[Python3]为什么map比for循环快
实验结论
- 如果需要在循环结束后获得结果,推荐列表解析;
- 如果不需要结果,直接使用for循环, 列表解析可以备选;
- 除了追求代码优雅和特定规定情境,不建议使用map
如果不需要返回结果
这里有三个process, 每个任务将通过增加循环提高时间复杂度
def process1(val, type=None):
chr(val % 123)
def process2(val, type):
if type == "list":
[process1(_) for _ in range(val)]
elif type == "for":
for _ in range(val):
process1(_)
elif type == "map":
list(map(lambda _: process1(_), range(val)))
def process3(val, type):
if type == "list":
[process2(_, type) for _ in range(val)]
elif type == "for":
for _ in range(val):
process2(_, type)
elif type == "map":
list(map(lambda _: process2(_, type), range(val)))
然后通过三种循环方式,去依次执行三种任务
def list_comp():
[process1(i, "list") for i in range(length)]
# [process2(i, "list") for i in range(length)]
# [process3(i, "list") for i in range(length)]
def for_loop():
for i in range(length):
process1(i, "for")
# process2(i, "for")
# process3(i, "for")
def map_exp():
list(map(lambda v: process1(v, "map"), range(length)))
# list(map(lambda v: process2(v, "map"), range(length)))
# list(map(lambda v: process3(v, "map"), range(length)))
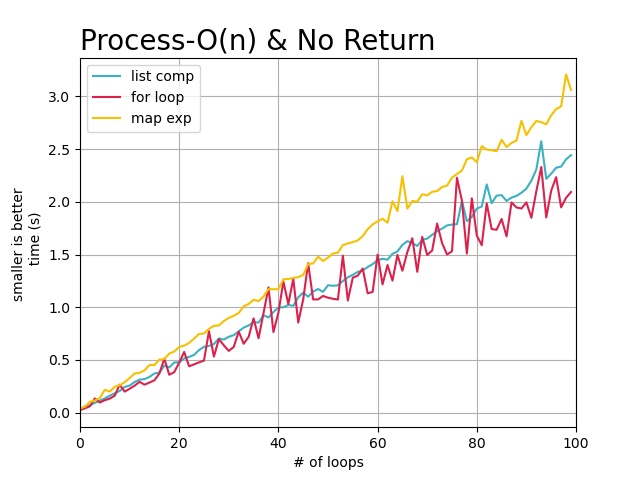


从上述的图像中,可以直观的看到, 随着任务复杂度的提高以及数据量的增大,每个循环完成需要的时间也在增加,
但是map方式花费的时间明显比其他两种要更多。 所以在不需要返回处理结果时,选择标准for或者列表解析都可以。
因为标准for循环和列表解析方式在循环任务复杂度逐渐提高的情况下,处理时间基本没有差异。
需要返回结果
这里有三个task, 每个任务将通过增加循环提高时间复杂度
def task1(val, type=None):
return chr(val % 123)
def task2(val, type):
if type == "list":
return [task1(_) for _ in range(val)]
elif type == "for":
res = list()
for _ in range(val):
res.append(task1(_))
return res
elif type == "map":
return list(map(lambda _: task1(_), range(val)))
def task3(val, type):
if type == "list":
return [task2(_, type) for _ in range(val)]
elif type == "for":
res = list()
for _ in range(val):
res.append(task2(_, type))
return res
elif type == "map":
return list(map(lambda _: task2(_, type), range(val)))
然后通过三种循环方式,去依次执行三种任务
def list_comp():
# return [task1(i, "list") for i in range(length)]
return [task2(i, "list") for i in range(length)]
# return [task3(i, "list") for i in range(length)]
def for_loop():
res = list()
for i in range(length):
# res.append(task1(i, "for"))
res.append(task2(i, "for"))
# res.append(task3(i, "for"))
return res
def map_exp():
# return list(map(lambda v: task1(v, "map"), range(length)))
return list(map(lambda v: task2(v, "map"), range(length)))
# return list(map(lambda v: task3(v, "map"), range(length)))
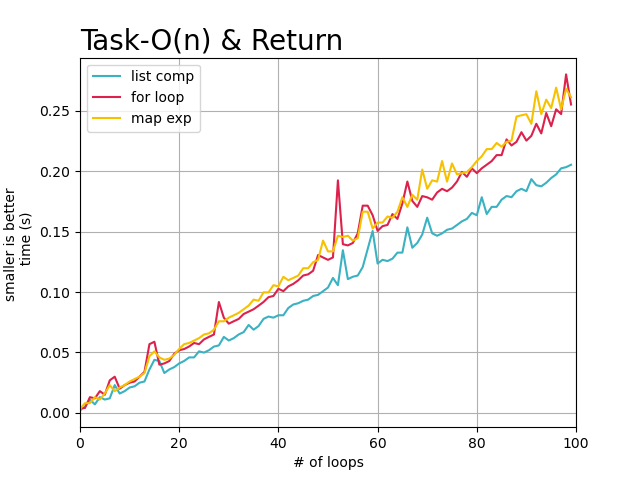

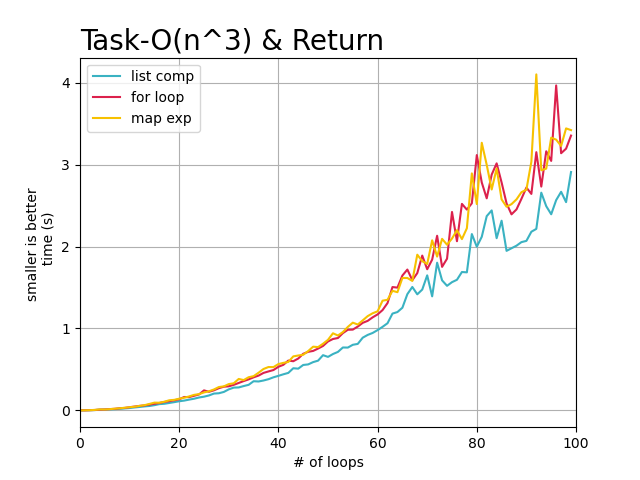
从上述的图像中,可以直观的看到, 随着任务复杂度的提高以及数据量的增大,每个循环完成需要的时间也在增加,
但是明显看出, 使用list_comp列表解析在, 循环需要返回处理结果的每次任务中都表现的很好,基本快于其他两种迭代方式。
而标准for循环和map方式在循环任务复杂度逐渐提高的情况下,处理时间基本没有差异。
为什么普遍认为map比for快?
我认为可能跟处理的数据量有关系,大部分场景下,使用者只测试了少量的数据(100W以下,比如这篇文章,就是数据量比较少,导致速度的区别不明显),在少量的数据集下,我们确实看到了map方式比for循环快,甚至有时候比列表解析还稍微快一点,但是当我们逐渐把数据量增加原来的100倍,这时候差距的凸现出来了。
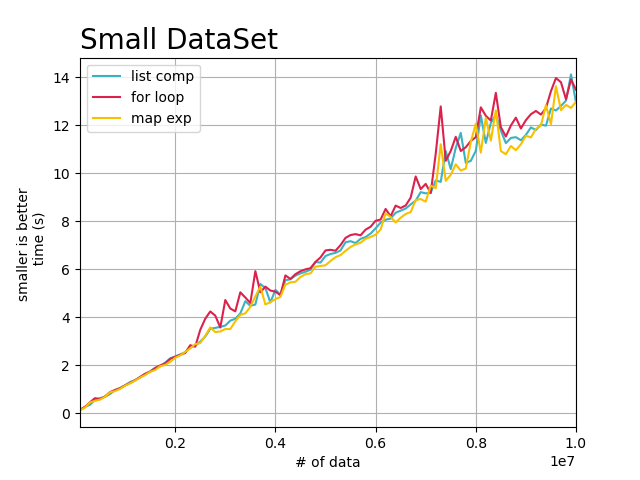
如上图,在小数据集上(100W-1KW之间), 三者消耗的时间差不多相等,但是用map方式遍历和处理,还是有一定的加速优势。
具体实验代码可以通过Github获得
[Python3]为什么map比for循环快的更多相关文章
- Map<String, String>循环遍历的方法
Map<String, String>循环遍历的方法 Map<String, String>循环遍历的方法 Map<String, String>循环遍历的方法 下 ...
- Python3 字典(map)
ayout: post title: Python3 字典(map) author: "luowentaoaa" catalog: true tags: mathjax: true ...
- Python2与Python3的map()
1. map()函数 Python2中,map(func, seq1[,seq2[...[,seqn)将func作用于seq*的每个序列的索引相同的元素,并最终生成一个[func(seq1[0], s ...
- forkjoin及其性能分析,是否比for循环快?
最近看了网上的某公开课,其中有讲到forkjoin框架.在这之前,我丝毫没听说过这个东西,很好奇是什么东东.于是,就顺道研究了一番. 总感觉这个东西,用的地方很少,也有可能是我才疏学浅.好吧,反正问了 ...
- 解决Python3下map函数的显示问题
今天小编就为大家分享一篇解决Python3下map函数的显示问题,具有很好的参考价值,希望对大家有所帮助.一起跟随小编过来看看吧map函数是Python里面比较重要的函数,设计灵感来自于函数式编程.P ...
- Python3下map函数的显示问题
map函数是Python里面比较重要的函数,设计灵感来自于函数式编程.Python官方文档中是这样解释map函数的: map(function, iterable, ...) Return an it ...
- java中对map使用entrySet循环
根据JDK5的新特性,用For循环Map,例如循环Map的Key 1 2 3 for(String dataKey : paraMap.keySet()) { System.out.p ...
- python3学习笔记十(循环语句)
参考http://www.runoob.com/python3/python3-loop.html 循环语句 while循环 # !/usr/bin/env python3 n = 100 sum = ...
- map和list循环遍历
//map遍历(zmm是实体类) Map<String, zmm> maps = new HashMap<String, zmm>(); //给map存值: maps.put( ...
随机推荐
- 使用python绘制世界人口地图及数据处理
本篇我们来说:下载和处理json格式的文件,并通过pygal中的地图工具来实现数据可视化 ------------------------------------------------------- ...
- 【Kafka】Producer API
Producer API Kafka官网文档给了基本格式 地址:http://kafka.apachecn.org/10/javadoc/index.html?org/apache/kafka/cli ...
- [vijos P1008 篝火晚会]置换
题意:编号1-n的小朋友依次围成一圈,给定目标状态每个小朋友左右两边的小朋友编号,每次可以选择编号为[b1,b2,...,bm]的小朋友,作1次轮换,bi是任意编号,代价为m.求变成目标状态所需的最小 ...
- [hdu4358]树状数组
思路:用一个数组记录最近k次的出现位置,然后在其附近更新答案.具体见代码: #pragma comment(linker, "/STACK:10240000,10240000") ...
- C#实现前向最大匹、字典树(分词、检索)
场景:现在有一个错词库,维护的是错词和正确词对应关系.比如:错词“我门”对应的正确词“我们”.然后在用户输入的文字进行错词校验,需要判断输入的文字是否有错词,并找出错词以便提醒用户,并且可以显示出正确 ...
- Mysql 常用函数(2)- if 函数
Mysql常用函数的汇总,可看下面系列文章 https://www.cnblogs.com/poloyy/category/1765164.html if 的作用 根据表达式的某个条件或值结果来执行一 ...
- ereg正则%00截断
0x01 <?php $flag = "xxx"; if (isset ($_GET['password'])) { if (ereg ("^[a-zA-Z0-9] ...
- 【Python代码】混合整数规划MIP/线性规划LP+python(ortool库)实现
目录 相关知识点 LP线性规划问题 MIP混合整数规划 MIP的Python实现(Ortool库) assert MIP的Python实现(docplex库) 相关知识点 LP线性规划问题 Linea ...
- 汇编语言 简单的Hello World
DATA SEGMENT STRING DB 'Hello World!','$' DATA ENDS CODE SEGMENT ASSUME CS:CODE, DS:DATA START: MOV ...
- 数据结构----二叉树Tree和排序二叉树
二叉树 节点定义 class Node(object): def __init__(self, item): self.item = item self.left = None self.right ...