Spark存储管理(读书笔记)
Spark存储管理(读书笔记)
转载请注明出处:http://www.cnblogs.com/BYRans/
Spark的存储管理
RDD的存放和管理都是由Spark的存储管理模块实现和管理的。本文从架构和功能两个角度对Spark的存储管理模块进行介绍。
架构角度
从架构角度,存储管理模块主要分为以下两层:
- 通信层:存储管理模块采用的是主从结构来实现通信层,主节点和从节点之间传输控制信息、状态信息。
- 存储层:存储管理模块需要把数据存储到硬盘或者内存中,必要时还需要复制到远端,这些操作由存储层来实现和提供相应接口。
通信层消息传递
在存储管理模块的通信层,每个Executor上的BlockManager只负责管理其自身Executor所拥有的数据块原信息,而不会管理其他Executor上的数据块元信息;而Driver端的BlockManager拥有所有已注册的BlockManager信息和数据块元信息,因此Executor的BlockManager往往是通过向Driver发送信息来获得所需要的非本地数据的。
存储层架构
RDD是由不同的分区组成的,我们所进行的转换和执行操作都是在每一块独立的分区上各自进行的。而在存储管理模块内部,RDD又被视为由不同的数据块组成,对于RDD的存取是以数据块为单位的,本质上分区(partition)和数据块(block)是等价的,只是看待的角度不同。同时,在Spark存储管理模块中存取数据的最小单位是数据块,所有的操作都是以数据块为单位的。
数据块(Block)
前面章节已经提到:存储管理模块以数据块为单位进行数据管理,数据块是存储管理模块中最小的操作单位。在存储管理模块中管理着各种不同的数据块,这些数据块为Spark框架提供了不同的功能,Spark存储管理模块中所管理的几种主要数据块为:
- RDD数据块:用来存储所缓存的RDD数据。
- Shuffle数据块:用来存储持久化的Shuffle数据。
- 广播变量数据块:用来存储所存储的广播变量数据。
- 任务返回结果数据块:用来存储在存储管理模块内部的任务返回结果。通常情况下任务返回结果随任务一起通过Akka返回到Driver端。但是当任务返回结果很大时,会引起Akka帧溢出,这时的另一种方案是将返回结果以块的形式放入存储管理模块,然后在Driver端获取该数据块即可,因为存储管理模块内部数据块的传输是通过Socket连接的,因此就不会出现Akka帧溢出了。
- 流式数据块:只用在Spark Streaming中,用来存储所接收到的流式数据块。
从功能角度
从功能角度,存储管理模块可以分为以下两个主要部分:
- RDD缓存:整个存储管理模块主要的工作是作为RDD的缓存,包括基于内存和磁盘的缓存。
- Shuffle数据的持久化:Shuffle中间结果的数据也是交由存储管理模块进行管理的。Shuffle性能的好坏直接影响了Spark应用程序整体的性能,因此存储管理模块中对于Shuffle数据的处理有别于传统的RDD缓存。
RDD持久化
存储管理模块可以分为两大块,一是RDD的缓存,二是Shuffle数据的持久化。接下来将介绍存储管理模块如何从内存和磁盘两个方面对RDD进行缓存。
RDD分区和数据块的关系
对于RDD的各种操作,如转换操作、执行操作,我们将操作函数施行于RDD之上,而最终这些操作都将施行于每一个分区之上,因此可以这么说,在RDD上的所有运算都是基于分区的。而在存储管理模块内,我们所接触到的往往是数据块这个概念,在存储管理模块中对于数据的存取都是以数据块为单位进行的。分区是一个逻辑上的概念,而数据块是物理上的数据实体,我们操作的分区和数据块,它们两者之间有什么关系呢?本小节我们将介绍分区与数据块的关系。
在Spark中,分区和数据块是一一对应的,一个RDD中的一个分区对应着存储管理模块中的一个数据块,存储管理模块接触不到也并不关心RDD,它只关心数据块,对于数据块和分区之间的映射则是通过名称上的约定进行的。
这种名称上的约定是按如下方式建立的:Spark为每一个RDD在其内部维护了独立的ID号,同时,对于RDD的每一个分区也有一个独立的索引号,因此只要知道ID号和索引号我们就能找到RDD中的相应分区,也就是说“ID号+索引号”就能全局唯一地确定这个分区。这样以“ID号+索引号”作为块的名称就自然地建立起了分区和块的映射。
在显示调用调用函数缓存我们所需的RDD时,Spark在其内部就建立了RDD分区和数据块之间的映射,而当我们需要读取缓存的RDD时,根据上面所提到的映射关系,就能从存储管理模块中取得分区对应的数据块。下图展示了RDD分区与数据块之间的映射关系。
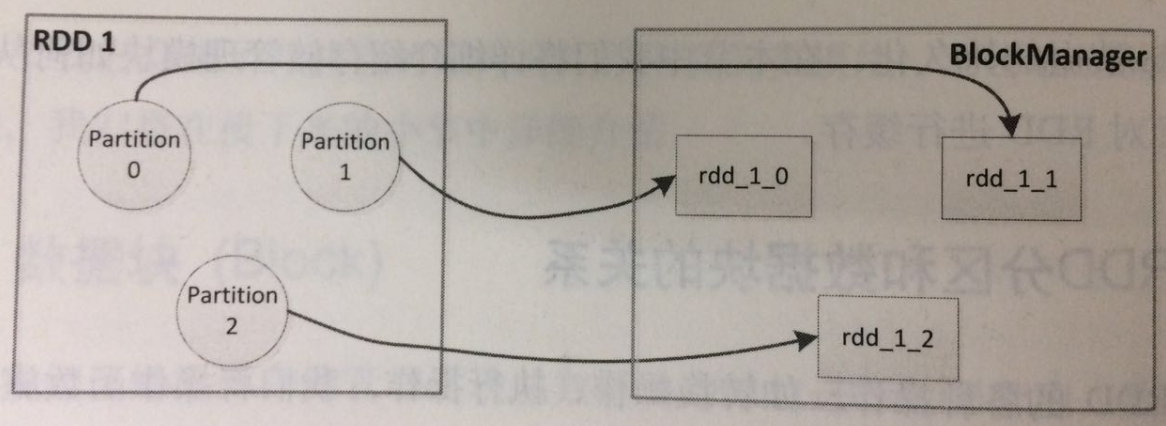
内部缓存
当以默认或者基于内存的持久化方式缓存RDD时,RDD中的每一分区所对应的数据块是会被存储管理模块中的内存缓存(Memory Store)所管理的。内存缓存在其内部维护了一个以数据块名为键,块内容为值的哈希表。
在内存缓存中有一个重要的问题是,当内存不是或是已经到达所设置的阈值时应如何处理。在Spark中对于内存缓存可使用的内存阈值有这样一个配置:spark.storage.memoryFraction。默认情况下是0.6,也就是说JVM内存的60%可被内存缓存用来存储块内容。当我们存储的数据块所占用的内存大于60%时,Spark会采取一些策略释放内存缓存空间:丢弃一些数据块,或是将一些数据块存储到磁盘上以释放内存缓存空间。是丢弃还是存储到磁盘上,依赖于进行操作的这些数据块的持久化选项,若持久化选项中包含了磁盘缓存,则会将这些块已入磁盘进行缓存,反之则直接删除。
那么直接删除是否会影响Spark程序的错误恢复机制呢?这取决于依赖关系的可回溯性,若该RDD所依赖的祖先RDD是可被回溯并可用的,那么该RDD所对应的块被删除是不会影响错误恢复的。反之,若该RDD已经是祖先RDD,且数据已无法被回溯到,那么程序就会出错。lost executor错误是不是就是这个原因?
从上面的介绍可以看出,内存缓存对于数据块的管理是非常简单的,本质上就是一个哈希表加上一些存取策略。
磁盘缓存
磁盘缓存管理数据块的方式为,首先,这些数据块会被存放到磁盘中的特定目录下。当我们配置spark.local.dir时,我们就配置了存储管理模块磁盘缓存存放数据的目录。磁盘缓存初始化时会在这些目录下创建Spark磁盘缓存文件夹,文件夹的命名方式是:spark-local-yyyyMMddHHmmss-xxxx,其中xxxx是一随机数。伺候所有的块内容都将存储到这些创建的目录中。
其次,在磁盘缓存中,一个数据块对应着文件系统中的一个文件,文件名和块名称的映射关系是通过哈希算法计算所得的。
总而言之,数据块对应的文件路径为:dirId/subDirId/block_id。这样我们就建立了块和文件之间的对应关系,而存取块内容就变成了写入和读取相应的文件了。
持久化选项
被缓存的数据块是可容错恢复的,若RDD的某一分区丢失,他会通过继承关系自动重新获得。
对于RDD的持久化,Spark为我们提供了不同的选项,使我们能将RDD持久化到内存、磁盘,或是以序列化的方式持久化到内存中,设置可以在集群的不同节点之间存储多份拷贝。所有这些不同的存储策略都是通过不同的持久化选项来决定的。
Shuffle数据持久化
存储管理模块可以分为两大块,一是RDD的缓存,二是Shuffle数据的持久化。介绍完RDD缓存,接下来介绍Shuffle数据持久化。
下图为Spark中Shuffle操作的流程示意图
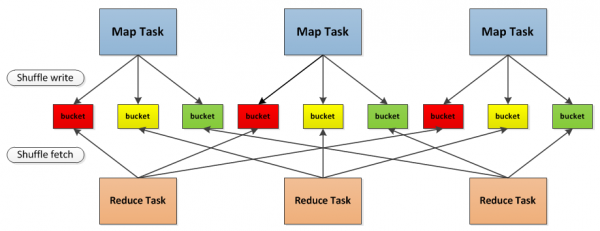
首先,每一个Map任务会根据Reduce任务的数据量创建出相应的桶,桶的数量是M*R,其中M是Map任务的个数,R是Reduce任务的个数。
其次,Map任务产生的结果会根据所设置的分区算法填充到每个桶中。这里的分区算法是可自定义的,当然默认的算法是根据键哈希到不同的桶中。
当Reduce任务启动时,它会根据自己任务的ID和所依赖的Map任务的ID从远端或本地的存储管理模块中取得相应的桶作为任务的输入进行处理。
Shuffle数据与RDD持久化的不同之处在于:
- Shuffle数据块必须是在磁盘上进行缓存的,而不能选择在内存中缓存;
- 在RDD基于磁盘的持久化中,每一个数据块对应着一个文件,而在Shuffle数据块持久化中,Shuffle数据块的存储有两种方式:
- 一种是将Shuffle数据块映射成文件,这是默认的方式;
- 另一种是将Shuffle数据块映射成文件中的一段,这种方式需要将spark.shuffle.consolidateFiles设置为true。
默认的方式会产生大量的文件,如1000个Map任务和1000个Reduce任务,会产生1000000个Shuffle文件,这会对磁盘和文件系统的性能造成极大的影响,因此有了第二种是实现方式,将分时运行的Map任务所产生的Shuffle数据块合并到同一个文件中,以减少Shuffle文件的总数。对于第二种存储方式,示意图如下:
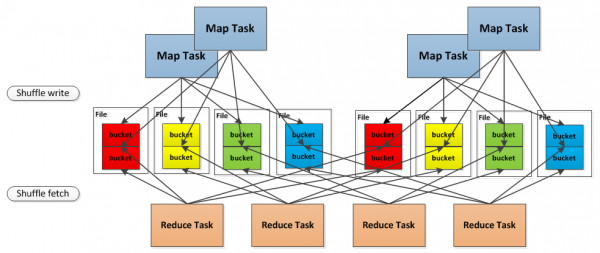
前面介绍了Shuffle数据块的存取,下面我们来介绍Shuffle数据块的读取和传输。Shuffle是将一组任务的输出结果重新组合作为下一组任务的输入这样的一个过程,由于任务分布在不同的节点上,因此为了将重组结果作为输入,必然涉及Shuffle数据的读取和传输。
在Spark存储管理模块中,Shuffle数据的读取和传输有两种方式:
- 一种是基于NIO以socket连接去获取数据;
- 另一种是基于OIO通过Netty服务端获取数据。
前者是默认的获取方式,通过配置spark.shuffle.use.netty为true,可以启用第二种获取方式。之所以有两种Shuffle数据的获取方式,是因为默认的方式在一些情况下无法充分利用网络带宽,用户可以通过比较两种方式在性能上的差异来自行决定选用哪种Shuffle数据获取方式。
总的来说,Spark存储管理模块为Shuffle数据的持久化做了许多有别于RDD持久化的工作,包括存取Shuffle数据块的方式,以及读取和传输Shuffle数据块的方式,所有这些实现都是为了使Shuffle获得更好的性能和容错。
Spark存储管理(读书笔记)的更多相关文章
- Spark机器学习读书笔记-CH05
5.2.从数据中提取合适的特征 [root@demo1 ch05]# sed 1d train.tsv > train_noheader.tsv[root@demo1 ch05]# lltota ...
- Spark机器学习读书笔记-CH04
[root@demo1 ch04]# spark-shell --master yarn --jars /root/studio/jblas-1.2.3.jar scala> val rawDa ...
- Spark机器学习读书笔记-CH03
3.1.获取数据: wget http://files.grouplens.org/datasets/movielens/ml-100k.zip 3.2.探索与可视化数据: In [3]: user_ ...
- Spark调度管理(读书笔记)
Spark调度管理(读书笔记) 转载请注明出处:http://www.cnblogs.com/BYRans/ Spark调度管理 本文主要介绍在单个任务内Spark的调度管理,Spark调度相关概念如 ...
- HDFS Federation (读书笔记)
HDFS Federation (读书笔记) HDFS的架构 HDFS包含两个层次:命名空间管理(Namespace) 和 块/存储管理(Block Storage). 命名空间管理(Namespac ...
- 【Todo】【读书笔记】机器学习-周志华
书籍位置: /Users/baidu/Documents/Data/Interview/机器学习-数据挖掘/<机器学习_周志华.pdf> 一共442页.能不能这个周末先囫囵吞枣看完呢.哈哈 ...
- 《Apache Kafka 实战》读书笔记-认识Apache Kafka
<Apache Kafka 实战>读书笔记-认识Apache Kafka 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.kafka概要设计 kafka在设计初衷就是 ...
- 《深入理解Android2》读书笔记(一)
2017-5-12 从今天开始估计有一段空闲时间,开始阅读<深入理解Android2>,并写读书笔记. 第一章搭建环境直接略过. 第二章是Binder,暂时略过 7大类服务包括:1.And ...
- 第一章-Flink介绍-《Fink原理、实战与性能优化》读书笔记
Flink介绍-<Fink原理.实战与性能优化>读书笔记 1.1 Apache Flink是什么? 在当代数据量激增的时代,各种业务场景都有大量的业务数据产生,对于这些不断产生的数据应该如 ...
随机推荐
- 表单多文件上传样式美化 && 支持选中文件后删除相关项
开发中会经常涉及到文件上传的需求,根据业务不同的需求,有不同的文件上传情况. 有简单的单文件上传,有多文件上传,因浏览器原生的文件上传样式及功能的支持度不算太高,很多时候我们会对样式进行美化,对功能进 ...
- MySQL一个语句查出各种整形占用字节数及最大最小值
直接上码: as min_num union , union , union , union , union ,) union ,) union ,) union ,) union ,); +---- ...
- js的stopPropagation()、cancelBubble、preventDefault()、return false的分析
个人笔记,如有错误,望指出. 事件冒泡,举个列子: <li> <a href='http://www.baidu.com'>点击a</a> </li> ...
- 7.5 数据注解特性--MaxLength&&MinLength
MaxLength attribute can be applied to a string or array type property of a domain class. EF Code Fir ...
- C++ this指针的用法
this指针的含义及其用法: 1. this指针是一个隐含于每一个成员函数中的特殊指针.它指向正在被该成员函数操作的那个对象.2. 当对一个对象调用成员函数时,编译程序先将对象的地址赋给this指针, ...
- ASP.NET MVC入门之再不学习就真的out了
听说最近又出了什么SAM,MVC辉煌即将过去,惊了我一身冷汗,ASP.NET MVC是啥都还没搞明白呢 于是赶紧打开ASP.NET官网学习学习,欢迎各位高手大侠来指点指点
- ASP.NET Core 开发-中间件(Middleware)
ASP.NET Core开发,开发并使用中间件(Middleware). 中间件是被组装成一个应用程序管道来处理请求和响应的软件组件. 每个组件选择是否传递给管道中的下一个组件的请求,并能之前和下一组 ...
- jQuery获取及设置单选框、多选框、文本框内容
获取一组radio被选中项的值 var item = $('input[@name=items][@checked]').val(); 获取select被选中项的文本 var item = $(&qu ...
- DDD心得
使用DDD分层架构有哪些好处 帮你更集中的管理业务逻辑. 帮你降低各层间,以及各业务模块间的依赖关系. 帮你更方便的进行单元测试. 我的DDD分层架构使用经验 使用充血模型,将业务逻辑尽量放到领域实体 ...
- adb命令
一下是记录一些日常经常用的adb command, adb root: adb shell -> su -> return -> adb root(首先让安卓设备获得root权限,然 ...