Python爬虫-scrapyd
1、什么是scrapyd
Scrapyd是一个服务,用来运行scrapy爬虫的。
它允许你部署你的scrapy项目以及通过HTTP JSON的方式控制你的爬虫。
官方文档:http://scrapyd.readthedocs.org/
2、安装scrapyd和scrapyd-client
pip install scrapyd(服务器)
pip install scrapyd-client(客户端)
安装完成后,在python安装目录的Scripts的文件下有一个scrapyd.exe,在命令行窗口执行后,可以通过访问http://127.0.0.1:6800,进入
一个很简单的页面,
执行scrapyd这个命令行,表示服务开启了,

在浏览器中访问这个服务,
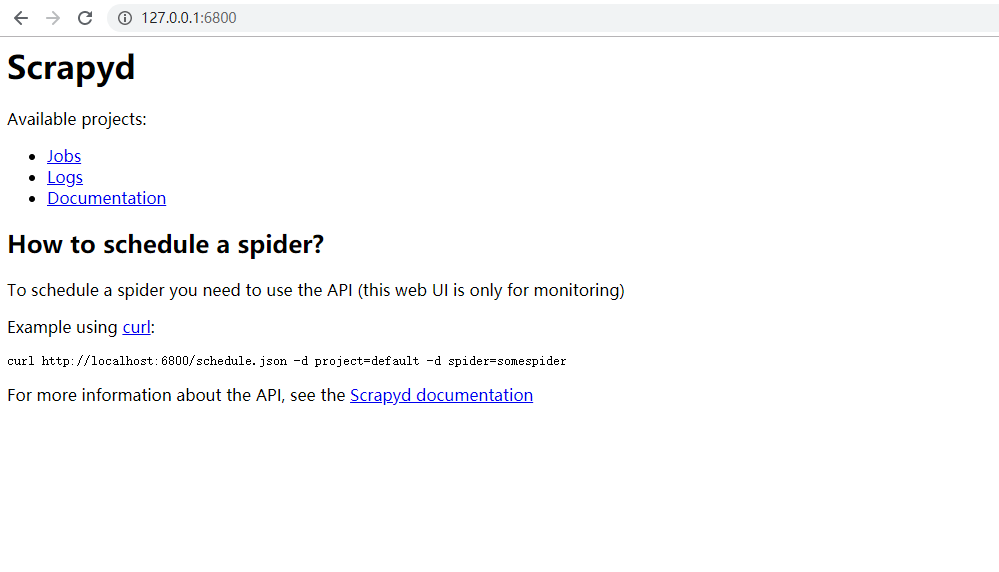
上面表示服务端安装成功,现在来安装测试客户端,安装好后,执行scrapyd-deploy来测试是否安装成功,

执行失败,我们来看一下Python的Scripts下面是否有一个scrapyd-client.exe命令,
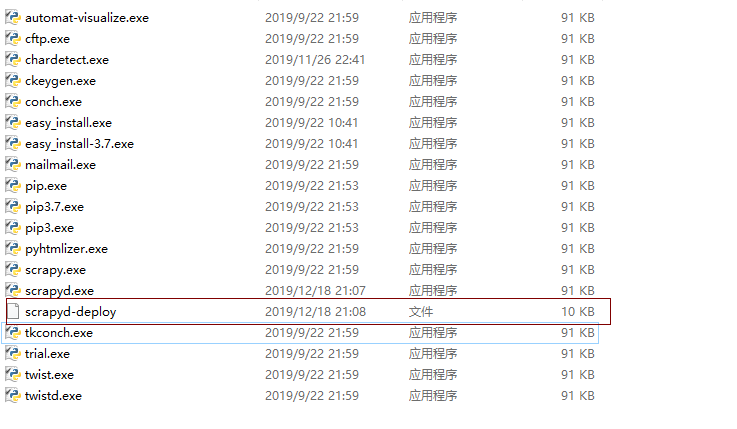
从图片中看到里面有一个scrapyd-deploy文件,但不是可执行文件,打开后发现这个文件是一个包含Python代码的文件,所以要是让它
执行,要不用Python解释器来执行这个文件,要不就是把它编译为可执行文件两种方式。
第一种方式:
在这个文件夹里创建scrapyd-deploy.bat文件,并在里面输入:
@echo off
C:\Users\\AppData\Local\Programs\Python\Python37-\python.exe C:\Users\\AppData\Local\Programs\Python\Python37-\Scripts\scrapyd-deploy %*
第二行第一个路径是python解释器的绝对路径,第二路径是scrapyd-deploy文件的绝对路径,然后再来执行scrapyd-deploy命令

这样就表明安装成功了
第二种方式:
用可以将python源文件编译为scrapyd-deploy.exe可执行程序的模块pyinstaller
3、上传爬虫项目
在上传之前必须修改一下配置文件,将scrapy.cfg中的url注释掉
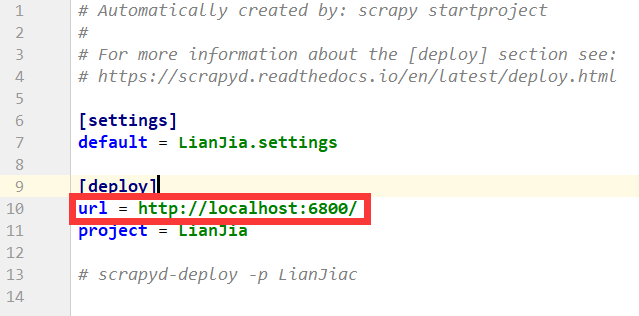
注释掉后,就可以开始正式上传了,上传时必须要在爬虫项目文件中,
执行scrapyd-deploy -p <projectname>,并出现下图中“status”:“ok”,表示上传成功,可以在http://127.0.0.1:6800页面验证

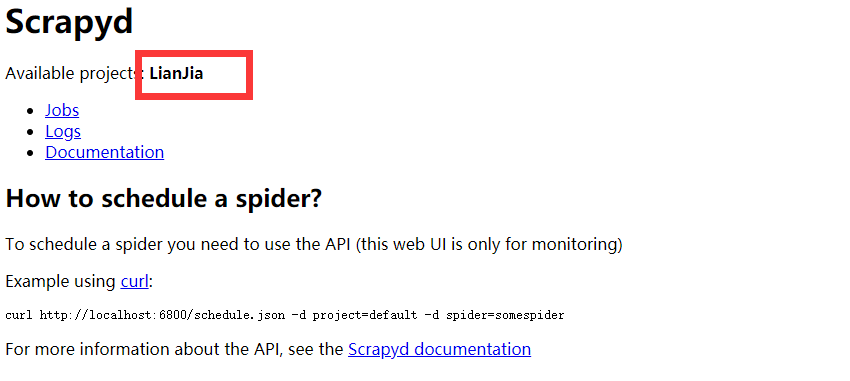
4、运行爬虫项目
上传过后就可以在命令行窗口开始启动爬虫了
启动命令:curl http://127.0.0.1:6800/schedule.json -d project=<projectname> -d spider=<spidername>
启动后,就可以看到在开启服务的那个命令行窗口不断出现scrapy项目运行时的数据,在http://127.0.0.1:6800/jobs页面显示
爬虫运行信息,在http://127.0.0.1:6800/logs/页面显示运行日志
5、关闭爬虫项目
关闭命令:curl http://127.0.0.1:6800/cancel.json -d project=<projectname> -d job=<jobid>
6、其它命令:
daemonstatus.json #查看爬虫状态
addversion.json #添加版本号
listprojects.json #列出所有已经上传到服务器的爬虫工程名
listversions.json #列出指定工程的版本号
listspiders.json #列出指定工程的爬虫名
listjobs.json #列出指定工程的所有正在上传的,正在运行的,和已经完成的 jobid
delversion.json #删除指定工程的某个版本
delproject.json #删除工程
Python爬虫-scrapyd的更多相关文章
- 初识python爬虫框架Scrapy
Scrapy,按照其官网(https://scrapy.org/)上的解释:一个开源和协作式的框架,用快速.简单.可扩展的方式从网站提取所需的数据. 我们一开始上手爬虫的时候,接触的是urllib.r ...
- 一个Python爬虫工程师学习养成记
大数据的时代,网络爬虫已经成为了获取数据的一个重要手段. 但要学习好爬虫并没有那么简单.首先知识点和方向实在是太多了,它关系到了计算机网络.编程基础.前端开发.后端开发.App 开发与逆向.网络安全. ...
- Python 爬虫模拟登陆知乎
在之前写过一篇使用python爬虫爬取电影天堂资源的博客,重点是如何解析页面和提高爬虫的效率.由于电影天堂上的资源获取权限是所有人都一样的,所以不需要进行登录验证操作,写完那篇文章后又花了些时间研究了 ...
- python爬虫成长之路(一):抓取证券之星的股票数据
获取数据是数据分析中必不可少的一部分,而网络爬虫是是获取数据的一个重要渠道之一.鉴于此,我拾起了Python这把利器,开启了网络爬虫之路. 本篇使用的版本为python3.5,意在抓取证券之星上当天所 ...
- python爬虫学习(7) —— 爬取你的AC代码
上一篇文章中,我们介绍了python爬虫利器--requests,并且拿HDU做了小测试. 这篇文章,我们来爬取一下自己AC的代码. 1 确定ac代码对应的页面 如下图所示,我们一般情况可以通过该顺序 ...
- python爬虫学习(6) —— 神器 Requests
Requests 是使用 Apache2 Licensed 许可证的 HTTP 库.用 Python 编写,真正的为人类着想. Python 标准库中的 urllib2 模块提供了你所需要的大多数 H ...
- 批量下载小说网站上的小说(python爬虫)
随便说点什么 因为在学python,所有自然而然的就掉进了爬虫这个坑里,好吧,主要是因为我觉得爬虫比较酷,才入坑的. 想想看,你可以批量自动的采集互联网上海量的资料数据,是多么令人激动啊! 所以我就被 ...
- python 爬虫(二)
python 爬虫 Advanced HTML Parsing 1. 通过属性查找标签:基本上在每一个网站上都有stylesheets,针对于不同的标签会有不同的css类于之向对应在我们看到的标签可能 ...
- Python 爬虫1——爬虫简述
Python除了可以用来开发Python Web之后,其实还可以用来编写一些爬虫小工具,可能还有人不知道什么是爬虫的. 一.爬虫的定义: 爬虫——网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区 ...
随机推荐
- LeetCode No.157,158,159
No.157 Read 用 Read4 读取 N 个字符 题目 给你一个文件,并且该文件只能通过给定的 read4 方法来读取,请实现一个方法使其能够读取 n 个字符. read4 方法: API r ...
- UIView的setNeedsLayout, layoutIfNeeded 和 layoutSubviews 方法之间的关系解释(转)
layoutSubviews总结 ios layout机制相关方法 - (CGSize)sizeThatFits:(CGSize)size- (void)sizeToFit——————- - (voi ...
- Golang结构体值的交换
Golang结构体值的交换 一.添加结构体,多if暴力 最先遇到这个问题是在比编写PUT方法的接口时遇到. (我公司编写http put方法,是先解析json至StudentInput结构体中,通过i ...
- springboot集成websocket实现大文件分块上传
遇到一个上传文件的问题,老大说使用http太慢了,因为http包含大量的请求头,刚好项目本身又集成了websocket,想着就用websocket来做文件上传. 相关技术 springboot web ...
- 9.数据分组 group by
--数据分组 group by --作用:用于 对查询的数据进行分组,并处理 select deptno,job from emp group by deptno,job --1.分组之后,不能将除分 ...
- 吴裕雄--天生自然C语言开发:约瑟夫生者死者小游戏
个人在一条船上,超载,需要 人下船. 于是人们排成一队,排队的位置即为他们的编号. 报数,从 开始,数到 的人下船. 如此循环,直到船上仅剩 人为止,问都有哪些编号的人下船了呢? #include&l ...
- day40-进程-生产者消费者模型进阶
#1.队列的数据是安全的,因为队列内置了一把锁,大家都来抢占资源的时候,A在操作数据的时候,B就无法操作该数据. # 下面代码有两个生产者和三个消费者,包子吃完之后,接着放的两个None被marry和 ...
- mysql之左连接、右连接、内连接、全连接、等值连接、交叉连接等
mysql中的各种jion的记录,以备用时查 1.等值连接和内连接, a.内连接与等值连接效果是相同的,执行效率也相同,只是书写方式不一样,内连接是由SQL 1999规则定的书写方式 比如: sele ...
- 2019ICPC南京网络赛B super_log(a的b塔次方)
https://nanti.jisuanke.com/t/41299 分析:题目给出a,b,mod求满足条件的最小a,由题目的式子得,每次只要能递归下去,b就会+1,所以就可以认为b其实是次数,什么的 ...
- SpringBoot常见面试题
什么是SpringBootSpringBoot的作用SpringBoot的优点SpringBoot的核心配置文件是什么,有何区别?SpringBoot的配置文件有几种格式,区别是什么?SpringBo ...