HashMap主要方法源码分析(JDK1.8)

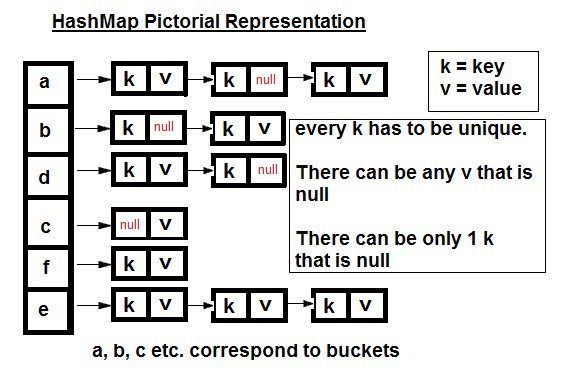
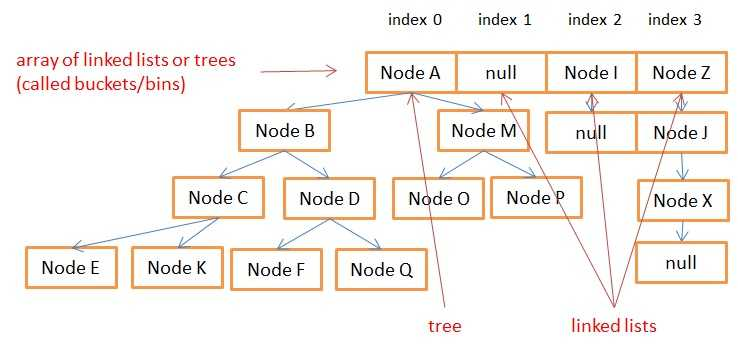
(转化为红黑树时的情况)
一、关于HashMap需要了解的静态常量
二、方法探究
1、put
HashMap中的数组是第一次调用put方法时才创建对象的
下面是从进入put到创建完数组的全过程
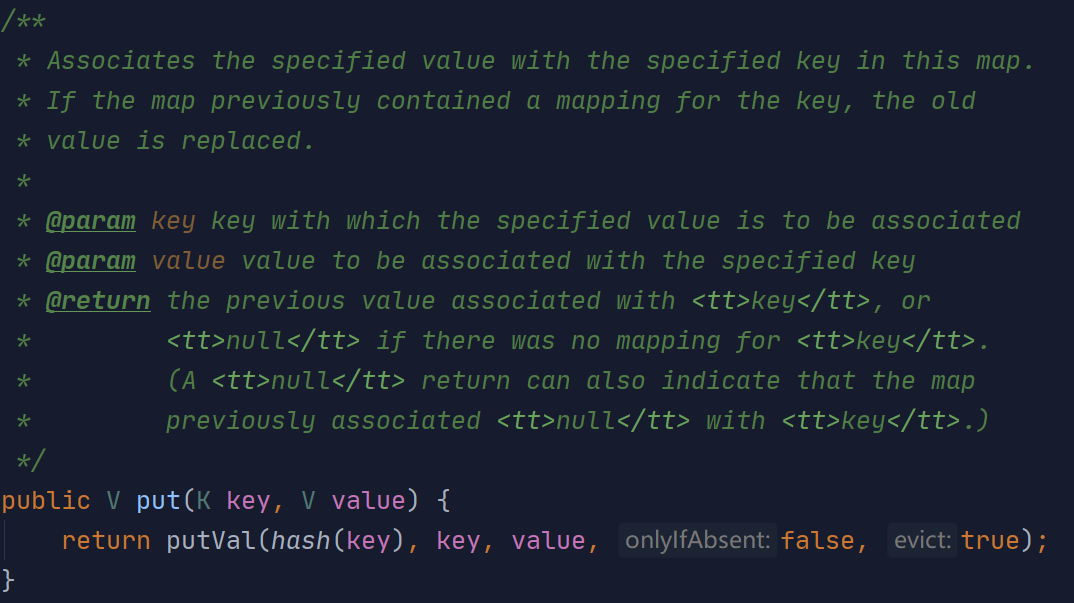
将key、value作为参数传入后,计算key的hash,再传入putVal方法
/**
* Implements Map.put and related methods.
*
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don't change existing value
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
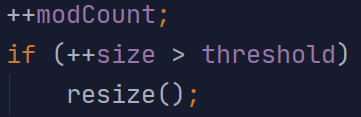
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}

/**
* Initializes or doubles table size. If null, allocates in
* accord with initial capacity target held in field threshold.
* Otherwise, because we are using power-of-two expansion, the
* elements from each bin must either stay at same index, or move
* with a power of two offset in the new table.
*
* @return the table
*/
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
resize

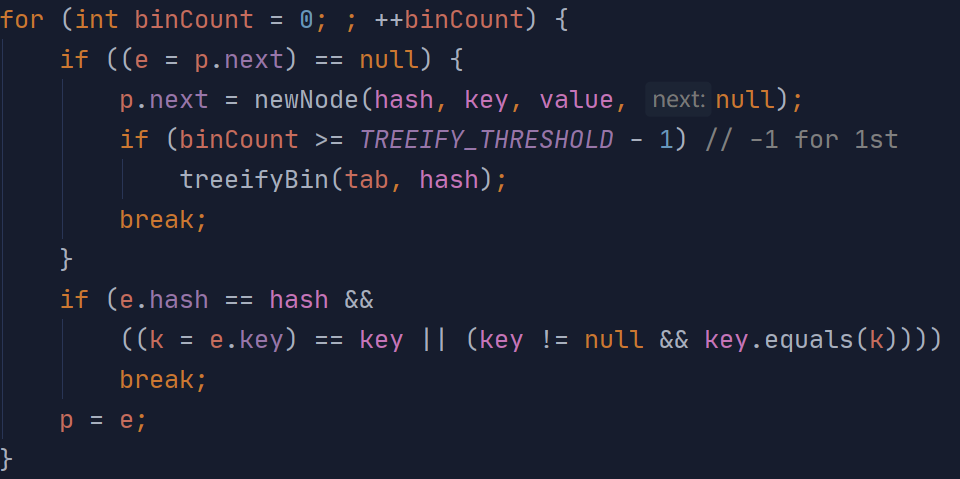
(向下遍历数组当前下标链表的操作)
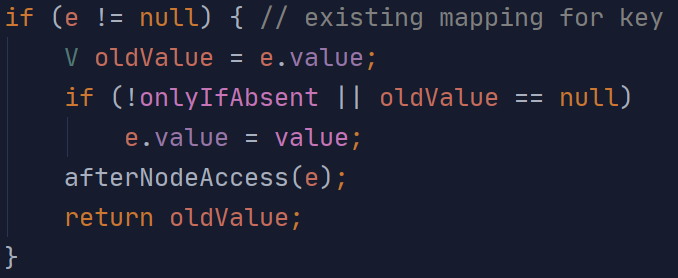
(key相同时value的替换操作)
2、get
* Returns the value to which the specified key is mapped,
* or {@code null} if this map contains no mapping for the key.
*
* <p>More formally, if this map contains a mapping from a key
* {@code k} to a value {@code v} such that {@code (key==null ? k==null :
* key.equals(k))}, then this method returns {@code v}; otherwise
* it returns {@code null}. (There can be at most one such mapping.)
*
* <p>A return value of {@code null} does not <i>necessarily</i>
* indicate that the map contains no mapping for the key; it's also
* possible that the map explicitly maps the key to {@code null}.
* The {@link #containsKey containsKey} operation may be used to
* distinguish these two cases.
*
* @see #put(Object, Object)
*/
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
get

(上面的first即为node可能存在的链表的第一个元素)
查找时如果第一个即匹配则直接返回

否则往下遍历直到匹配或node为null
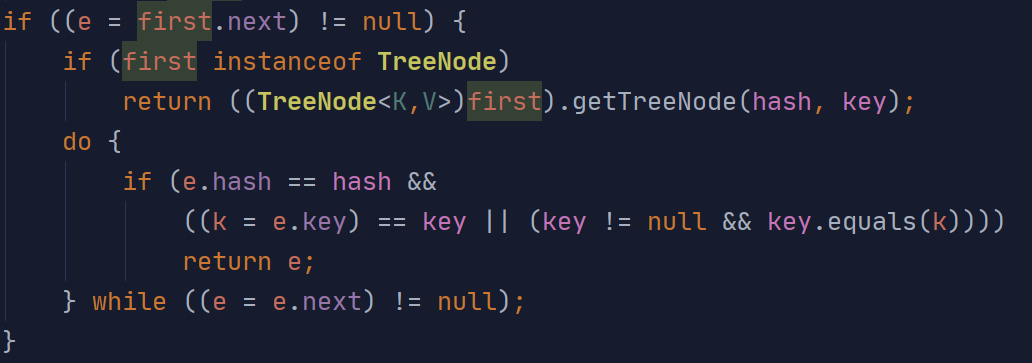
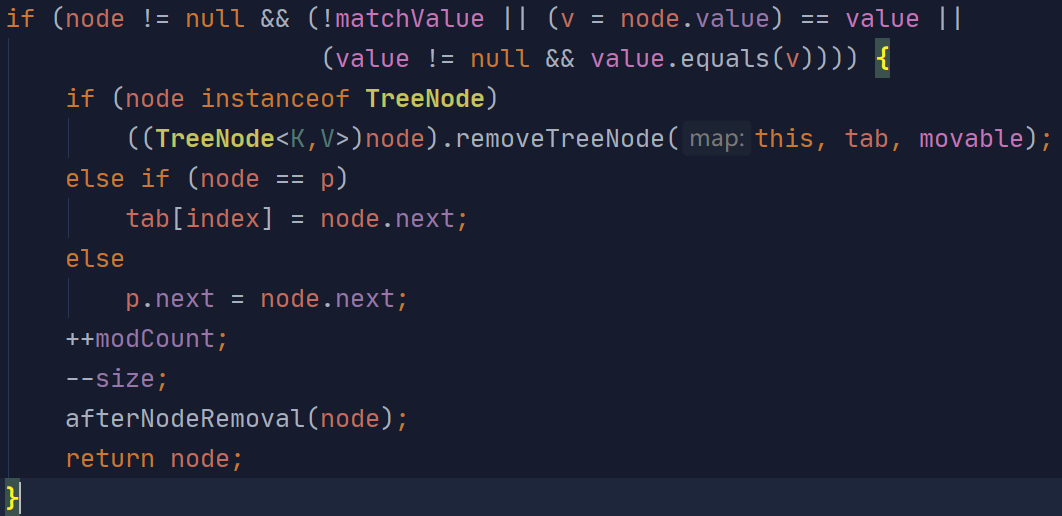
3、removeNode

/**
* Implements Map.remove and related methods.
*
* @param hash hash for key
* @param key the key
* @param value the value to match if matchValue, else ignored
* @param matchValue if true only remove if value is equal
* @param movable if false do not move other nodes while removing
* @return the node, or null if none
*/
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node<K,V>[] tab; Node<K,V> p; int n, index;
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
Node<K,V> node = null, e; K k; V v;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
else if ((e = p.next) != null) {
if (p instanceof TreeNode)
node = ((TreeNode<K,V>)p).getTreeNode(hash, key);
else {
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
if (node instanceof TreeNode)
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
else if (node == p)
tab[index] = node.next;
else
p.next = node.next;
++modCount;
--size;
afterNodeRemoval(node);
return node;
}
}
return null;
}
removeNode
与getNode的逻辑类似,利用hash值查找可能存在的位置
如果链表第一位就匹配:

对链表的遍历:
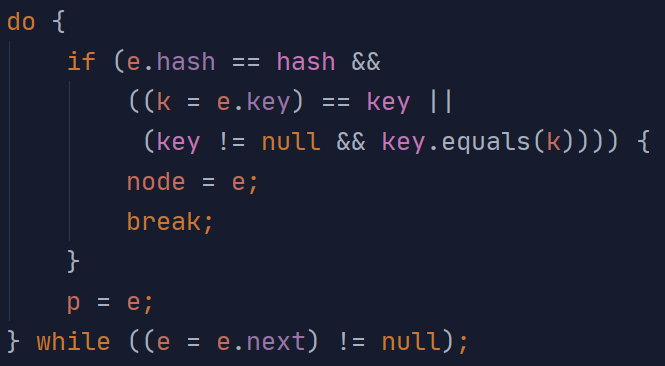
判断node的类型,如果是链表则用node.nest来代替当前位置
最后操作数+1,size-1,返回被remove的node对象
HashMap主要方法源码分析(JDK1.8)的更多相关文章
- 并发-HashMap和HashTable源码分析
HashMap和HashTable源码分析 参考: https://blog.csdn.net/luanlouis/article/details/41576373 http://www.cnblog ...
- ArrayList源码分析--jdk1.8
ArrayList概述 1. ArrayList是可以动态扩容和动态删除冗余容量的索引序列,基于数组实现的集合. 2. ArrayList支持随机访问.克隆.序列化,元素有序且可以重复. 3. ...
- ReentrantLock源码分析--jdk1.8
JDK1.8 ArrayList源码分析--jdk1.8LinkedList源码分析--jdk1.8HashMap源码分析--jdk1.8AQS源码分析--jdk1.8ReentrantLock源码分 ...
- HashMap原理及源码分析
HashMap 原理及源码分析 1. 存储结构 HashMap 内部是由 Node 类型的数组实现的.Node 包含着键值对,内部有四个字段,从 next 字段我们可以看出,Node 是一个链表.即数 ...
- Java split方法源码分析
Java split方法源码分析 public String[] split(CharSequence input [, int limit]) { int index = 0; // 指针 bool ...
- invalidate和requestLayout方法源码分析
invalidate方法源码分析 在之前分析View的绘制流程中,最后都有调用一个叫invalidate的方法,这个方法是啥玩意?我们来看一下View类中invalidate系列方法的源码(ViewG ...
- Linq分组操作之GroupBy,GroupJoin扩展方法源码分析
Linq分组操作之GroupBy,GroupJoin扩展方法源码分析 一. GroupBy 解释: 根据指定的键选择器函数对序列中的元素进行分组,并且从每个组及其键中创建结果值. 查询表达式: var ...
- HashMap源码分析 JDK1.8
本文按以下顺序叙述: HashMap的感性认识. 官方文档中对HashMap介绍的解读. 到源码中看看HashMap这些特性到底是如何实现的. 把源码啃下来有一种很爽的感觉, 相信你读完后也能体会到~ ...
- HashMap实现原理及源码分析(jdk1.8)
HashMap底层由数组+链表+红黑树组成,可接受null值,非线程安全 1.基本属性 transient Node<K,V>[] table; //hashmap数组 static fi ...
随机推荐
- WebStorm添加Angular2服务启动的脚本命令
注意:选择的start在package.json可以修改. 例如添加一个run命令:
- Servlet(二)----注解配置
## Servlet3.0 * 好处: * 支持注解配置.可以不需要web.xml了. * 步骤: 1.创建JavaEE项目,选择Servlet的版本3.0以上,可以不创建web.xml 2. ...
- [dp]牛牛与数组
时间限制:C/C++ 1秒,其他语言2秒 空间限制:C/C++ 32768K,其他语言65536K 64bit IO Format: %lld 题目描述 牛牛喜欢这样的数组: 1:长度为n 2:每一个 ...
- matplotlib命令与格式:参数配置文件与参数配置
转自 https://my.oschina.net/swuly302/blog/94805 自定义matplotlib Created Saturday 08 December 2012 5.1 ma ...
- Linux时间和现实时间不同步解决方案
输入三条命令 yum install ntpdate -y ntpdate tiger.sina.com.cnping tiger.sina.com.cn 然后输入date检查时间是否已经同步
- Python python 五种数据类型--字典
# 定义一个字典 var1 = {'a':20,'b':40}; var2 = dict(); print(type(var1)) print(type(var2)) # 长度 length = le ...
- 数据挖掘入门系列教程(八)之使用神经网络(基于pybrain)识别数字手写集MNIST
目录 数据挖掘入门系列教程(八)之使用神经网络(基于pybrain)识别数字手写集MNIST 下载数据集 加载数据集 构建神经网络 反向传播(BP)算法 进行预测 F1验证 总结 参考 数据挖掘入门系 ...
- 一些常用关键字的用法(一.static)
17:36:26 2020-04-05 又是充实的一天,刚刚开始学习不久java的我,从面向过程的语言转变到面向对象的语言,在思想上上还是需要花费很多时间转变的.今天学习到了这几个关键字了,觉得这几个 ...
- [codevs1049]棋盘染色<迭代深搜>
题目链接:http://codevs.cn/problem/1049/ 昨天的测试题里没有打出那可爱的迭代深搜,所以今天就来练一练. 这道题其实我看着有点懵,拿着题我就这状态↓ 然后我偷偷瞄了一眼hz ...
- Cplex教育版申请
任何人:直接在公众号"毒书 彼记" ,“资源下载” 板块下载: 如果你的学校没有购买cplex软件没那么,你就不可以下载教育版的cplex软件,如过下载免费板,它的功能会有一些限制 ...