python闯关之路一(语法基础)
1,什么是编程?为什么要编程?
答:编程是个动词,编程就等于写代码,那么写代码是为了什么呢?也就是为什么要编程呢,肯定是为了让计算机帮我们搞事情,代码就是计算机能理解的语言。
2,编程语言进化史是什么?
答:机器语言 ------> 汇编语言 ------> 高级语言
机器语言:由于计算机内部只能接受二进制代码,因此,用二进制代码0和1描述的指令称为机器指令,全部机器指令的集合构成计算机的机器语言,机器语言属于低级语言。
汇编语言:其实质和机器语言是相同的,都是直接对硬件操作,只不过指令采取了英文缩写的标识符,更容易识别和记忆。
高级语言:是大多数编程人员的选择,和汇编语言相比,他不但将许多相关的机器指令合成为单条指令,并且去掉了与具体操作相关但与完成工作无关的细节,高级语言主要是相对于汇编语言而言,它并不是特指某一种具体的语言,而是包含了许多编程语言。如C/C++,JAVA,PHP,PYTHON等都属于高级语言。
机器语言:优点是最底层,速度快,缺点是复杂,开发效率低
汇编语言:优点是比较底层,速度快,缺点是复杂,开发效率低
高级语言:编译型语言执行速度快,不依赖语言环境运行,跨平台差
解释型跨平台比较好,一份代码,到处使用,缺点是执行效率慢,依赖解释器运行,相比于机器和汇编语言,高级语言对开发人员更友好,在开发效率上大大提高。
3,简述编译型与解释型语言的区别,且分别列出你知道的哪些语言属于编译型,那些属于解释型
高级语言所编制的程序不能被计算机所知别,必须讲过转换才能被执行,按照转换方式,可以将其分为两类,一类是编译类,一类是解释类
编译类:就是在应用源码程序执行之前,就将程序源代码“翻译”成目标代码(机器语言),因此其目标程序可以脱离其语言环境独立执行。使用比较方便,效率也高,但是应用程序一旦需要修改,必须先修改源代码,再重新编译生成新的目标(*.obj ,也就是OBJ文件)才能执行,只有目标文件而没有源代码,修改很不方便。
特点:编译后程序运行时不需要重新翻译,直接使用编译的结果就行了。程序执行效率高,依赖编译器,跨平台性比较差,如C,C++,Delphi等
优点:1,执行程序时候,不需要源代码,不依赖语言环境,因为执行的是机器源文件。
2,执行速度快,因为程序代码已经翻译成计算机可以理解的机器语言。
缺点:1,每次修改了源代码,需要重新编译,生成机器编码文件
2,跨平台性不好,不同操作系统,调用底层的机器指令不同,需要为不同的平台生成不同的机器码文件。
解释类:执行方式类似于我们生活中的“同声翻译”,应用程序源代码一边由相应语言的解释器“翻译”成目标代码(机器语言),一边执行,一边翻译,因此效率比较低。
特点:效率低,不能生成独立的可执行文件,应用程序不能脱离其解释器,但是这种方式比较灵活,可以动态的调整,修改应用程序。如Python,Java,PHP,Ruby等语言。
优点:1,用户调用解释器,执行源码文件,而且可以随时修改,立即见效,改完源代码,直接运行看结果
2,解释器把源码文件一边解释成机器指令,一边交给CPU执行,天生跨平台,因为解释器已经做好了对不同平台的交互处理,用户写的源代码不需要考虑平台差异性。
缺点:1,代码是明文
2,运行效率低,所有的代码是需要解释器边解释边执行,速度比编译型慢很多。
4,执行python脚本的两种方式是什么?
1,交互器执行,在控制台上运行临时输入的代码
2,文件操作,执行一个保存好的py文件
两者的区别是:一个是内存操作,一个是硬盘操作,
内存的特点是:读取速度快,但是断电就丢失数据
硬盘的特点是:速度慢,但可以保存数据
5,声明变量注意事项是什么?
变量定义规则:
1,变量名只能是字母,数字或者下划线的任意组合
2,变量名的第一个字符不能是数字
3,关键字不能生命问变量名
注意事项:
1,变量名不能过长
2,变量名词不达意思
3,变量名为中文,拼音
6,什么是常量?
常量指不变的量,或者在程序运行过程中不会改变的量
在python中没有一个专门的语法代表常量,程序员约定俗成用变量名全部大写代表常量
7,python的单行注释和多行注释分别用什么?
单行注释# 多行注释"""
代码注释原则:
1,不用全部加注释,只需要在自己觉得重要或者不好理解的部分加注释即可
2,注释可以用中文或者英文,但绝对不要拼音
8,布尔值分别有什么?
布尔类型很简单,就两个值,一个是True(真),一个是False(假),主要用于逻辑判断
9,如何查看变量在内存中的地址?
这里使用id
print(id.__doc__) Return the identity of an object. This is guaranteed to be unique among simultaneously existing objects. (CPython uses the object's memory address.)
10,写代码
10-1,实现用户输入用户名,当用户名为james,且密码是123456,显示登陆成功,否则登陆失败。
_username = "james"
_password = "123456"
username = input("请输入名字>>>")
password= input("请输入密码>>>")
if username==_username and password==_password:
print("登陆成功")
else:
print("登陆失败")
10-2,实现用户输入用户名,当用户名为james,且密码是123456,显示登陆成功,否则登陆失败,失败次数允许重复三次
_username = "james"
_password = "123456"
count =0
while count<3:
username = input("请输入名字>>>")
password = input("请输入密码>>>")
if username==_username and password==_password:
print("登陆成功")
break
else:
print("登陆失败")
count +=1
10-3,实现用户输入用户名,当用户名为james,或密码是123456,显示登陆成功,否则登陆失败,失败次数允许重复三次
_username = "james"
_password = "123456"
count =0
while count<3:
username = input("请输入名字>>>")
password = input("请输入密码>>>")
if username==_username or password==_password:
print("登陆成功")
break
else:
print("登陆失败")
count +=1
11,写代码
a,使用while循环实现输出2-3+4-5+6....+100的和
count =2
num =0
while count<=100:
if count%2==0:
num = num+count
else:
num = num -count
count+=1
print(num)
b,使用while循环实现输出1,2,3,4,5,7,8,9,11,12
count =1
while count<=12:
if count==6 or count==10:
pass
else:
print(count)
count+=1
c,使用while循环输出100-50,从大到小,如100,99,98...,到50时候再从0循环输出到50,然后结束
count = 100
while count >= 50:
print(count)
count -= 1
if count == 49:
count = 0
while count <= 50:
print(count)
count += 1
break
d,使用while循环实现输出1-100内所有的奇数
count =0
while count <=100:
if count %2!=0:
print(count)
count +=1
e,使用while循环实现输出1-100内所有的偶数
count =0
while count <=100:
if count %2==0:
print(count)
count +=1
12,编程题:输入一年份,判断该年份是否属于闰年并输出结果
(注意闰年条件:1,能被四整除但不能被一百整除,2,能被四百整除)
if number%4==0 and number%100!=0 or number%400==0:
print("%s 是闰年"%number)
else:
print("%s 不是闰年" % number)
13,编程题:假设一年期定期利率为3.24%,计算一下需要经过多少年,一万元的一年定期存款连本带息能翻倍?
money =10000
rate = 0.0324
years =0
while money <20000:
years+=1
money = money*(1+rate)
print(str(years))
14,什么是运算符?
计算机可以进行的运算有很多种,可不止加减乘除那么简单,运算按种类可以分为算数运算,比较运算,逻辑运算,赋值运算,成员运算,身份运算,位运算等
下面简单介绍算术运算,比较运算,逻辑运算,赋值运算

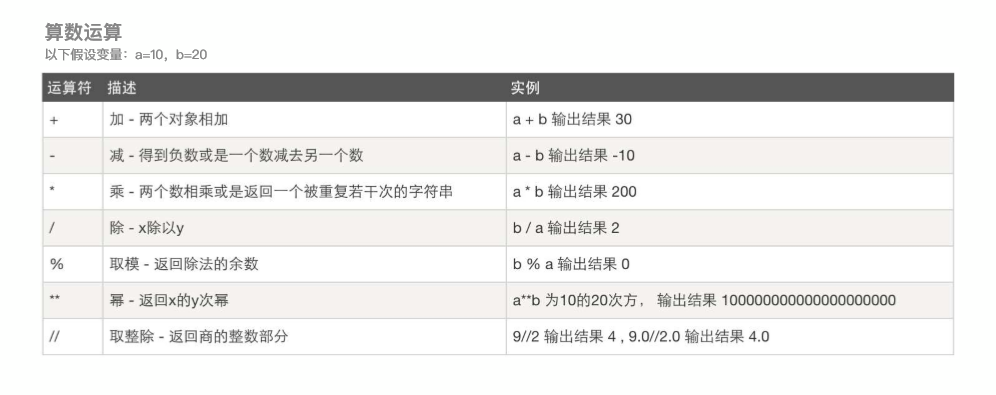
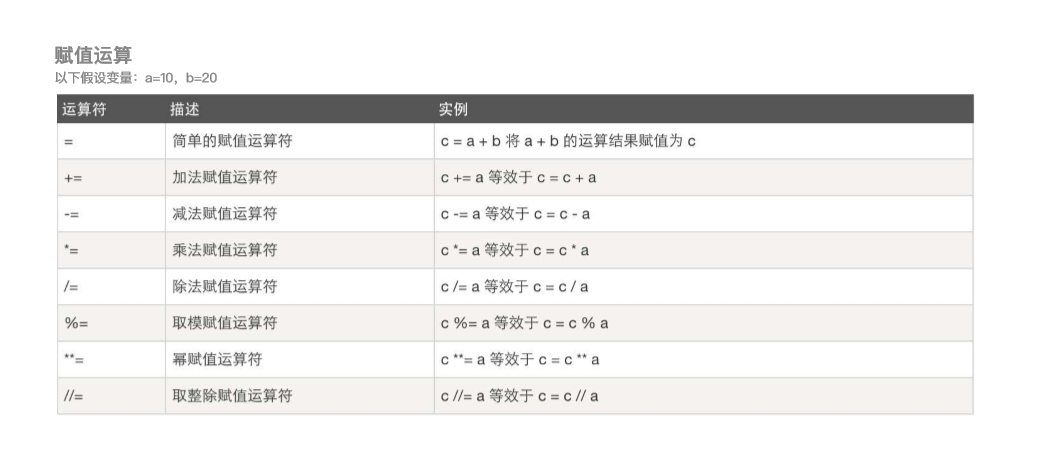
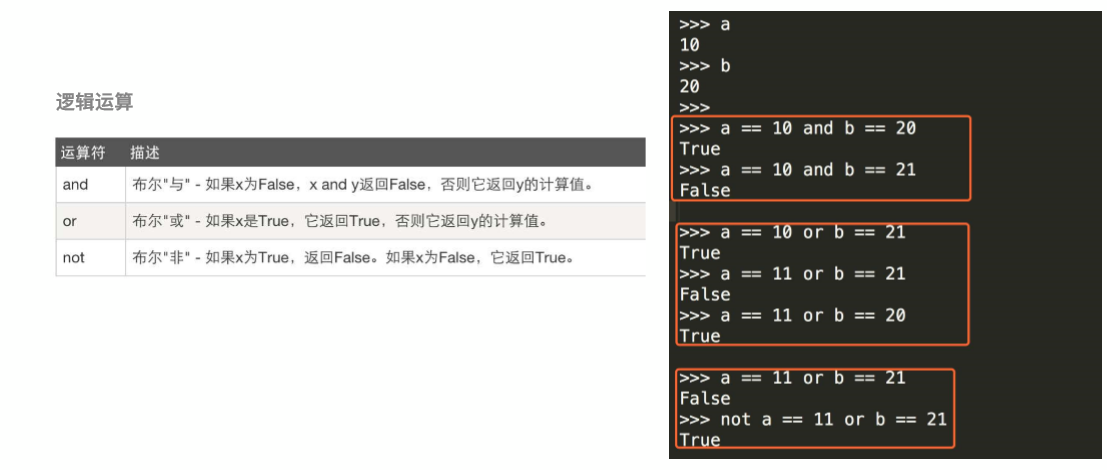
15,什么是循环终止语句?
如果在循环的过程中,因为某些原因,你不想继续循环了,怎么把它终止掉呢?这就用到了break或者continue语句了
break用于完全结束一个循环,跳出循环体执行循环后面的语句
continue和break有点类似,区别在于continue只是终止本次循环,接着还执行后面的循环,break则完全终止循环
16,python中断多重循环的方法exit_flag
常见的方法:
exit_flag = flase
for 循环:
for 循环:
if 条件
exit_flag = true
break #跳出里面的循环
if exit_flag:
break #跳出外面的循环
17,基本数据类型和扩展数据类型的分类?
基本数据类型:
可变数据类型:列表,字典,集合
不可变数据类型:字符串,元组,数字
扩展性数据类型:
1,namedtuole():生成可以使用名字来访问元素内容的tuple子类
2,deque:双端队列,可以快速的从另一侧追加和推出对象
3,counter:计数器,主要用来计数
4,orderdict:有序字典
5,defaultdict:带有默认值的字典
18,元组的特点和功能
特点:
不可变,所以又称只读列表
本身不可变,但是如果元祖中还包含了其他可变元素,这些可变元素可以改变
功能:
索引
count
切片
19,简单讲一下hash
hash,一般翻译做“散列”,也有直接音译为“哈希”的,就是把任意长度的输入,通过散列算法,变化成固定长度的输出,该输出就是散列值,这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能散列成相同的输出,所以不可能从散列值来唯一的确定输入值,简单的说就是有一种将任意长度的消息压缩到某一固定长度的函数。
特性:hash值的计算过程是依据这个值的一些特性计算的,这就要求被hash的值必须固定,因此被hash的值是不可变的。
20,为什么使用16进制
1,计算机硬件是0101二进制,16进制刚好是2的倍数,更容易表达一个命令或者数据,十六进制更简短,因为换算的时候一位16进制数可以顶4位二进制数,也就是一个字节(8位进制可以用两个16进制表示)
2,最早规定ASCII字符采取的就是8bit(后期扩展了,但是基础单位还是8bit),8bit用两个16进制直接就能表达出来,不管阅读还是存储逗逼其他进制更方便。
3,计算机中CPU计算也是遵循ASCII字符串,以16,32,64这样的方法在发展,因此数据交换的时候16进制也显得更好
4,为了统一规范,CPU,内存,硬盘我们看到的都是采取的16进制计算
21,字符编码转换总结
python2.x
内存中字符默认编码是ASCII,默认文件编码也是ASCII
当声明了文件头的编码后,字符串的编码就按照文件编码来,总之,文件编码是什么,那么python2.x的str就是什么
python2.x的unicode是一个单独的类型,按u"编码"来表示
python2.x str==bytes,bytes直接是按照字符编码存成2进制格式在内存里
python3.x
字符串都是unicode
文件编码都默认是utf-8,读到内存会被python解释器自动转成unicode
bytes和str做了明确的区分
所有的unicode字符编码后都会编程bytes格式
22,请用代码实现,查找列表中元素,移除每个元素的空格,并查找以a或者A开头并且以c结尾的所有元素
li =['alex','eric','rain']
tu =('alex','aric','Tony','rain')
dic = {'k1':'alex','aroc':'dada','k4':'dadadad'}
for i in li:
i_new = i.strip().capitalize()
if i_new.startswith('A') and i_new.endswith('c'):
print(i_new)
for i in tu:
i_new0 = i.strip().capitalize()
if i_new0.startswith('A') and i_new.endswith('c'):
print(i_new0)
for i in dic:
i_new1 = i.strip().capitalize()
if i_new1.startswith('A') and i_new.endswith('c'):
print(i_new1)
23,利用for循环和range输出9*9乘法表
for i in range(1,10):
for j in range(1,i+1):
print(str(i)+"*"+str(j) +"="+str(i*j),end=' ')
print( )
24,利用for循环和range循环输出:
1,for循环从大到小输出1-100
2,for循环从小到大输出100-1
3,while循环从大到小输出1-100
4,while循环从小到大输出100-1
a =info.setdefault('age')
print(a)
print(info)
b =info.setdefault('sex')
print(b)
print(info)
for i in range(1,101):
print(i)
value =list(range(1,101))
print(value)
for i in range(100,0,-1):
print(i)
value =list(range(100,1,-1))
i =1
while i<101:
print(i)
i+=1
i =100
while i>0:
print(i)
i-=1
25,有两个列表,l1和l2 l1 =[11,22,33] l2 = [22,33,44]
1,获取内容相同的元素列表
2,获取l1中有,l2中没有的元素
3,获取l2中有,l1中没有的元素
4,获取l1中没有,l2中没有的元素
l1 = [11,22,33]
l2 = [22,33,44]
a =[]
for i1 in l1:
for i2 in l2:
if i1==i2:
a.append(i1)
print(a)
a =[]
for i1 in l1:
if i1 not in l2:
a.append(i1)
print(a)
a =[]
for i1 in l2:
if i1 not in l1:
a.append(i1)
print(a)
a1 =set(l1)&set(l2)
print(a1)
a2 =set(l1)^set(l2)
print(a2)
26,列举布尔值为False的所有值
所有标准对象均可用于布尔测试,同类型的对象之间可以比较大小,每个对象天生具有布尔值,空对象,值为0的任何数字或者Null对象None的布尔值都是False
下面对象的布尔值为False:
所有值为0的数
0(整数)
0(浮点数)
0L(长整形)
0.0+0.0j(复数)
“”(空字符串)
[](空列表)
()(空元组)
{}(空字典)
值不是上面列出来的都是True.
27,输入商品列表,用户输入序号,显示用户选中的商品,商品=【‘手机’,‘电脑’,‘电视’,‘冰箱’】允许用户添加内容,用户输入序号显示内容
print("输出商品列表,用户输入序号,显示用户选中的商品")
li = ["手机", "电脑", '鼠标垫', '游艇']
for i,j in enumerate(li,1): #自定义列表索引下标,从1开始,将列表索引下标赋值给i,将列表值赋值给j
print(i,j)#打印出列表的索引下标,和列表的值
a = input("请输入商品序号") #要求用户输入商品序号
if a.isdigit():#判断用户输入的是否是纯数字
pass
else:
exit("你输入的不是有效的商品序号")#如果不是纯数字打印提示信息,并且退出程序,不在往下执行
a = int(a) #将用户输入的序号转换成数字类型
b = len(li)#统计li列表的元素个数
if a > 0 and a <= b: #判断
c = li[a-1]
print(c)
else:
print("商品不存在")
28,元素分类,有如下集合 [11,22,33,44,55,66,77,88,99],将所有大于66的值保存到第一个key的值中,将所有小于66的值保存到第二个key的值中,{'k1':大于66的值,‘k2’:‘小于66的值}
list1 = [11,22,33,44,55,66,77,88,99]
b =[]
c=[]
for i in list1:
if i>66:
b.append(i)
else:
c.append(i)
print(b)
print(c)
dict1 = {'k1':b,'k2':c}
29,元素分类,有如下集合 [11,22,33,44,55,66,77,88,99],将所有大于66的值保存到一个列表,小于66的保存到另一个列表
list1 = [11,22,33,44,55,66,77,88,99]
dict1 = {'k1':{},'k2':{}}
b =[]
c=[]
for i in list1:
if i>66:
b.append(i)
else:
c.append(i)
print(b)
print(c)
30,查找列表,元组,字典,中元素,移除每个元素的空格,并查找以 a或A开头 并且以 c 结尾的所有元素。
print("查找列表中元素,移除每个元素的空格,并查找以 a或A开头 并且以 c 结尾的所有元素。")
li = ["aleb", " aric", "Alex", "Tony", "rain"]
for i in li:
b = i.strip() #移除循环到数据的两边空格
#判断b变量里以a或者A开头,并且以c结尾的元素
#注意:如果一个条件语句里,or(或者),and(并且),都在条件判断里,将前面or部分用括号包起来,当做一个整体,
#不然判断到前面or部分符合了条件,就不会判断and后面的了,括起来后不管前面符不符合条件,后面的and都要判断的
if (b.startswith("a") or b.startswith("A")) and b.endswith("c"):
print(b) #打印出判断到的元素
tu = ("aleb", " aric", "Alex", "Tony", "rain")
for i in tu:
b = i.strip()
if (b.startswith('a') or b.startswith("A")) and b.endswith("c"):
print(b)
dic = {'k1': "alex", 'k2': ' aric',"k3": "Alex","k4": "Tony"}
for i in dic:
b =dic[i].strip()
if( b.startswith('a') or b.startswith("A") )and b.endswith("c"):
print(b)
31,写代码:有如下列表,请按照功能要求实现每一功能
li=['hello','seveb',['mon',['h','key'],'all',123,446]
1,请根据索引输出'kelly’
2,请使用索引找到”all“元素,并将其修改为”ALL“,如”li[0][1][9]...
li =['hello','seven',['mon',['h','kelly'],'all'],123,446] print(li[2][1][1]) print(li[2][2]) li[2][2] = "ALL" print(li[2][2]) a = li[2][2].upper() print(a)<br>li[2][index] ="ALL"<br>print(li)
32,写代码,要求实现下面每一个功能
li=['alex','eric','rain']
1,计算列表长度并输出
2,列表中追加元素“servn",并输出添加后的列表
3,请在列表的第一个位置插入元素‘tony’,并输出添加后的列表
4,请修改列表位置元素‘kelly’,并输出修改后的列表
5,请在列表删除元素‘eric’,并输出删除后的列表
6,请删除列表中的第2个元素,并输出删除后的元素的值和删除元素后的列表
7,请删除列表中的第三个元素,并输出删除后的列表
8,请删除列表的第2到4个元素,并输出删除元素后的列表
9,请用for len range输出列表的索引
10,请使用enumrate输出列表元素和序号
11,请使用for循环输出列表中的所有元素
li = ['alex','eric','rain']
# 1,计算列表长度并输出
# print(len(li))
# 列表中追加元素“seven”,并输出添加后的列表
# li.append('seven')
# print(li)
# 请在列表的第1个位置插入元素“Tony”,并输出添加后的列表
# li.insert(1,'tony')
# print(li)
#请修改列表第2个位置的元素为“Kelly”,并输出修改后的列表
# li[1] ='kelly'
# print(li)
# 请删除列表中的元素“eric”,并输出修改后的列表
# a =li.pop(2)
# print(li)
# li.remove('eric')
# print(li)
# 请删除列表中的第2个元素,并输出删除元素后的列表
# b =li.pop(1)
# print(b)
# print(li)
# 请删除列表中的第2至4个元素,并输出删除元素后的列表
# c = li[2:4]
# d = set(li)-set(c)
# # print(list(d))
# del li[1:4]
# print(li)
# 请将列表所有的元素反转,并输出反转后的列表
# e = li.reverse()
# print(li)
# 请使用for、len、range输出列表的索引
# for i in range(len(li)):
# print(i)
# 请使用enumrate输出列表元素和序号(序号从100开始)
# for index in enumerate(li):
# print(index)
# for index,i in enumerate(li,100):
# print(index,i)
# for i in li:
# print(i)
33,写代码,有如下元组,请按照功能要求实现每一个功能
tu = ('alex','eric,'rain')
1,计算元组的长度并输出
2,获取元祖的第二个元素,并输出
3,获取元祖的第1-2个元素,并输出
4,请用for输出元祖的元素
5,请使用for,len,range输出元组的索引
6,请使用enumerate输出元组元素和序号,(从10开始)
tu = ('alex','eric','rain')
# 1,计算元组的长度并输出
print(len(tu))
# 2,获取元祖的第二个元素,并输出
print(tu[1])
# 3,获取元祖的第1-2个元素,并输出
print(tu[0:2])
# 4,请用for输出元祖的元素
for i in tu:
print(i)
# 5,请使用for,len,range输出元组的索引
for i in range(len(tu)):
print(i)
# 6,请使用enumerate输出元组元素和序号,(从10开始)
for index,i in enumerate(tu,10):
print(index,i)
34,有如下变量,请实现要求的功能
tu=("alex",[11,22,{"k1":'v1',"k2":["age","name"],"k3":(11,22,33)},44])
a.讲述元祖的特性
答:元组具有列表的全部特性,不同的是,元组的元素不能修改
b.请问tu变量中的第一个元素“alex”是否可被修改?
答:不能
c.请问tu变量中的"k2"对应的值是什么类型?是否可以被修改?如果可以,请在其中添加一个元素“Seven”
答:列表 ,可以
tu = ("alex", [11, 22, {"k1": 'v1', "k2": ["age", "name"], "k3": (11, 22, 33)}, 44])
tu[1][2]["k2"].append("Seven")
print(tu)
d.请问tu变量中的"k3"对应的值是什么类型?是否可以被修改?如果可以,请在其中添加一个元素“Seven”
答: 元组,不能
35,练习字典
dic={'k1':"v1","k2":"v2","k3":[11,22,33]}
a.请循环输出所有的key
b.请循环输出所有的value
c.请循环输出所有的key和value
d.请在字典中添加一个键值对,"k4":"v4",输出添加后的字典
e.请在修改字典中“k1”对应的值为“alex”,输出修改后的字典
f.请在k3对应的值中追加一个元素44,输出修改后的字典
g.请在k3对应的值的第1个位置插入个元素18,输出修改后的字典
dic={'k1':"v1","k2":"v2","k3":[11,22,33]}
# a.请循环输出所有的key
for i in dic :
print(i)
for i in dic.keys():
print(i)
# b.请循环输出所有的value
for i in dic.values():
print(i)
# c.请循环输出所有的key和value
for i,j in dic.items():
print(i,j)
# d.请在字典中添加一个键值对,"k4":"v4",输出添加后的字典
dic2 = {'k4':'v4'}
dic.update(dic2)
print(dic)
dic['k4'] = 'v4'
print(dic)
# e.请在修改字典中“k1”对应的值为“alex”,输出修改后的字典
dic['k1'] ='alex'
print(dic)
# f.请在k3对应的值中追加一个元素44,输出修改后的字典
dic['k3'].append(44)
print(dic)
# g.请在k3对应的值的第1个位置插入个元素18,输出修改后的字典
dic['k3'].insert(0,18)
print(dic)
python闯关之路一(语法基础)的更多相关文章
- python 闯关之路四(下)(并发编程与数据库编程) 并发编程重点
python 闯关之路四(下)(并发编程与数据库编程) 并发编程重点: 1 2 3 4 5 6 7 并发编程:线程.进程.队列.IO多路模型 操作系统工作原理介绍.线程.进程演化史.特点.区别 ...
- python 闯关之路一(语法基础)
1,什么是编程?为什么要编程? 答:编程是个动词,编程就等于写代码,那么写代码是为了什么呢?也就是为什么要编程呢,肯定是为了让计算机帮我们搞事情,代码就是计算机能理解的语言. 2,编程语言进化史是什么 ...
- python 闯关之路四(上)(并发编程与数据库理论)
并发编程重点: 并发编程:线程.进程.队列.IO多路模型 操作系统工作原理介绍.线程.进程演化史.特点.区别.互斥锁.信号. 事件.join.GIL.进程间通信.管道.队列. 生产者消息者模型.异步模 ...
- python 闯关之路三(面向对象与网络编程)
1,简述socket 通信原理 如上图,socket通信建立在应用层与TCP/IP协议组通信(运输层)的中间软件抽象层,它是一组接口,在设计模式中,socket其实就是一个门面模式,它把复杂的TCP/ ...
- python 闯关之路四(下)(并发编程与数据库编程)
并发编程重点: 并发编程:线程.进程.队列.IO多路模型 操作系统工作原理介绍.线程.进程演化史.特点.区别.互斥锁.信号. 事件.join.GIL.进程间通信.管道.队列. 生产者消息者模型.异步模 ...
- python闯关之路(五)前端开发
一,HTML部分 1,XHTML和HTML有什么区别 HTML是一种基本的WEB网页设计语言,XHTML是一个基于XML的置标语言最主要的不同: XHTML 元素必须被正确地嵌套. XHTML 元素必 ...
- python 闯关之路二(模块的应用)
1.有如下字符串:n = "路飞学城"(编程题) - 将字符串转换成utf-8的字符编码的字节,再将转换的字节重新转换为utf-8的字符编码的字符串 - 将字符串转换成gbk的字符 ...
- python闯关之路二(模块的应用)
1.有如下字符串:n = "路飞学城"(编程题) - 将字符串转换成utf-8的字符编码的字节,再将转换的字节重新转换为utf-8的字符编码的字符串 - 将字符串转换成gbk的字符 ...
- C#设计模式开启闯关之路
前言背景 这是一条望不到尽头的编程之路,自踏入编程之路开始.就面临着各式各样的挑战,而我们也需要不断的挑战自己.不断学习充实自己.打好坚实的基础.以使我们可以走的更远.刚踏入编程的时候.根据需求编程, ...
随机推荐
- .NTE Core Web API Example
Source from :https://www.codeproject.com/Articles/1260600/Speed-up-ASP-NET-Core-WEB-API-application- ...
- python 变量的赋值【内存地址】
注意: python所有的数据都是对象,变量只是指向一个对象的地址,一旦将变量的值或者类型改变,变量指向的地址就有可能发生变化 这个特性在使用默认参数的时候一定要注意
- 8.10-Day2T1最小值
题目大意 裴蜀定理 题解 很简单... 我这个蒟蒻都猜的出来... 就求所有数的最大公约数 但注意 要加绝对值 因为gcd里面不能传负数 #include<cstdio> #inc ...
- ubuntu16.04修改复制粘贴快捷键的方法
打开终端-选择配置文件首选项 打开,选择快捷键,自行修改
- bugku 矛盾 30
首先打开网址链接会发现一串代码 然后进行分析代码的意思首先是一个函数查一下这个函数 然后会发现现代码第一句写的是输入数字,然后会发现第二行有一个感叹号意思是输入的如果不是数字则回复数字 如果输入数字则 ...
- sqli-libs(32-37(宽字节注入)关)
补充知识:宽字节注入 定义:GB2312.GBK.GB18030.BIG5.Shift_JIS等这些都是常说的宽字节,实际上只有两字节.宽字节带来的安全问题主要是吃ASCII字符(一字节)的现象,即将 ...
- 其他 - markdown 常用语法
1. 概述 简述 markdown 相关的标记 2. markdown markdown 概述 简单的标记语言 用作快速排版 使用 使用标记对文章样式进行描述 通过专门的引擎读取, 可以展示简单的样式 ...
- jquery 相同ID 绑定事件
本文链接:https://blog.csdn.net/lan_13217/article/details/84079441 http://hi.baidu.com/meneye/blog/item/1 ...
- dbGet(三)
inst flat design下的instance Parent Object group, hInst, instTerm, io, pBlkg, ptn, rBlkg, sdp, topCell ...
- December 31st, Week 53rd Tuesday, 2019
Nothing comes from nothing. 天下没有免费的午餐. Nothing comes from nothing, and in some cases, even something ...