使用Pytorch在多GPU下保存和加载训练模型参数遇到的问题
最近使用Pytorch在学习一个深度学习项目,在模型保存和加载过程中遇到了问题,最终通过在网卡查找资料得已解决,故以此记之,以备忘却。
首先,是在使用多GPU进行模型训练的过程中,在保存模型参数时,应该使用类似如下代码进行保存:
对应的在加载模型参数时,使用如下代码进行加载是没有问题的:

请注意红圈的地方缺了“module”关键字,导致在保存模型参数时,参数保存成了这样(模型参数是以key-value的形式保存的),即stat_dict(key),对应的value每个值都多了一个module:
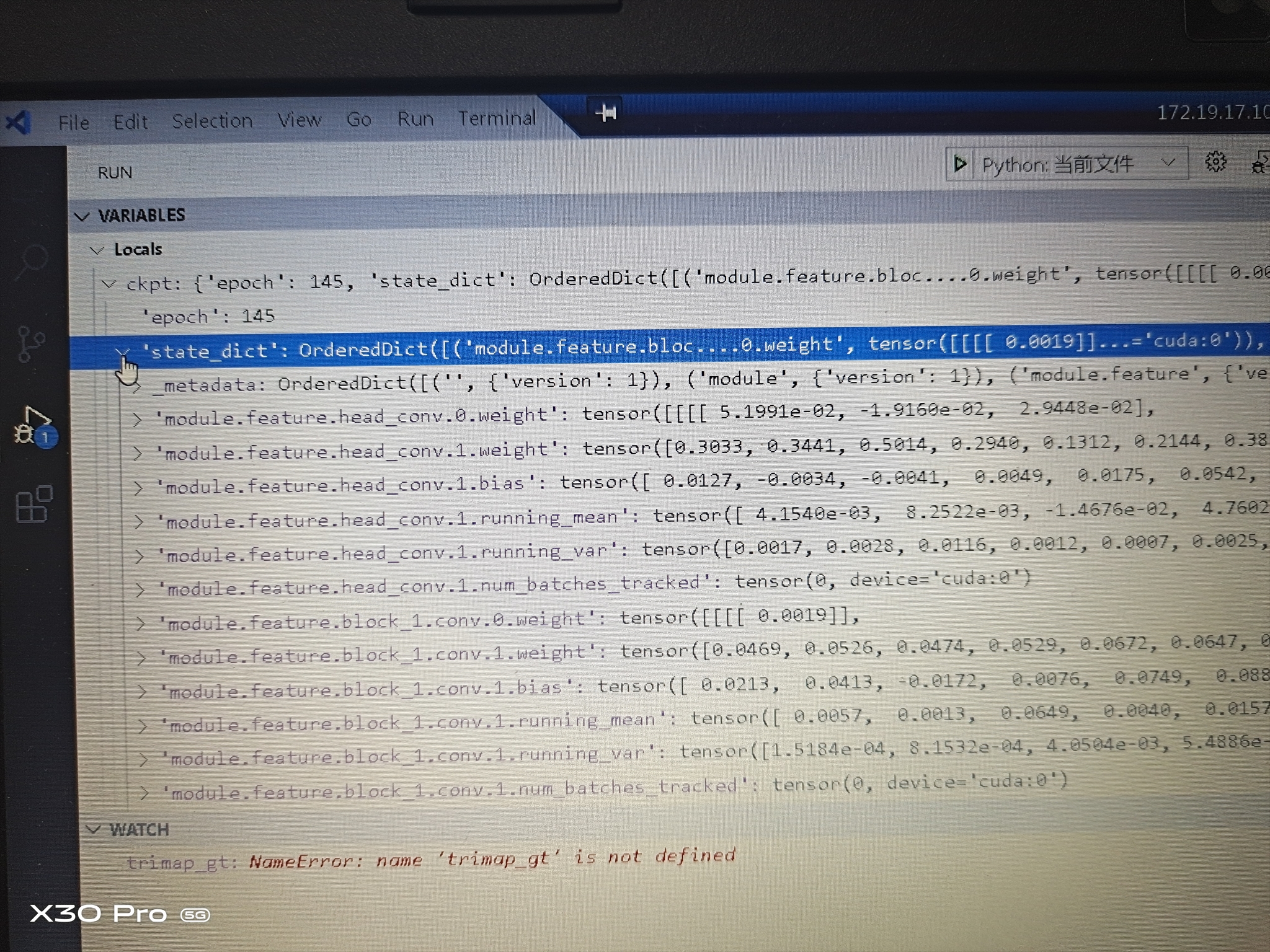
接下来在加载模型参数时,如果直接使用代码 model.load_state_dict(torch.load('模型参数文件存放路径')['state_dict'])就会出现问题。报错如下:
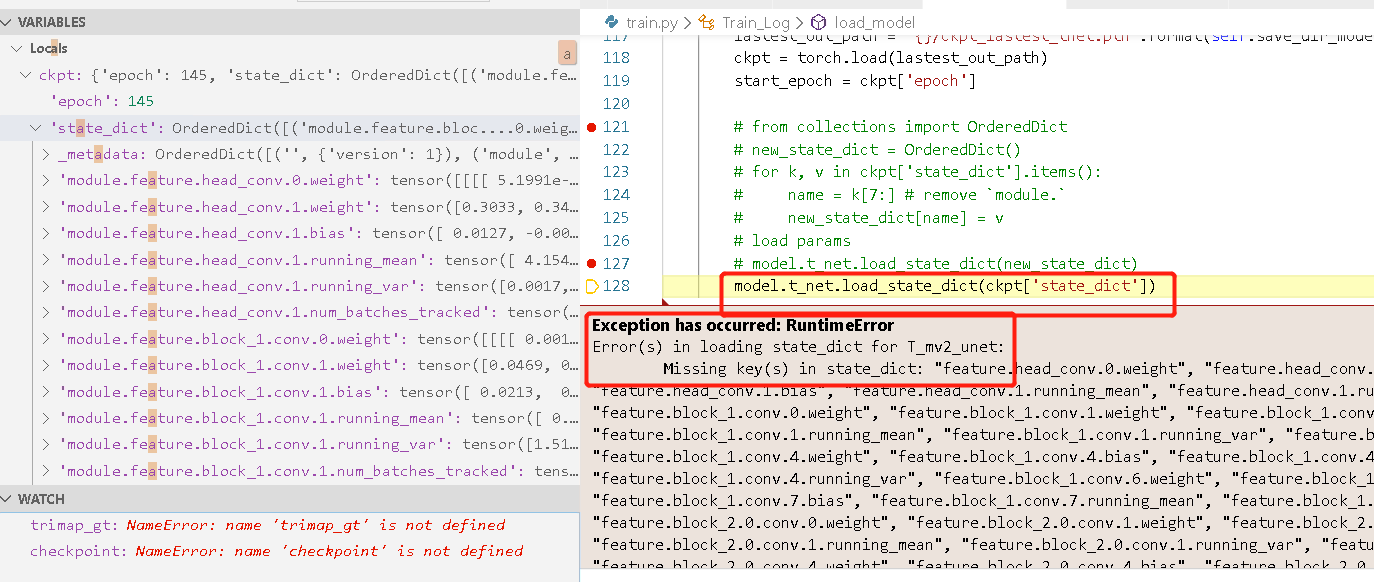
好了,既然知道了出问题的原因在哪里,那就来考虑下如何处理了,两种方案:
第一,修改保存模型的代码(加上"module")后,把模型重新训练一次,重新加载即可。但我们大家都知道,这样的深度模型训练,时间一般都是以小时或者天计的,我们等不了那么久。(如果时间允许,可以这么干。哈哈!)
第二,在加载模型参数之前,写代码将模型参数里的"module"关键字给去掉。比如可以这么写:

实话实说,这个代码并不是我的原创,网上给出这个解决方案的地方很多。但我这里有一点不同的时,我加了个“[state_dict]”,我看到的很多地方是没有这个的,直接就是ckpt.items()。因为我并不知道他们保存模型参数的代码是怎么写的,所以也并不好评论对错。但总之一句话,我们是要通过这段代码,去掉状态字典里的"module"关键字的所以大家可以通过debug,查看这里的k取到的是什么值,应该要是取到下图所示红色框里的值,然后通过“name=k[7:]”去掉前面的"module",然后再加载就可以了。

文中提到一个词“[state_dict]”,大家不用太在意,有的人在保存模型参数时,用的是“model”,只要在保存和读取的时候,保持一致就可以了。
欢迎大家对描述不清楚或者不准确的地方提出批评意见和建议!
使用Pytorch在多GPU下保存和加载训练模型参数遇到的问题的更多相关文章
- 从头学pytorch(十二):模型保存和加载
模型读取和存储 总结下来,就是几个函数 torch.load()/torch.save() 通过python的pickle完成序列化与反序列化.完成内存<-->磁盘转换. Module.s ...
- TensorFlow模型保存和加载方法
TensorFlow模型保存和加载方法 模型保存 import tensorflow as tf w1 = tf.Variable(tf.constant(2.0, shape=[1]), name= ...
- 背水一战 Windows 10 (62) - 控件(媒体类): InkCanvas 保存和加载, 手写识别
[源码下载] 背水一战 Windows 10 (62) - 控件(媒体类): InkCanvas 保存和加载, 手写识别 作者:webabcd 介绍背水一战 Windows 10 之 控件(媒体类) ...
- keras中的模型保存和加载
tensorflow中的模型常常是protobuf格式,这种格式既可以是二进制也可以是文本.keras模型保存和加载与tensorflow不同,keras中的模型保存和加载往往是保存成hdf5格式. ...
- 完美实现保存和加载easyui datagrid自定义调整列宽位置隐藏属性功能
需求&场景 例表查询是业务系统中使用最多也是最基础功能,但也是调整最平凡,不同的用户对数据的要求也不一样,所以在系统正式使用后,做为开发恨不得坐在业务边上,根据他们的要求进行调整,需要调整最多 ...
- 超详细的Tensorflow模型的保存和加载(理论与实战详解)
1.Tensorflow的模型到底是什么样的? Tensorflow模型主要包含网络的设计(图)和训练好的各参数的值等.所以,Tensorflow模型有两个主要的文件: a) Meta graph: ...
- 三、TensorFlow模型的保存和加载
1.模型的保存: import tensorflow as tf v1 = tf.Variable(1.0,dtype=tf.float32) v2 = tf.Variable(2.0,dtype=t ...
- tensorflow模型持久化保存和加载
模型文件的保存 tensorflow将模型保持到本地会生成4个文件: meta文件:保存了网络的图结构,包含变量.op.集合等信息 ckpt文件: 二进制文件,保存了网络中所有权重.偏置等变量数值,分 ...
- tensorflow模型持久化保存和加载--深度学习-神经网络
模型文件的保存 tensorflow将模型保持到本地会生成4个文件: meta文件:保存了网络的图结构,包含变量.op.集合等信息 ckpt文件: 二进制文件,保存了网络中所有权重.偏置等变量数值,分 ...
随机推荐
- 什么是Servlet?Servlet的周期和方法
1.什么是Servlet? Servlet是运行在web服务器或应用服务器的程序,它是作为来自web浏览器或其他http客户端的请求和HTTP服务器上的数据库或应用程序之间的中间层! 2.Servl ...
- 内存管理 malloc free 的实现
libc 中提供非常好用的 malloc free 功能,如果自己实现一个,应该怎么做. 要实现 malloc free 需要有 可以分配内存使用的堆,和记录内存使用情况的链表. 如下图所示,堆从高 ...
- 有关于python内置函数exec和eval一些见解笔记
eval是将函数内的字符串以计算式的方式进行计算并给与外部一个值. 例: a=eval('1+1') print(a) >>>>2 但是如果出现在函数内部字符串中进行赋值会抛出 ...
- 大数据学习之scala-环境搭建
scala 下载网站 https://www.scala-lang.org/download/ 安装scala要先安装java,并且配置java环境,官网也有说明 不过国内的网站下载不下来可以访问: ...
- jupyter 安装问题 building 'zmq.libzmq' extension error: Microsoft Visual C++ 14.0 is required. Get it with "Microsoft Visual C++ Build Tools": http://landinghub.visualstudio.com/visual-cpp-build-tools
1.用pip install jupyter 安装到一半就报错 错误提示: building 'zmq.libzmq' extension error: Microsoft Visual C++ 14 ...
- react 新创建项目
1,先创建一个文件夹用于存放项目 2,运行cmd,路径选择到你创建的文件夹内 3, npm install -g create-react-app create-react-app ...
- Python之split()函数
在Python的高级特性里有切片(Slice)操作符,可以对字符串进行截取.Python还提供split()函数可以将一个字符串分裂成多个字符串组成的列表. split()的语法挺简单的: str.s ...
- asp.net core系列 76 Apollo 快速安装模式下填坑和ASP.NetCore结合使用
前言:由于公司占时没有运维,出于微服务的需要,Apollo只能先装在windows 阿里云上跑起来,由于环境及网络等问题,在安装过程中遇到很多坑,算是一个个坑填完后,最终实现. 一. java jdk ...
- Java日期处理易踩的十个坑
前言 整理了Java日期处理的十个坑,希望对大家有帮助. 一.用Calendar设置时间的坑 反例: Calendar c = Calendar.getInstance(); c.set(Calend ...
- ubuntu 16.04配置svn服务器
为了操作方便,使用root登录服务器. 一.安装svn服务器 -->apt-get install subversion 二.创建svn版本库,存放需要管理内容路径 -->mkdir sv ...