深度强化学习综述:从AlphaGo背后的力量到学习资源分享(附论文) 原创 201 ...
- 5G网络的深度强化学习:联合波束成形,功率控制和干扰协调
摘要:第五代无线通信(5G)支持大幅增加流量和数据速率,并提高语音呼叫的可靠性.在5G无线网络中共同优化波束成形,功率控制和干扰协调以增强最终用户的通信性能是一项重大挑战.在本文中,我们制定波束形成, ...
- 【资料总结】| Deep Reinforcement Learning 深度强化学习
在机器学习中,我们经常会分类为有监督学习和无监督学习,但是尝尝会忽略一个重要的分支,强化学习.有监督学习和无监督学习非常好去区分,学习的目标,有无标签等都是区分标准.如果说监督学习的目标是预测,那么强 ...
- 一文读懂 深度强化学习算法 A3C (Actor-Critic Algorithm)
一文读懂 深度强化学习算法 A3C (Actor-Critic Algorithm) 2017-12-25 16:29:19 对于 A3C 算法感觉自己总是一知半解,现将其梳理一下,记录在此,也 ...
- 深度强化学习资料(视频+PPT+PDF下载)
https://blog.csdn.net/Mbx8X9u/article/details/80780459 课程主页:http://rll.berkeley.edu/deeprlcourse/ 所有 ...
- 深度强化学习day01初探强化学习
深度强化学习 基本概念 强化学习 强化学习(Reinforcement Learning)是机器学习的一个重要的分支,主要用来解决连续决策的问题.强化学习可以在复杂的.不确定的环境中学习如何实现我们设 ...
- 深度强化学习(DQN-Deep Q Network)之应用-Flappy Bird
深度强化学习(DQN-Deep Q Network)之应用-Flappy Bird 本文系作者原创,转载请注明出处:https://www.cnblogs.com/further-further-fu ...
- 深度强化学习(Deep Reinforcement Learning)入门:RL base & DQN-DDPG-A3C introduction
转自https://zhuanlan.zhihu.com/p/25239682 过去的一段时间在深度强化学习领域投入了不少精力,工作中也在应用DRL解决业务问题.子曰:温故而知新,在进一步深入研究和应 ...
- 深度强化学习(DRL)专栏(一)
目录: 1. 引言 专栏知识结构 从AlphaGo看深度强化学习 2. 强化学习基础知识 强化学习问题 马尔科夫决策过程 最优价值函数和贝尔曼方程 3. 有模型的强化学习方法 价值迭代 策略迭代 4. ...
随机推荐
- 【题解】codeforces 467C George and Job dp
题目描述 新款手机 iTone6 近期上市,George 很想买一只.不幸地,George 没有足够的钱,所以 George 打算当一名程序猿去打工.现在George遇到了一个问题. 给出一组有 n ...
- 无需会员将有道云笔记脑图转换xmind
我的烦恼 有道云笔记有脑图功能,我平时经常用到,之所以很少用到其他脑图工具,是因为我一直用有道云笔记写笔记.因此编辑脑图和查看脑图比较方便,但是需要将脑图导出的时候目前只支持图片和xmind,但是需要 ...
- Linux中测试网络命令
ping IP -t 是持续性查看网络状态
- DBA入门相关知识介绍
DBA(database administrator):数据库管理员 DBMS(database management system):数据库管理系 ...
- 《电容应用分析精粹:从充放电到高速PCB设计》最新勘误表
最新勘误表百度云盘下载 链接: https://pan.baidu.com/s/18yqwnJrCu9oWvFcPiwRWvA 提取码: x3e3 (本勘误表仅包含错误相关部分,不包含对语句的 ...
- 温故知新,.Net Core遇见Postman(API Development),进阶分布式微服务高效调式
什么是Postman 环境变量(Environments) 全局协议 描述 变量 初始值 当前值 请求协议 request_protocol http http 授权信息 描述 变量 初始值 当前值 ...
- 9.4、安装zabbix(1)
1.什么是zabbix: zabbix是一个基于WEB界面的提供分布式系统监视以及网络监视功能的企业级的开源解决方案: zabbix能监视各种网络参数,保证服务器系统的安全运营:并提供灵活的通知机制以 ...
- UVA 10689 Yet another Number Sequence 矩阵快速幂 水呀水
#include <iostream> #include <cstdio> #include <cstring> #include <algorithm> ...
- 自然语言处理(NLP)——简介
自然语言处理(NLP Natural Language Processing)是一种专业分析人类语言的人工智能.就是在机器语⾔和⼈类语言之间沟通的桥梁,以实现人机交流的目的. 在人工智能出现之前,机器 ...
- Linux Netfilter框架分析
目录 Netfilter框架 Netfilter的5个hook点 netfilter协议栈数据流分析 连接跟踪conntrack conntrack连接跟踪表条目 连接跟踪表大小 管理连接跟踪表 ip ...