数据源管理 | 基于DataX组件,同步数据和源码分析
本文源码:GitHub·点这里 || GitEE·点这里
一、DataX工具简介
1、设计理念
DataX是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。解决异构数据源同步问题,DataX将复杂的网状的同步链路变成了星型数据链路,DataX作为中间传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要将此数据源对接到DataX,便能跟已有的数据源做到无缝数据同步。
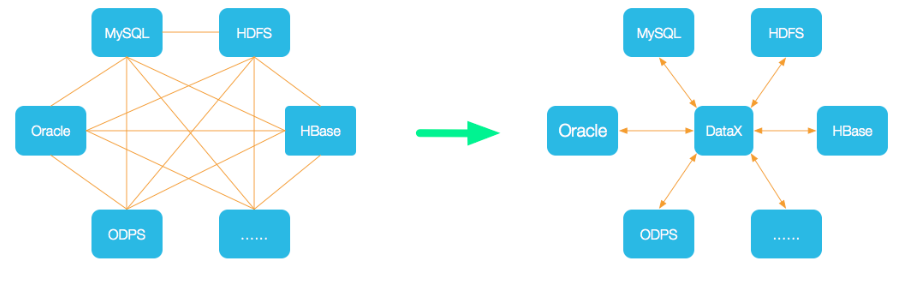
絮叨一句:异构数据源指,为了处理不同种类的业务,使用不同的数据库系统存储数据。
2、组件结构
DataX本身作为离线数据同步框架,采用Framework+plugin架构构建。将数据源读取和写入抽象成为Reader和Writer插件,纳入到整个同步框架中。

- Reader
Reader为数据采集模块,负责读取采集数据源的数据,将数据发送给Framework。
- Writer
Writer为数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。
- Framework
Framework用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。
3、架构设计

- Job
DataX完成单个数据同步的作业,称为Job,DataX接受到一个Job之后,将启动一个进程来完成整个作业同步过程。Job模块是单个作业的中枢管理节点,承担了数据清理、子任务切分(将单一作业计算转化为多个子Task)、TaskGroup管理等功能。
- Split
DataXJob启动后,会根据不同的源端切分策略,将Job切分成多个小的Task(子任务),以便于并发执行。Task便是DataX作业的最小单元,每一个Task都会负责一部分数据的同步工作。
- Scheduler
切分多个Task之后,Job会调用Scheduler模块,根据配置的并发数据量,将拆分成的Task重新组合,组装成TaskGroup(任务组)。
- TaskGroup
每一个TaskGroup负责以一定的并发运行完毕分配好的所有Task,默认单个任务组的并发数量为5。每一个Task都由TaskGroup负责启动,Task启动后,会固定启动Reader—>Channel—>Writer的线程来完成任务同步工作。DataX作业运行起来之后,Job监控并等待多个TaskGroup模块任务完成,等待所有TaskGroup任务完成后Job成功退出。否则,异常退出,进程退出值非0。
二、环境安装
推荐Python2.6+,Jdk1.8+(脑补安装流程)。
1、Python包下载
# yum -y install wget
# wget https://www.python.org/ftp/python/2.7.15/Python-2.7.15.tgz
# tar -zxvf Python-2.7.15.tgz
2、安装Python
# yum install gcc openssl-devel bzip2-devel
[root@ctvm01 Python-2.7.15]# ./configure --enable-optimizations
# make altinstall
# python -V
3、DataX安装
# pwd
/opt/module
# ll
datax
# cd /opt/module/datax/bin
-- 测试环境是否正确
# python datax.py /opt/module/datax/job/job.json
三、同步任务
1、同步表创建
-- PostgreSQL
CREATE TABLE sync_user (
id INT NOT NULL,
user_name VARCHAR (32) NOT NULL,
user_age int4 NOT NULL,
CONSTRAINT "sync_user_pkey" PRIMARY KEY ("id")
);
CREATE TABLE data_user (
id INT NOT NULL,
user_name VARCHAR (32) NOT NULL,
user_age int4 NOT NULL,
CONSTRAINT "sync_user_pkey" PRIMARY KEY ("id")
);
2、编写任务脚本
[root@ctvm01 job]# pwd
/opt/module/datax/job
[root@ctvm01 job]# vim postgresql_job.json
3、脚本内容
{
"job": {
"setting": {
"speed": {
"channel": "3"
}
},
"content": [
{
"reader": {
"name": "postgresqlreader",
"parameter": {
"username": "root01",
"password": "123456",
"column": ["id","user_name","user_age"],
"connection": [
{
"jdbcUrl": ["jdbc:postgresql://192.168.72.131:5432/db_01"],
"table": ["data_user"]
}
]
}
},
"writer": {
"name": "postgresqlwriter",
"parameter": {
"username": "root01",
"password": "123456",
"column": ["id","user_name","user_age"],
"connection": [
{
"jdbcUrl": "jdbc:postgresql://192.168.72.131:5432/db_01",
"table": ["sync_user"]
}
],
"postSql": [],
"preSql": []
}
}
}
]
}
}
4、执行脚本
# /opt/module/datax/bin/datax.py /opt/module/datax/job/postgresql_job.json
5、执行日志
2020-04-23 18:25:33.404 [job-0] INFO JobContainer -
任务启动时刻 : 2020-04-23 18:25:22
任务结束时刻 : 2020-04-23 18:25:33
任务总计耗时 : 10s
任务平均流量 : 1B/s
记录写入速度 : 0rec/s
读出记录总数 : 2
读写失败总数 : 0
四、源码流程分析
注意:这里源码只贴出核心流程,如果要看完整源码,可以自行从Git上下载。
1、读取数据
核心入口:PostgresqlReader
启动读任务
public static class Task extends Reader.Task {
@Override
public void startRead(RecordSender recordSender) {
int fetchSize = this.readerSliceConfig.getInt(com.alibaba.datax.plugin.rdbms.reader.Constant.FETCH_SIZE);
this.commonRdbmsReaderSlave.startRead(this.readerSliceConfig, recordSender,
super.getTaskPluginCollector(), fetchSize);
}
}
读取任务启动之后,执行读取数据操作。
核心类:CommonRdbmsReader
public void startRead(Configuration readerSliceConfig,
RecordSender recordSender,
TaskPluginCollector taskPluginCollector, int fetchSize) {
ResultSet rs = null;
try {
// 数据读取
rs = DBUtil.query(conn, querySql, fetchSize);
queryPerfRecord.end();
ResultSetMetaData metaData = rs.getMetaData();
columnNumber = metaData.getColumnCount();
PerfRecord allResultPerfRecord = new PerfRecord(taskGroupId, taskId, PerfRecord.PHASE.RESULT_NEXT_ALL);
allResultPerfRecord.start();
long rsNextUsedTime = 0;
long lastTime = System.nanoTime();
// 数据传输至交换区
while (rs.next()) {
rsNextUsedTime += (System.nanoTime() - lastTime);
this.transportOneRecord(recordSender, rs,metaData, columnNumber, mandatoryEncoding, taskPluginCollector);
lastTime = System.nanoTime();
}
allResultPerfRecord.end(rsNextUsedTime);
}catch (Exception e) {
throw RdbmsException.asQueryException(this.dataBaseType, e, querySql, table, username);
} finally {
DBUtil.closeDBResources(null, conn);
}
}
2、数据传输
核心接口:RecordSender(发送)
public interface RecordSender {
public Record createRecord();
public void sendToWriter(Record record);
public void flush();
public void terminate();
public void shutdown();
}
核心接口:RecordReceiver(接收)
public interface RecordReceiver {
public Record getFromReader();
public void shutdown();
}
核心类:BufferedRecordExchanger
class BufferedRecordExchanger implements RecordSender, RecordReceiver
3、写入数据
核心入口:PostgresqlWriter
启动写任务
public static class Task extends Writer.Task {
public void startWrite(RecordReceiver recordReceiver) {
this.commonRdbmsWriterSlave.startWrite(recordReceiver, this.writerSliceConfig, super.getTaskPluginCollector());
}
}
写数据任务启动之后,执行数据写入操作。
核心类:CommonRdbmsWriter
public void startWriteWithConnection(RecordReceiver recordReceiver,
Connection connection) {
// 写数据库的SQL语句
calcWriteRecordSql();
List<Record> writeBuffer = new ArrayList<>(this.batchSize);
int bufferBytes = 0;
try {
Record record;
while ((record = recordReceiver.getFromReader()) != null) {
writeBuffer.add(record);
bufferBytes += record.getMemorySize();
if (writeBuffer.size() >= batchSize || bufferBytes >= batchByteSize) {
doBatchInsert(connection, writeBuffer);
writeBuffer.clear();
bufferBytes = 0;
}
}
if (!writeBuffer.isEmpty()) {
doBatchInsert(connection, writeBuffer);
writeBuffer.clear();
bufferBytes = 0;
}
} catch (Exception e) {
throw DataXException.asDataXException(
DBUtilErrorCode.WRITE_DATA_ERROR, e);
} finally {
writeBuffer.clear();
bufferBytes = 0;
DBUtil.closeDBResources(null, null, connection);
}
}
五、源代码地址
GitHub·地址
https://github.com/cicadasmile/data-manage-parent
GitEE·地址
https://gitee.com/cicadasmile/data-manage-parent

推荐系列阅读
数据源管理 | 基于DataX组件,同步数据和源码分析的更多相关文章
- Quartz学习--二 Hello Quartz! 和源码分析
Quartz学习--二 Hello Quartz! 和源码分析 三. Hello Quartz! 我会跟着 第一章 6.2 的图来 进行同步代码编写 简单入门示例: 创建一个新的java普通工程 ...
- Java并发编程(七)ConcurrentLinkedQueue的实现原理和源码分析
相关文章 Java并发编程(一)线程定义.状态和属性 Java并发编程(二)同步 Java并发编程(三)volatile域 Java并发编程(四)Java内存模型 Java并发编程(五)Concurr ...
- Okhttp同步请求源码分析
进阶android,OKhttp源码分析——同步请求的源码分析 OKhttp是我们经常用到的框架,作为开发者们,我们不单单要学会灵活使用,还要知道他的源码是如何设计的. 今天我们来分析一下OKhttp ...
- Android Debuggerd 简要介绍和源码分析(转载)
转载: http://dylangao.com/2014/05/16/android-debuggerd-%E7%AE%80%E8%A6%81%E4%BB%8B%E7%BB%8D%E5%92%8C%E ...
- Kubernetes Job Controller 原理和源码分析(一)
概述什么是 JobJob 入门示例Job 的 specPod Template并发问题其他属性 概述 Job 是主要的 Kubernetes 原生 Workload 资源之一,是在 Kubernete ...
- Kubernetes Job Controller 原理和源码分析(二)
概述程序入口Job controller 的创建Controller 对象NewController()podControlEventHandlerJob AddFunc DeleteFuncJob ...
- Kubernetes Job Controller 原理和源码分析(三)
概述Job controller 的启动processNextWorkItem()核心调谐逻辑入口 - syncJob()Pod 数量管理 - manageJob()小结 概述 源码版本:kubern ...
- OLAP引擎:基于Druid组件进行数据统计分析
一.Druid概述 1.Druid简介 Druid是一款基于分布式架构的OLAP引擎,支持数据写入.低延时.高性能的数据分析,具有优秀的数据聚合能力与实时查询能力.在大数据分析.实时计算.监控等领域都 ...
- 数据源管理 | 基于JDBC模式,适配和管理动态数据源
本文源码:GitHub·点这里 || GitEE·点这里 一.关系型数据源 1.动态数据源 动态管理数据源的基本功能:数据源加载,容器维护,持久化管理. 2.关系型数据库 不同厂商的关系型数据库,提供 ...
随机推荐
- 如何关闭php的所有错误提示
在调试PHP 应用程序时,应当知道两个配置变量.下面是这两个变量及其默认值:display_errors = Offerror_reporting = E_ALL E_ALL能从不良编码实践到无害提示 ...
- coding++:漫画版-了解什么是分布式事务?
————— 第二天 ————— ———————————— 假如没有分布式事务: 在一系列微服务系统当中,假如不存在分布式事务,会发生什么呢?让我们以互联网中常用的交易业务为例子: 上图中包含了库存 ...
- Go语言 命令行解析(一)
命令行启动服务的方式,在后端使用非常广泛,如果有写过C语言的同学相信不难理解这一点!在C语言中,我们可以根据argc和argv来获取和解析命令行的参数,从而通过不同的参数调取不同的方法,同时也可以用U ...
- Linux C++ 网络编程学习系列(6)——多路IO之epoll高级用法
poll实现多路IO 源码地址:https://github.com/whuwzp/linuxc/tree/master/epoll_libevent 源码说明: server.cpp: 监听127. ...
- AJ学IOS(51)多线程网络之GCD下载合并图片_队列组的使用
AJ分享,必须精品 合并图片(图片水印)第一种方法 效果 实现: 思路: 1.分别下载2张图片:大图片.LOGO 2.合并2张图片 3.显示到一个imageView身上 // 异步下载 dispatc ...
- 食物链 POJ - 1182 (并查集的两种写法)
这是一个非常经典的带权并查集,有两种写法. 1 边权并查集 规定一下,当x和y这条边的权值为0时,表示x和y是同类,当为1时,表示x吃y,当为2时,表示x被y吃. 一共有三种状态,如图,当A吃B,B吃 ...
- 教你如何入手用python实现简单爬虫微信公众号并下载视频
主要功能 如何简单爬虫微信公众号 获取信息:标题.摘要.封面.文章地址 自动批量下载公众号内的视频 一.获取公众号信息:标题.摘要.封面.文章URL 操作步骤: 1.先自己申请一个公众号 2.登录自己 ...
- 视频+图文 String类干货向总结
目录 一.字符串的介绍及视频讲解 二.字符串的两种创建方式 方法一:通过new创建 方法二:直接创建 三.字符串的长度获取:length()方法 四.使用 == 和equals()方法比较两个字符串 ...
- [PHP][thinkphp5] 学习二:路由、配置调用、常量定义调用
路由: 其实TP5就是一个集多家框架所长而成的,感觉失去了自己的特色!路由这块呢类似于laravel框架!废话不说直接上码! 路由配置,类似laravel,就在route.php文件里配置路由(文件所 ...
- 为什么选择python?
Why python? 那些最好的程序员不是为了得到更高的薪水或者得到公众的仰慕而编程,他们只是觉得这是一件有趣的事情. —— Linux 之父 Linux Torvalds 作为一个使用主义的学习者 ...