[Python3]为什么map比for循环快
实验结论
- 如果需要在循环结束后获得结果,推荐列表解析;
- 如果不需要结果,直接使用for循环, 列表解析可以备选;
- 除了追求代码优雅和特定规定情境,不建议使用map
如果不需要返回结果
这里有三个process, 每个任务将通过增加循环提高时间复杂度
def process1(val, type=None):
chr(val % 123)
def process2(val, type):
if type == "list":
[process1(_) for _ in range(val)]
elif type == "for":
for _ in range(val):
process1(_)
elif type == "map":
list(map(lambda _: process1(_), range(val)))
def process3(val, type):
if type == "list":
[process2(_, type) for _ in range(val)]
elif type == "for":
for _ in range(val):
process2(_, type)
elif type == "map":
list(map(lambda _: process2(_, type), range(val)))
然后通过三种循环方式,去依次执行三种任务
def list_comp():
[process1(i, "list") for i in range(length)]
# [process2(i, "list") for i in range(length)]
# [process3(i, "list") for i in range(length)]
def for_loop():
for i in range(length):
process1(i, "for")
# process2(i, "for")
# process3(i, "for")
def map_exp():
list(map(lambda v: process1(v, "map"), range(length)))
# list(map(lambda v: process2(v, "map"), range(length)))
# list(map(lambda v: process3(v, "map"), range(length)))
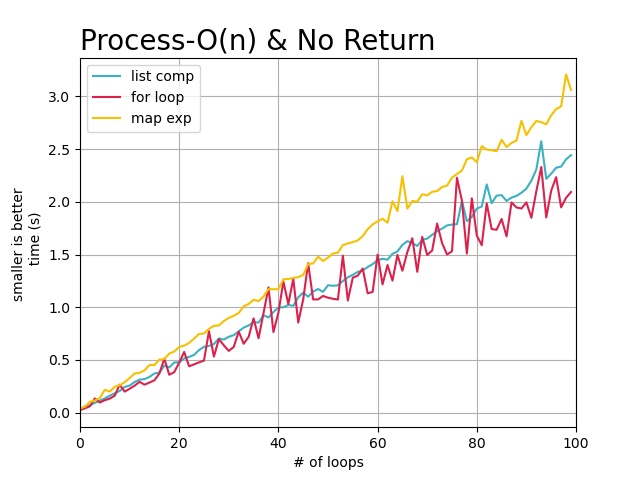


从上述的图像中,可以直观的看到, 随着任务复杂度的提高以及数据量的增大,每个循环完成需要的时间也在增加,
但是map方式花费的时间明显比其他两种要更多。 所以在不需要返回处理结果时,选择标准for或者列表解析都可以。
因为标准for循环和列表解析方式在循环任务复杂度逐渐提高的情况下,处理时间基本没有差异。
需要返回结果
这里有三个task, 每个任务将通过增加循环提高时间复杂度
def task1(val, type=None):
return chr(val % 123)
def task2(val, type):
if type == "list":
return [task1(_) for _ in range(val)]
elif type == "for":
res = list()
for _ in range(val):
res.append(task1(_))
return res
elif type == "map":
return list(map(lambda _: task1(_), range(val)))
def task3(val, type):
if type == "list":
return [task2(_, type) for _ in range(val)]
elif type == "for":
res = list()
for _ in range(val):
res.append(task2(_, type))
return res
elif type == "map":
return list(map(lambda _: task2(_, type), range(val)))
然后通过三种循环方式,去依次执行三种任务
def list_comp():
# return [task1(i, "list") for i in range(length)]
return [task2(i, "list") for i in range(length)]
# return [task3(i, "list") for i in range(length)]
def for_loop():
res = list()
for i in range(length):
# res.append(task1(i, "for"))
res.append(task2(i, "for"))
# res.append(task3(i, "for"))
return res
def map_exp():
# return list(map(lambda v: task1(v, "map"), range(length)))
return list(map(lambda v: task2(v, "map"), range(length)))
# return list(map(lambda v: task3(v, "map"), range(length)))
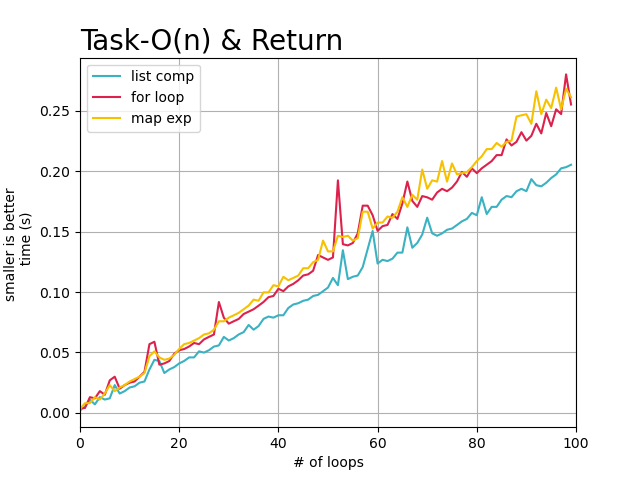

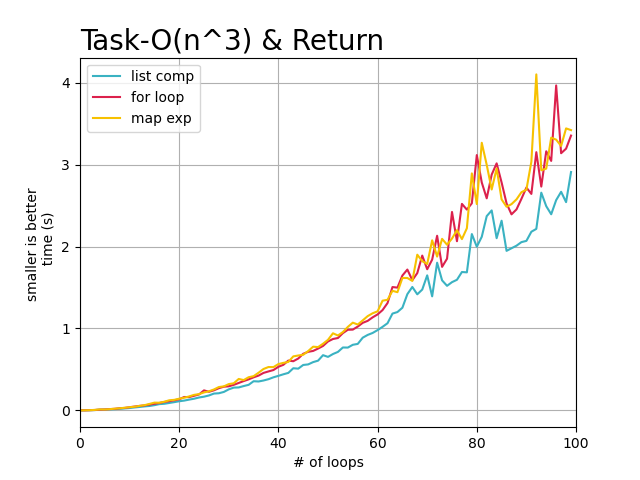
从上述的图像中,可以直观的看到, 随着任务复杂度的提高以及数据量的增大,每个循环完成需要的时间也在增加,
但是明显看出, 使用list_comp列表解析在, 循环需要返回处理结果的每次任务中都表现的很好,基本快于其他两种迭代方式。
而标准for循环和map方式在循环任务复杂度逐渐提高的情况下,处理时间基本没有差异。
为什么普遍认为map比for快?
我认为可能跟处理的数据量有关系,大部分场景下,使用者只测试了少量的数据(100W以下,比如这篇文章,就是数据量比较少,导致速度的区别不明显),在少量的数据集下,我们确实看到了map方式比for循环快,甚至有时候比列表解析还稍微快一点,但是当我们逐渐把数据量增加原来的100倍,这时候差距的凸现出来了。
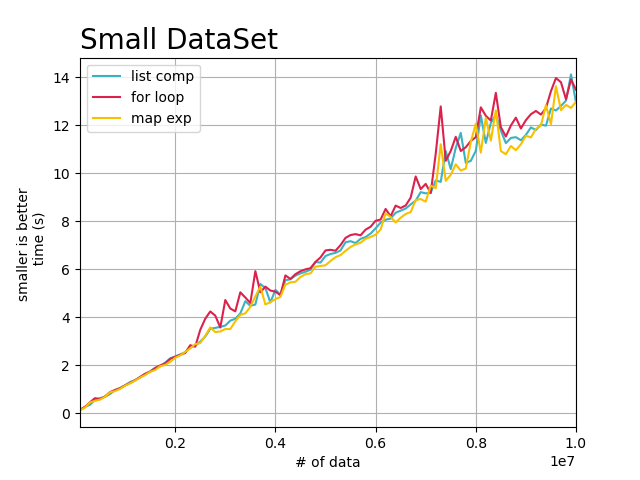
如上图,在小数据集上(100W-1KW之间), 三者消耗的时间差不多相等,但是用map方式遍历和处理,还是有一定的加速优势。
具体实验代码可以通过Github获得
[Python3]为什么map比for循环快的更多相关文章
- Map<String, String>循环遍历的方法
Map<String, String>循环遍历的方法 Map<String, String>循环遍历的方法 Map<String, String>循环遍历的方法 下 ...
- Python3 字典(map)
ayout: post title: Python3 字典(map) author: "luowentaoaa" catalog: true tags: mathjax: true ...
- Python2与Python3的map()
1. map()函数 Python2中,map(func, seq1[,seq2[...[,seqn)将func作用于seq*的每个序列的索引相同的元素,并最终生成一个[func(seq1[0], s ...
- forkjoin及其性能分析,是否比for循环快?
最近看了网上的某公开课,其中有讲到forkjoin框架.在这之前,我丝毫没听说过这个东西,很好奇是什么东东.于是,就顺道研究了一番. 总感觉这个东西,用的地方很少,也有可能是我才疏学浅.好吧,反正问了 ...
- 解决Python3下map函数的显示问题
今天小编就为大家分享一篇解决Python3下map函数的显示问题,具有很好的参考价值,希望对大家有所帮助.一起跟随小编过来看看吧map函数是Python里面比较重要的函数,设计灵感来自于函数式编程.P ...
- Python3下map函数的显示问题
map函数是Python里面比较重要的函数,设计灵感来自于函数式编程.Python官方文档中是这样解释map函数的: map(function, iterable, ...) Return an it ...
- java中对map使用entrySet循环
根据JDK5的新特性,用For循环Map,例如循环Map的Key 1 2 3 for(String dataKey : paraMap.keySet()) { System.out.p ...
- python3学习笔记十(循环语句)
参考http://www.runoob.com/python3/python3-loop.html 循环语句 while循环 # !/usr/bin/env python3 n = 100 sum = ...
- map和list循环遍历
//map遍历(zmm是实体类) Map<String, zmm> maps = new HashMap<String, zmm>(); //给map存值: maps.put( ...
随机推荐
- 整理高度塌陷与BFC
当面试官问道你高度塌陷时,人们第一想到的方法一定是 .clearfix::after { content: ''; display: block; clear: both; visibility: h ...
- Xenia and Colorful Gems(二分--思维)
给定三个数组a,b,c. 要求从每个数字取一个数,使得两两之差和最小. 求出这个数. \(我又懵逼了.我是会O(n^3)的暴力啊,怎么办.\) \(\color{Red}{从结果看,选出来的三个数必定 ...
- 吴恩达机器学习week2
1.Mean normalization(均值归一化) 我们可以将均值归一化理解为特征缩放的另一种方法. 特征缩放和均值归一化的作用都是为了减小样本数据的波动使得梯度下降能够更快速的寻找到一条'捷径' ...
- ssh暴力破解解决方案(Centos7更改端口)
服务器默认ssh远程连接端口为22端口,通常通过22远程连接的话,容易有ssh暴力破解的风险,给我们造成一定的损失.下面是更换ssh端口过程: 1.添加ssh端口 vim /etc/ssh/sshd_ ...
- FOC中电流环调试的宝贵经验总结(有理有据+全盘拖出)
你是否经历过一个人独自摸索前进磕磕碰碰最终体无完肤,然后将胜利的旗帜插到山顶的时刻,如果有,本文也许能帮你在调试FOC电流环的时候给你带来一些帮助和思路. 如果本文帮到了您,请帮忙点个赞
- JDBC02 加载JDBC驱动 建立连接
JDBC(Java Database Connection)为Java开发者使用数据库提供了统一的编程接口 sun公司由于不知道各个主流商用数据库的程序代码,因此无法自己写代码连接各个数据库,因此su ...
- 【HDU4990】递推式
题目大意:给定序列 1, 2, 5, 10, 21, 42, 85, 170, 341 …… 求第n项 模 m的结果 递推式 f[i] = f[i - 2] + 2 ^ (i - 1); 方法一: ...
- Windows基础学习
0x01 常用的端口 HTTP协议代理服务器常用端口号:80/8080/3128/8081/9098SOCKS代理协议服务器常用端口号:1080FTP(文件传输)协议代理服务器常用端口号:21Teln ...
- 理解css属性的继承和覆盖
首先,我们梳理一下哪些属性会被继承 文本 color 颜色,a元素除外 direction 方向 font 字体 font-family 字体系列 font-style 字体风格 font-size ...
- java -> equals方法与toString方法
equals方法 equals方法,用于比较两个对象是否相同,它其实就是使用两个对象的内存地址在比较.Object类中的equals方法内部使用的就是==比较运算符(比较内存地址). 在开发中要比较两 ...