NonRegisteringDriver造成的内存频繁FullGc

某天上服务器看了下gc情况,发现状况不对,启动了才2天的服务器发生了360次fullgc,这个频率肯定高了
说明
S0C、S1C、S0U、S1U:Survivor 0/1区容量(Capacity)和使用量(Used)
EC、EU:Eden区容量和使用量
OC、OU:年老代容量和使用量
PC、PU:永久代容量和使用量
YGC、YGT:年轻代GC次数和GC耗时
FGC、FGCT:Full GC次数和Full GC耗时
GCT:GC总耗时<br><br>
jmap下载下内存看下
jmap -dump:format=b,file=文件名 [pid]
用eclipse的mat工具打开,很明显的就能发现NonRegisteringDriver里的ConcurrentHashMap占用了大量内存
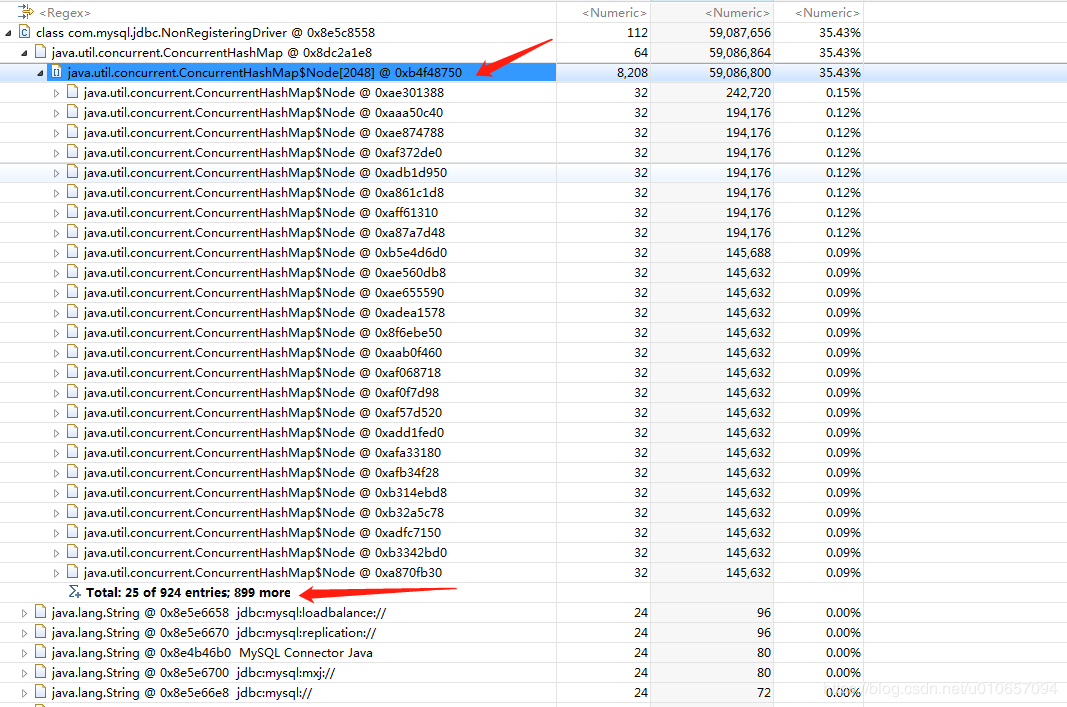
去NonRegisteringDriver的源码看看,发现该类只有一个ConcurrentHashMap,也就是connectionPhantomRefs,里面存放了ConnectionImpl的虚引用

继续往下找,发现在这个位置会放入该map

看下调用链路,猜测是获取数据库链接的时候丢了个jdbcConnection的虚引用进这个map
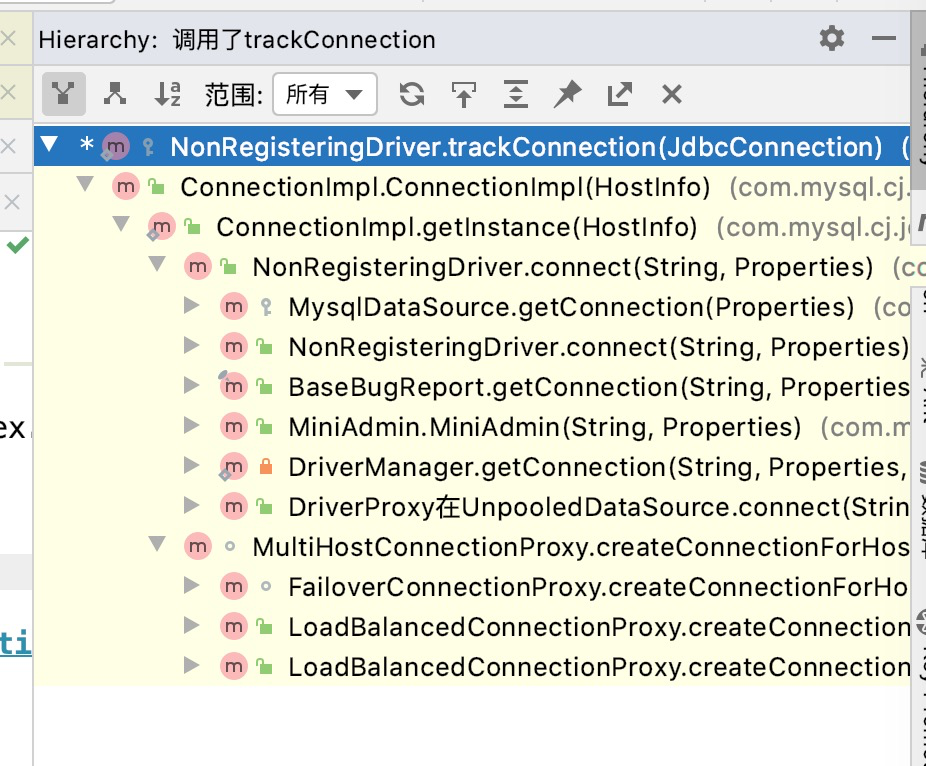
继续找找看看这个存放了虚引用的map在哪会被使用,发现 AbandonedConnectionCleanupThread里起了个线程去遍历虚引用的队列,在虚引用被回收后会进入这个队列,在这边获取后进行链接的cleanup操作

至此已经清楚ConnectionPhantomReference的作用就是在gc回收之后,能让代码从队列里获取实例再进行相关资源的回收
那么问题来了:
1:为什么会造成那么频繁的fullgc
2:connectionPhantomRefs这个map的作用是什么
1.1:java的堆内存对象的ygc次数过多后将会进入老年代
一、对象何时进入老年代
(1)当对象首次创建时, 会放在新生代的eden区, 若没有GC的介入,会一直在eden区, GC后,是可能进入survivor区或者年老代 (2)当对象年龄达到一定的大小 ,就会离开年轻代, 进入老年代。 而对象的年龄是由GC的次数决定的 -XX:MaxTenuringThreshold=n 新生代的对象最多经历n次GC, 就能晋升到老年代, 但不是必要条件 -XX:TargetSurvivorRatio=n 用于设置Survivor区的目标使用率,即当survivor区GC后使用率超过这个值, 就可能会使用较小的年龄作为晋升年龄 (3)除年龄外, 对象体积也会影响对象的晋升的, 若对象体积太大, 新生代无法容纳这个对象 -XX:PretenureSizeThreshold 即对象的大小大于此值, 就会绕过新生代, 直接在老年代分配, 此参数只对串行回收器以及ParNew回收有效, 而对ParallelGC回收器无效
1.2:代码使用的为HikariCP连接池,而HikariCP有几个参数
idleTimeout (连接空闲超时时间,默认 10 分钟)
maxLifetime(连接最大生存时间,默认 30 分钟)
maxPoolSize (连接池最大连接数)
minIdle(最小空闲连接数,默认等于 maxPoolSize)
可以看出当数据库连接空闲时间超过了 idleTimeout,那么将会关闭,直到数量为 minIdle。还有当数据库连接存活时间达到了 maxLifetime ,那么连接也会关闭,然后再创建新的连接,而每次创建新的连接都将重复上述步骤
1.3:而我的系统默认配置了500个连接数(minIdle=maxPoolSize=500),而查看阿里云的监控可以得知活跃的连接数基本就十几个,导致jdbc连接疯狂的在关闭打开,而在30分钟之内经过多次ygc之后,ConnectionImpl都进入了老年代,而老年代的gc间隔很长,就导致connectionPhantomRefs里堆积了一大堆虚引用的对象,而触发一次gc后会释放
2:为了验证这个map的作用,我建了个类
public class Test {
public static ReferenceQueue<Object> refQueue = new ReferenceQueue<Object>();
public static Map<PhantomReference, PhantomReference> map = new HashMap<>();
public PhantomReference<Object> phanRef;
public void test() throws InterruptedException {
Object obj = new Object();
phanRef = new PhantomReference<Object>(obj, refQueue);
// map.put(phanRef, phanRef);
}
}
然后在另外一个类里面执行以下方法
public static void main(String[] args) throws InterruptedException {
Test test = new Test();
test.test();
//PhantomReference<Object> s = drugTest.phanRef;
//System.out.println(s);
test = null;
System.gc();
System.gc();
System.gc();
System.out.println(test.refQueue.poll());
//System.out.println(s);
//s = null;
System.out.println(test.refQueue.poll());
}
当map.put(phanRef, phanRef);这行代码被注释时,输出
null
null
当map.put(phanRef, phanRef);这行代码存在时,输出
null
java.lang.ref.PhantomReference@4d591d15
当map.put(phanRef, phanRef);这行代码存在时,并且取消PhantomReference<Object> s = drugTest.phanRef; s = null;的注释时输出
null
java.lang.ref.PhantomReference@4d591d15
从这个实验可以看出,当phanRef没有被其他地方引用时,当他所属的实例类被回收后他并不会进入到弱引用的队列中(可能和gc机制有关吧)
解决方案:
1:调整HikariCP连接池的参数
2:调整jvm堆内存的参数
3:手动删除connectionPhantomRefs这个ConcurrentHashMap中的数据
4:手动调system.gc(我觉得这个方法很扯淡,手动掉还不如让jvm自己判断调呢,反正不会内存溢出)
附上调整后的参数
https://www.cnblogs.com/MRLL/p/12721295.html
参考文章
https://www.jianshu.com/p/6d37afd1f072
https://www.cnblogs.com/newcj/archive/2011/05/15/2046882.html
https://www.cnblogs.com/yaowen/p/10975241.html
https://blog.csdn.net/u010657094/article/details/104042326/
NonRegisteringDriver造成的内存频繁FullGc的更多相关文章
- 记一次内存无法回收导致频繁fullgc机器假死的思路
确定挂机 络绎不绝的来不同类型的bug 当bug滚滚而来时,不要怀疑,你的发布的应用基本是不可用状态了.观察哨兵监控数据,特别是内存打到80%基本就挂机了,或者监控数据缺失也基本是挂机了.此时应当马上 ...
- 关于GC(上):Apache的POI组件导致线上频繁FullGC问题排查及处理全过程
某线上应用在进行查询结果导出Excel时,大概率出现持续的FullGC.解决这个问题时,记录了一下整个的流程,也可以作为一般性的FullGC问题排查指导. 1. 生成dump文件 为了定位FullGC ...
- 一次性搞清楚线上CPU100%,频繁FullGC排查套路
“ 处理过线上问题的同学基本上都会遇到系统突然运行缓慢,CPU 100%,以及 Full GC 次数过多的问题. 当然,这些问题最终导致的直观现象就是系统运行缓慢,并且有大量的报警. 本文主要针对系统 ...
- 一次压测中tomcat生成session释放不及时导致的频繁fullgc性能优化案例
性能问题:老年代一直处于占满状态,为什么没有发生内存溢出 以HotSpot VM的分代式GC为例,普通对象分配都是在young gen进行的,具体是从在位于young gen中的eden space中 ...
- 服务器CPU很高,频繁FullGC排查小总结
可以分为如下步骤: ①通过 top 命令查看 CPU 情况,如果 CPU 比较高,则通过 top -Hp 命令查看当前进程的各个线程运行情况. 找出 CPU 过高的线程之后,将其线程 id 转换为十六 ...
- 记一次线上频繁fullGc的排查解决过程
发生背景 最近上线的一个项目几乎全是查询业务,并且都是大表的慢查询,sql优化是做了一轮又一轮,前几天用户反馈页面加载过慢还时不时的会timeout,但是我们把对应的sql都优化一遍过后,前台响应还是 ...
- JDBC驱动自身问题引发的FullGC
公众号HelloJava刊出一篇<MySQL Statement cancellation timer 故障排查分享>,作者的某服务的线上机器报 502(502是 nginx 做后端健康检 ...
- Java堆内存
Java 中的堆是 JVM 所管理的最大的一块内存空间,主要用于存放各种类的实例对象. 在 Java 中,堆被划分成两个不同的区域:新生代 ( Young ).老年代 ( Old ).新生代 ( Yo ...
- jvm对大对象分配内存的特殊处理(转)
前段日子在和leader交流技术的时候,偶然听到jvm在分配内存空间给大对象时,如果young区空间不足会直接在old区切一块过去.对于这个结论很好奇,也比较怀疑,所以就上网搜了下,发现还真有这么回事 ...
随机推荐
- BigInteger实现除法取余
BigInteger实现除法取余 BigInteger是什么? Java中,整形的最大范围是64位的long型整数.但是如果我们使用的整数超过了64位呢?这时候就用到了BigInteger.BigIn ...
- Mybatis总结一之SQL标签方法
---恢复内容开始--- 定义:mapper.xml映射文件中定义了操作数据库的sql,并且提供了各种标签方法实现动态拼接sql.每个sql是一个statement,映射文件是mybatis的核心. ...
- [Alg] 文本匹配-单模匹配与多模匹配
实际场景: 网站的用户发了一些帖子S1, S2,...,网站就要审核一下这些帖子里有没有敏感词. 1. 如果网站想查一下帖子里有没有一个敏感词P,这个文本匹配要怎么做更快? 2. 如果网站想查一下帖子 ...
- 解决tinyint映射成boolean/byte的问题
前言 最近受疫情的影响,公司要做一个类似一码通的系统为客户服务.由我来进行表的设计.创建表之后需要逆向生成Java的entity.mapper.mapper.xml.由于我在数据库中定义了大量 tin ...
- [图中找环] Codeforces 659E New Reform
New Reform time limit per test 1 second memory limit per test 256 megabytes input standard input out ...
- [快速幂]Codeforces Round #576 (Div. 2)-C. MP3
C. MP3 time limit per test 1 second memory limit per test 256 megabytes input standard input output ...
- Python_matplotlib画图时图例说明(legend)放到图像外侧
https://blog.csdn.net/Poul_henry/article/details/82533569 import matplotlib.pyplot as plt import num ...
- Android菜单(menu)
Android 菜单 我们继续来进行学习,今天写一下在软件中用的还算较多的菜单. 1.Menu 菜单,很显然,作用就是点击不同的选项触发不同的方法.现在在安卓使用中推荐使用ActionBar,但这里 ...
- nltk 中的 sents 和 words
nltk 中的 sents 和 words ,为后续处理做准备. #!/usr/bin/env python # -*- coding: utf-8 -*- from nltk.corpus impo ...
- Linux常用命令 - find命令基础使用(重点)
1篇测试必备的Linux常用命令,每天敲一篇,每次敲三遍,每月一循环,全都可记住!! https://www.cnblogs.com/poloyy/category/1672457.html 首先,先 ...