第2节 storm实时看板案例:10、redis的安装使用回顾
2、redis的持久化机制:
redis支持两种持久化机制:RDB AOF
RDB:多少秒之内,有多少个key放生变化,将redis当中的数据dump到磁盘保存,保存成一个文件,下次再恢复的时候,首先读取文件当中的数据到内存来
AOF:日志文件的操作记录 记录了我们操作redis的所有的步骤
默认开启RDB,没有开启AOF,一般实现线上环境,都要开启AOF
如果开启了aof持久化机制,那么日志文件就会越写越大,如何控制日志文件不会膨胀太大:
rewrite 操作 每隔一段时间,合并日志当中的记录与redis数据库当中的数据
lpush + lpop :先进后出,栈模型。
==============================================
10.5 redis安装使用回顾
第一步:下载redis安装包
wget http://download.redis.io/releases/redis-3.2.8.tar.gz
第二步:解压redis压缩包到指定目录
tar -zxvf redis-3.2.8.tar.gz -C ../servers/
第三步:安装C程序运行环境
yum -y install gcc-c++
第四步:安装较新版本的tcl
下载tcl
解压tcl
tar -zxvf tcl8.6.1-src.tar.gz -C ../servers/
进入指定目录
cd ../servers/tcl8.6.1/unix/
执行./configure进行配置
./configure
make && make install
第二种方式,在线安装tcl
yum -y install tcl
第五步:进行编译redis
进行编译:
cd ../servers/redis-3.2.8/
make MALLOC=libc 或者仅使用命令 make 进行编译
make test && make install
第六步:修改redis配置文件
cd /export/servers/redis-3.2.8/
mkdir -p /export/servers/redis-3.2.8/logs
mkdir -p /export/servers/redis-3.2.8/redisdata
vim redis.conf
bind 192.168. 8.110
daemonize yes
pidfile /var/run/redis_6379.pid
logfile "/export/servers/redis-3.2.8/logs/redis.log"
dir /export/servers/redis-3.2.8/redisdata
requirepass redis #设置密码,不需要的话也可以不设置
第七步:启动redis
启动redis
cd /export/servers/redis-3.2.8
src/redis-server redis.conf
第八步:连接redis客户端
cd /export/servers/redis-3.2.8/src
redis-cli -h 192.168.8.110
redis-cli -h localhost -p 6379 monitor -a 123456 #连接时指定主机名、端口、密码
redis的持久化
第八步:如何配置redis RDB的持久化机制
修改redis的配置文件
重新启动redis服务
每次生成新的dump.rdb都会覆盖掉之前的老的快照
如果使用kill -9 来杀死redis进程,下次启动redis的时候,就会发现redis启动不了,提示还有pid文件,需要将redis的pid文件删除掉,然后再启动即可
cd /var/run
rm -rf redis_6379.pid
/etc/init.d/redis_6379 start
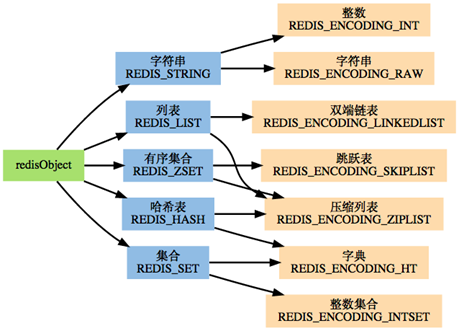
redis的数据类型:
redis当中一共支持五种数据类型,分别是string字符串类型,list列表类型,集合set类型,hash表类型以及有序集合zset类型,通过这五种不同的数据类型,我们可以实现各种不同的功能,也可以应用与各种不同的场景,接下来我们来看看五种数据类型的操作语法。
第九步:如何配置redis AOF的持久化机制
在redis中,aof的持久化机制默认是关闭的
AOF持久化,默认是关闭的,默认是打开RDB持久化
appendonly yes,可以打开AOF持久化机制,在生产环境里面,一般来说AOF都是要打开的,除非你说随便丢个几分钟的数据也无所谓
打开AOF持久化机制之后,redis每次接收到一条写命令,就会写入日志文件中,当然是先写入os cache的,然后每隔一定时间再fsync一下
而且即使AOF和RDB都开启了,redis重启的时候,也是优先通过AOF进行数据恢复的,因为aof数据比较完整
可以配置AOF的fsync策略,有三种策略可以选择,一种是每次写入一条数据就执行一次fsync; 一种是每隔一秒执行一次fsync; 一种是不主动执行fsync
always: 每次写入一条数据,立即将这个数据对应的写日志fsync到磁盘上去,性能非常非常差,吞吐量很低; 确保说redis里的数据一条都不丢,那就只能这样了
在redis当中默认的AOF持久化机制都是关闭的
配置redis的AOF持久化机制方式
Redis当中的rewrite操作
redis中的数据其实有限的,很多数据可能会自动过期,可能会被用户删除,可能会被redis用缓存清除的算法清理掉
redis中的数据会不断淘汰掉旧的,就一部分常用的数据会被自动保留在redis内存中
所以可能很多之前的已经被清理掉的数据,对应的写日志还停留在AOF中,AOF日志文件就一个,会不断的膨胀,到很大很大
所以AOF会自动在后台每隔一定时间做rewrite操作,比如日志里已经存放了针对100w数据的写日志了; redis内存只剩下10万; 基于内存中当前的10万
数据构建一套最新的日志,到AOF中; 覆盖之前的老日志; 确保AOF日志文件不会过大,保持跟redis内存数据量一致
redis 2.4之前,还需要手动,开发一些脚本,crontab,通过BGREWRITEAOF命令去执行AOF rewrite,但是redis 2.4之后,会自动进行rewrite操作
在redis.conf中,可以配置rewrite策略
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
比如说上一次AOF rewrite之后,是128mb
然后就会接着128mb继续写AOF的日志,如果发现增长的比例,超过了之前的100%,256mb,就可能会去触发一次rewrite
但是此时还要去跟min-size,64mb去比较,256mb > 64mb,才会去触发rewrite
(1)redis fork一个子进程
(2)子进程基于当前内存中的数据,构建日志,开始往一个新的临时的AOF文件中写入日志
(3)redis主进程,接收到client新的写操作之后,在内存中写入日志,同时新的日志也继续写入旧的AOF文件
(4)子进程写完新的日志文件之后,redis主进程将内存中的新日志再次追加到新的AOF文件中
(5)用新的日志文件替换掉旧的日志文件
第九步:redis的操作回顾
redis当中各种数据类型的操作: https://www.runoob.com/redis/redis-keys.html
String类型数据操作
redis 127.0.0.1:6379> exists mykey #判断该键是否存在,存在返回1,否则返回0。
(integer) 0
redis 127.0.0.1:6379> append mykey "hello" #该键并不存在,因此append命令返回当前Value的长度。
(integer) 5
redis 127.0.0.1:6379> append mykey " world" #该键已经存在,因此返回追加后Value的长度。
(integer) 11
redis 127.0.0.1:6379> get mykey #通过get命令获取该键,以判断append的结果。
"hello world"
redis 127.0.0.1:6379> set mykey "this is a test" #通过set命令为键设置新值,并覆盖原有值。
OK
redis 127.0.0.1:6379> get mykey
"this is a test"
redis 127.0.0.1:6379> strlen mykey #获取指定Key的字符长度,等效于C库中strlen函数。
(integer) 14
2. INCR/DECR/INCRBY/DECRBY:
redis 127.0.0.1:6379> set mykey 20 #设置Key的值为20
OK
redis 127.0.0.1:6379> incr mykey #该Key的值递增1
(integer) 21
redis 127.0.0.1:6379> decr mykey #该Key的值递减1
(integer) 20
redis 127.0.0.1:6379> del mykey #删除已有键。
(integer) 1
redis 127.0.0.1:6379> decr mykey #对空值执行递减操作,其原值被设定为0,递减后的值为-1
(integer) -1
redis 127.0.0.1:6379> del mykey
(integer) 1
redis 127.0.0.1:6379> incr mykey #对空值执行递增操作,其原值被设定为0,递增后的值为1
(integer) 1
redis 127.0.0.1:6379> set mykey hello #将该键的Value设置为不能转换为整型的普通字符串。
OK
redis 127.0.0.1:6379> incr mykey #在该键上再次执行递增操作时,Redis将报告错误信息。
(error) ERR value is not an integer or out of range
redis 127.0.0.1:6379> set mykey 10
OK
redis 127.0.0.1:6379> decrby mykey 5
(integer) 5
redis 127.0.0.1:6379> incrby mykey 10
(integer) 15
3. GETSET:
redis 127.0.0.1:6379> incr mycounter #将计数器的值原子性的递增1
(integer) 1
#在获取计数器原有值的同时,并将其设置为新值,这两个操作原子性的同时完成。
redis 127.0.0.1:6379> getset mycounter 0
"1"
redis 127.0.0.1:6379> get mycounter #查看设置后的结果。
"0"
4. SETEX:
redis 127.0.0.1:6379> setex mykey 10 "hello" #设置指定Key的过期时间为10秒。
OK
#通过ttl命令查看一下指定Key的剩余存活时间(秒数),0表示已经过期,-1表示永不过期。
redis 127.0.0.1:6379> ttl mykey
(integer) 4
redis 127.0.0.1:6379> get mykey #在该键的存活期内我们仍然可以获取到它的Value。
"hello"
redis 127.0.0.1:6379> ttl mykey #该ttl命令的返回值显示,该Key已经过期。
(integer) 0
redis 127.0.0.1:6379> get mykey #获取已过期的Key将返回nil。
(nil)
5. SETNX:
redis 127.0.0.1:6379> del mykey #删除该键,以便于下面的测试验证。
(integer) 1
redis 127.0.0.1:6379> setnx mykey "hello" #该键并不存在,因此该命令执行成功。
(integer) 1
redis 127.0.0.1:6379> setnx mykey "world" #该键已经存在,因此本次设置没有产生任何效果。
(integer) 0
redis 127.0.0.1:6379> get mykey #从结果可以看出,返回的值仍为第一次设置的值。
"hello"
6. SETRANGE/GETRANGE:
redis 127.0.0.1:6379> set mykey "hello world" #设定初始值。
OK
redis 127.0.0.1:6379> setrange mykey 6 dd #从第六个字节开始替换2个字节(dd只有2个字节)
(integer) 11
redis 127.0.0.1:6379> get mykey #查看替换后的值。
"hello ddrld"
redis 127.0.0.1:6379> setrange mykey 20 dd #offset已经超过该Key原有值的长度了,该命令将会在末尾补0。
(integer) 22
redis 127.0.0.1:6379> get mykey #查看补0后替换的结果。
"hello ddrld\x00\x00\x00\x00\x00\x00\x00\x00\x00dd"
redis 127.0.0.1:6379> del mykey #删除该Key。
(integer) 1
redis 127.0.0.1:6379> setrange mykey 2 dd #替换空值。
(integer) 4
redis 127.0.0.1:6379> get mykey #查看替换空值后的结果。
"\x00\x00dd"
redis 127.0.0.1:6379> set mykey "0123456789" #设置新值。
OK
redis 127.0.0.1:6379> getrange mykey 1 2 #截取该键的Value,从第一个字节开始,到第二个字节结束。
"12"
redis 127.0.0.1:6379> getrange mykey 1 20 #20已经超过Value的总长度,因此将截取第一个字节后面的所有字节。
"123456789"
7. SETBIT/GETBIT:
redis 127.0.0.1:6379> del mykey
(integer) 1
redis 127.0.0.1:6379> setbit mykey 7 1 #设置从0开始计算的第七位BIT值为1,返回原有BIT值0
(integer) 0
redis 127.0.0.1:6379> get mykey #获取设置的结果,二进制的0000 0001的十六进制值为0x01
"\x01"
redis 127.0.0.1:6379> setbit mykey 6 1 #设置从0开始计算的第六位BIT值为1,返回原有BIT值0
(integer) 0
redis 127.0.0.1:6379> get mykey #获取设置的结果,二进制的0000 0011的十六进制值为0x03
"\x03"
redis 127.0.0.1:6379> getbit mykey 6 #返回了指定Offset的BIT值。
(integer) 1
redis 127.0.0.1:6379> getbit mykey 10 #Offset已经超出了value的长度,因此返回0。
(integer) 0
8. MSET/MGET/MSETNX:
redis 127.0.0.1:6379> mset key1 "hello" key2 "world" #批量设置了key1和key2两个键。
OK
redis 127.0.0.1:6379> mget key1 key2 #批量获取了key1和key2两个键的值。
1) "hello"
2) "world"
#批量设置了key3和key4两个键,因为之前他们并不存在,所以该命令执行成功并返回1。
redis 127.0.0.1:6379> msetnx key3 "stephen" key4 "liu"
(integer) 1
redis 127.0.0.1:6379> mget key3 key4
1) "stephen"
2) "liu"
#批量设置了key3和key5两个键,但是key3已经存在,所以该命令执行失败并返回0。
redis 127.0.0.1:6379> msetnx key3 "hello" key5 "world"
(integer) 0
#批量获取key3和key5,由于key5没有设置成功,所以返回nil。
redis 127.0.0.1:6379> mget key3 key5
1) "stephen"
2) (nil)
List集合操作命令
1. LPUSH/LPUSHX/LRANGE:
/> redis-cli #在Shell提示符下启动redis客户端工具。
redis 127.0.0.1:6379> del mykey
(integer) 1
#mykey键并不存在,该命令会创建该键及与其关联的List,之后在将参数中的values从左到右依次插入。
redis 127.0.0.1:6379> lpush mykey a b c d
(integer) 4
#取从位置0开始到位置2结束的3个元素。
redis 127.0.0.1:6379> lrange mykey 0 2
1) "d"
2) "c"
3) "b"
#取链表中的全部元素,其中0表示第一个元素,-1表示最后一个元素。
redis 127.0.0.1:6379> lrange mykey 0 -1
1) "d"
2) "c"
3) "b"
4) "a"
#mykey2键此时并不存在,因此该命令将不会进行任何操作,其返回值为0。
redis 127.0.0.1:6379> lpushx mykey2 e
(integer) 0
#可以看到mykey2没有关联任何List Value。
redis 127.0.0.1:6379> lrange mykey2 0 -1
(empty list or set)
#mykey键此时已经存在,所以该命令插入成功,并返回链表中当前元素的数量。
redis 127.0.0.1:6379> lpushx mykey e
(integer) 5
#获取该键的List Value的头部元素。
redis 127.0.0.1:6379> lrange mykey 0 0
1) "e"
2. LPOP/LLEN:
redis 127.0.0.1:6379> lpush mykey a b c d
(integer) 4
redis 127.0.0.1:6379> lpop mykey
"d"
redis 127.0.0.1:6379> lpop mykey
"c"
#在执行lpop命令两次后,链表头部的两个元素已经被弹出,此时链表中元素的数量是2
redis 127.0.0.1:6379> llen mykey
(integer) 2
3. LREM/LSET/LINDEX/LTRIM:
#为后面的示例准备测试数据。
redis 127.0.0.1:6379> lpush mykey a b c d a c
(integer) 6
#从头部(left)向尾部(right)变量链表,删除2个值等于a的元素,返回值为实际删除的数量。
redis 127.0.0.1:6379> lrem mykey 2 a
(integer) 2
#看出删除后链表中的全部元素。
redis 127.0.0.1:6379> lrange mykey 0 -1
1) "c"
2) "d"
3) "c"
4) "b"
#获取索引值为1(头部的第二个元素)的元素值。
redis 127.0.0.1:6379> lindex mykey 1
"d"
#将索引值为1(头部的第二个元素)的元素值设置为新值e。
redis 127.0.0.1:6379> lset mykey 1 e
OK
#查看是否设置成功。
redis 127.0.0.1:6379> lindex mykey 1
"e"
#索引值6超过了链表中元素的数量,该命令返回nil。
redis 127.0.0.1:6379> lindex mykey 6
(nil)
#设置的索引值6超过了链表中元素的数量,设置失败,该命令返回错误信息。
redis 127.0.0.1:6379> lset mykey 6 hh
(error) ERR index out of range
#仅保留索引值0到2之间的3个元素,注意第0个和第2个元素均被保留。
redis 127.0.0.1:6379> ltrim mykey 0 2
OK
#查看trim后的结果。
redis 127.0.0.1:6379> lrange mykey 0 -1
1) "c"
2) "e"
3) "c"
4. LINSERT:
#删除该键便于后面的测试。
redis 127.0.0.1:6379> del mykey
(integer) 1
#为后面的示例准备测试数据。
redis 127.0.0.1:6379> lpush mykey a b c d e
(integer) 5
#在a的前面插入新元素a1。
redis 127.0.0.1:6379> linsert mykey before a a1
(integer) 6
#查看是否插入成功,从结果看已经插入。注意lindex的index值是0-based。
redis 127.0.0.1:6379> lindex mykey 0
"e"
#在e的后面插入新元素e2,从返回结果看已经插入成功。
redis 127.0.0.1:6379> linsert mykey after e e2
(integer) 7
#再次查看是否插入成功。
redis 127.0.0.1:6379> lindex mykey 1
"e2"
#在不存在的元素之前或之后插入新元素,该命令操作失败,并返回-1。
redis 127.0.0.1:6379> linsert mykey after k a
(integer) -1
#为不存在的Key插入新元素,该命令操作失败,返回0。
redis 127.0.0.1:6379> linsert mykey1 after a a2
(integer) 0
5. RPUSH/RPUSHX/RPOP/RPOPLPUSH:
#删除该键,以便于后面的测试。
redis 127.0.0.1:6379> del mykey
(integer) 1
#从链表的尾部插入参数中给出的values,插入顺序是从左到右依次插入。
redis 127.0.0.1:6379> rpush mykey a b c d
(integer) 4
#通过lrange的可以获悉rpush在插入多值时的插入顺序。
redis 127.0.0.1:6379> lrange mykey 0 -1
1) "a"
2) "b"
3) "c"
4) "d"
#该键已经存在并且包含4个元素,rpushx命令将执行成功,并将元素e插入到链表的尾部。
redis 127.0.0.1:6379> rpushx mykey e
(integer) 5
#通过lindex命令可以看出之前的rpushx命令确实执行成功,因为索引值为4的元素已经是新元素了。
redis 127.0.0.1:6379> lindex mykey 4
"e"
#由于mykey2键并不存在,因此该命令不会插入数据,其返回值为0。
redis 127.0.0.1:6379> rpushx mykey2 e
(integer) 0
#在执行rpoplpush命令前,先看一下mykey中链表的元素有哪些,注意他们的位置关系。
redis 127.0.0.1:6379> lrange mykey 0 -1
1) "a"
2) "b"
3) "c"
4) "d"
5) "e"
#将mykey的尾部元素e弹出,同时再插入到mykey2的头部(原子性的完成这两步操作)。
redis 127.0.0.1:6379> rpoplpush mykey mykey2
"e"
#通过lrange命令查看mykey在弹出尾部元素后的结果。
redis 127.0.0.1:6379> lrange mykey 0 -1
1) "a"
2) "b"
3) "c"
4) "d"
#通过lrange命令查看mykey2在插入元素后的结果。
redis 127.0.0.1:6379> lrange mykey2 0 -1
1) "e"
#将source和destination设为同一键,将mykey中的尾部元素移到其头部。
redis 127.0.0.1:6379> rpoplpush mykey mykey
"d"
#查看移动结果。
redis 127.0.0.1:6379> lrange mykey 0 -1
1) "d"
2) "a"
3) "b"
4) "c"
Hash操作命令集合
1. HSET/HGET/HDEL/HEXISTS/HLEN/HSETNX:
#在Shell命令行启动Redis客户端程序
/> redis-cli
#给键值为myhash的键设置字段为field1,值为stephen。
redis 127.0.0.1:6379> hset myhash field1 "stephen"
(integer) 1
#获取键值为myhash,字段为field1的值。
redis 127.0.0.1:6379> hget myhash field1
"stephen"
#myhash键中不存在field2字段,因此返回nil。
redis 127.0.0.1:6379> hget myhash field2
(nil)
#给myhash关联的Hashes值添加一个新的字段field2,其值为liu。
redis 127.0.0.1:6379> hset myhash field2 "liu"
(integer) 1
#获取myhash键的字段数量。
redis 127.0.0.1:6379> hlen myhash
(integer) 2
#判断myhash键中是否存在字段名为field1的字段,由于存在,返回值为1。
redis 127.0.0.1:6379> hexists myhash field1
(integer) 1
#删除myhash键中字段名为field1的字段,删除成功返回1。
redis 127.0.0.1:6379> hdel myhash field1
(integer) 1
#再次删除myhash键中字段名为field1的字段,由于上一条命令已经将其删除,因为没有删除,返回0。
redis 127.0.0.1:6379> hdel myhash field1
(integer) 0
#判断myhash键中是否存在field1字段,由于上一条命令已经将其删除,因为返回0。
redis 127.0.0.1:6379> hexists myhash field1
(integer) 0
#通过hsetnx命令给myhash添加新字段field1,其值为stephen,因为该字段已经被删除,所以该命令添加成功并返回1。
redis 127.0.0.1:6379> hsetnx myhash field1 stephen
(integer) 1
#由于myhash的field1字段已经通过上一条命令添加成功,因为本条命令不做任何操作后返回0。
redis 127.0.0.1:6379> hsetnx myhash field1 stephen
(integer) 0
2. HINCRBY:
#删除该键,便于后面示例的测试。
redis 127.0.0.1:6379> del myhash
(integer) 1
#准备测试数据,该myhash的field字段设定值1。
redis 127.0.0.1:6379> hset myhash field 5
(integer) 1
#给myhash的field字段的值加1,返回加后的结果。
redis 127.0.0.1:6379> hincrby myhash field 1
(integer) 6
#给myhash的field字段的值加-1,返回加后的结果。
redis 127.0.0.1:6379> hincrby myhash field -1
(integer) 5
#给myhash的field字段的值加-10,返回加后的结果。
redis 127.0.0.1:6379> hincrby myhash field -10
(integer) -5
3. HGETALL/HKEYS/HVALS/HMGET/HMSET:
#删除该键,便于后面示例测试。
redis 127.0.0.1:6379> del myhash
(integer) 1
#为该键myhash,一次性设置多个字段,分别是field1 = "hello", field2 = "world"。
redis 127.0.0.1:6379> hmset myhash field1 "hello" field2 "world"
OK
#获取myhash键的多个字段,其中field3并不存在,因为在返回结果中与该字段对应的值为nil。
redis 127.0.0.1:6379> hmget myhash field1 field2 field3
1) "hello"
2) "world"
3) (nil)
#返回myhash键的所有字段及其值,从结果中可以看出,他们是逐对列出的。
redis 127.0.0.1:6379> hgetall myhash
1) "field1"
2) "hello"
3) "field2"
4) "world"
#仅获取myhash键中所有字段的名字。
redis 127.0.0.1:6379> hkeys myhash
1) "field1"
2) "field2"
#仅获取myhash键中所有字段的值。
redis 127.0.0.1:6379> hvals myhash
1) "hello"
2) "world"
Set集合操作命令
1. SADD/SMEMBERS/SCARD/SISMEMBER:
#在Shell命令行下启动Redis的客户端程序。
/> redis-cli
#插入测试数据,由于该键myset之前并不存在,因此参数中的三个成员都被正常插入。
redis 127.0.0.1:6379> sadd myset a b c
(integer) 3
#由于参数中的a在myset中已经存在,因此本次操作仅仅插入了d和e两个新成员。
redis 127.0.0.1:6379> sadd myset a d e
(integer) 2
#判断a是否已经存在,返回值为1表示存在。
redis 127.0.0.1:6379> sismember myset a
(integer) 1
#判断f是否已经存在,返回值为0表示不存在。
redis 127.0.0.1:6379> sismember myset f
(integer) 0
#通过smembers命令查看插入的结果,从结果可以,输出的顺序和插入顺序无关。
redis 127.0.0.1:6379> smembers myset
1) "c"
2) "d"
3) "a"
4) "b"
5) "e"
#获取Set集合中元素的数量。
redis 127.0.0.1:6379> scard myset
(integer) 5
2. SPOP/SREM/SRANDMEMBER/SMOVE:
#删除该键,便于后面的测试。
redis 127.0.0.1:6379> del myset
(integer) 1
#为后面的示例准备测试数据。
redis 127.0.0.1:6379> sadd myset a b c d
(integer) 4
#查看Set中成员的位置。
redis 127.0.0.1:6379> smembers myset
1) "c"
2) "d"
3) "a"
4) "b"
#从结果可以看出,该命令确实是随机的返回了某一成员。
redis 127.0.0.1:6379> srandmember myset
"c"
#Set中尾部的成员b被移出并返回,事实上b并不是之前插入的第一个或最后一个成员。
redis 127.0.0.1:6379> spop myset
"b"
#查看移出后Set的成员信息。
redis 127.0.0.1:6379> smembers myset
1) "c"
2) "d"
3) "a"
#从Set中移出a、d和f三个成员,其中f并不存在,因此只有a和d两个成员被移出,返回为2。
redis 127.0.0.1:6379> srem myset a d f
(integer) 2
#查看移出后的输出结果。
redis 127.0.0.1:6379> smembers myset
1) "c"
#为后面的smove命令准备数据。
redis 127.0.0.1:6379> sadd myset a b
(integer) 2
redis 127.0.0.1:6379> sadd myset2 c d
(integer) 2
#将a从myset移到myset2,从结果可以看出移动成功。
redis 127.0.0.1:6379> smove myset myset2 a
(integer) 1
#再次将a从myset移到myset2,由于此时a已经不是myset的成员了,因此移动失败并返回0。
redis 127.0.0.1:6379> smove myset myset2 a
(integer) 0
#分别查看myset和myset2的成员,确认移动是否真的成功。
redis 127.0.0.1:6379> smembers myset
1) "b"
redis 127.0.0.1:6379> smembers myset2
1) "c"
2) "d"
3) "a"
3. SDIFF/SDIFFSTORE/SINTER/SINTERSTORE:
#为后面的命令准备测试数据。
redis 127.0.0.1:6379> sadd myset a b c d
(integer) 4
redis 127.0.0.1:6379> sadd myset2 c
(integer) 1
redis 127.0.0.1:6379> sadd myset3 a c e
(integer) 3
#myset和myset2相比,a、b和d三个成员是两者之间的差异成员。再用这个结果继续和myset3进行差异比较,b和d是myset3不存在的成员。
redis 127.0.0.1:6379> sdiff myset myset2 myset3
1) "d"
2) "b"
#将3个集合的差异成员存在在diffkey关联的Set中,并返回插入的成员数量。
redis 127.0.0.1:6379> sdiffstore diffkey myset myset2 myset3
(integer) 2
#查看一下sdiffstore的操作结果。
redis 127.0.0.1:6379> smembers diffkey
1) "d"
2) "b"
#从之前准备的数据就可以看出,这三个Set的成员交集只有c。
redis 127.0.0.1:6379> sinter myset myset2 myset3
1) "c"
#将3个集合中的交集成员存储到与interkey关联的Set中,并返回交集成员的数量。
redis 127.0.0.1:6379> sinterstore interkey myset myset2 myset3
(integer) 1
#查看一下sinterstore的操作结果。
redis 127.0.0.1:6379> smembers interkey
1) "c"
#获取3个集合中的成员的并集。
redis 127.0.0.1:6379> sunion myset myset2 myset3
1) "b"
2) "c"
3) "d"
4) "e"
5) "a"
#将3个集合中成员的并集存储到unionkey关联的set中,并返回并集成员的数量。
redis 127.0.0.1:6379> sunionstore unionkey myset myset2 myset3
(integer) 5
#查看一下suiionstore的操作结果。
redis 127.0.0.1:6379> smembers unionkey
1) "b"
2) "c"
3) "d"
4) "e"
5) "a"
[a1]这三个选项是redis的配置文件默认自带的存储机制。表示每隔多少秒,有多少个key发生变化就生成一份dump.rdb文件,作为redis的快照文件
例如:save 60 10000 表示在60秒内,有10000个key发生变化,就会生成一份redis的快照
[a2]我自己修改的配置,表示每隔五秒钟,有一条数据发生变化都需要重新生成redis的快照
[a3]always: 每次写入一条数据,立即将这个数据对应的写日志fsync到磁盘上去,性能非常非常差,吞吐量很低; 确保说redis里的数据一条都不丢,那就只能这样了
[a4]每秒将os cache中的数据fsync到磁盘,这个最常用的,生产环境一般都这么配置,性能很高,QPS还是可以上万的
[a5]仅仅redis负责将数据写入os cache就撒手不管了,然后后面os自己会时不时有自己的策略将数据刷入磁盘,不可控了
第2节 storm实时看板案例:10、redis的安装使用回顾的更多相关文章
- 第2节 storm实时看板案例:9、实时看板综合案例
=================================== 10.实时看板案例 10.1 项目需求梳理 根据订单mq,快速计算双11当天的订单量.销售金额.
- 第2节 storm实时看板案例:12、实时看板综合案例代码完善;13、今日课程总结
详见代码 将任务提交到集群上面去运行 apache-storm-1.1.1/bin/storm jar cn.itcast.storm.kafkaAndStorm.KafkTopology kafka ...
- 第2节 storm实时看板案例:11、实时看板综合案例工程构建,redis的专业术语
redis当中的一些专业术语: redis缓存击穿 redis缓存雪崩 redis的缓存淘汰 =========================================== 详见代码
- 【Kafka】实时看板案例
目录 项目需求 项目模型 实现步骤 项目需求 快速计算双十一当天的订单量和销售金额 项目模型 实现步骤 一.创建topic bin/kafka-topics.sh --create --topic i ...
- 第3节 storm高级应用:1、上次课程回顾,今日课程大纲,storm下载地址、运行过程等
上次课程内容回顾: ConcurrentHashMap是线程安全的,为什么多线程的时候还不好使,为什么还要加static关键字 1.storm的基本介绍:strom是twitter公司开源提供给apa ...
- 第1节 storm编程:2、storm的基本介绍
课程大纲: 1.storm的基本介绍 2.storm的架构模型 3.storm的安装 4.storm的UI管理界面 5.storm的编程模型 6.storm的入门程序 7.storm的并行度 8.st ...
- Storm实时计算:流操作入门编程实践
转自:http://shiyanjun.cn/archives/977.html Storm实时计算:流操作入门编程实践 Storm是一个分布式是实时计算系统,它设计了一种对流和计算的抽象,概念比 ...
- 59、Spark Streaming与Spark SQL结合使用之top3热门商品实时统计案例
一.top3热门商品实时统计案例 1.概述 Spark Streaming最强大的地方在于,可以与Spark Core.Spark SQL整合使用,之前已经通过transform.foreachRDD ...
- 案例:Redis在唯品会的大规模应用
目前在唯品会主要负责redis/hbase的运维和开发支持工作,也参与工具开发工作,本文是在Redis中国用户组给大家分享redis cluster的生产实践. 分享大纲 本次分享内容如下: 1.生产 ...
随机推荐
- arc066E - Addition and Subtraction Hard
题目链接 题目大意 给定一个只含加减和数字的表达式,在其中添加括号,使其值最大. 解题思路 显然,只有减号后面的括号会使其中表达式的值取反. 然后只有已经有左括号时才能加入右括号. 所以用\(f_0\ ...
- Java入门笔记 06-常用类
介绍:本章将介绍Java的一些常用类,内容不完整,会在后续使用过程中逐步完善. 一. 字符串相关类: 1. String类介绍: |--- String类声明为final的,不能被继承: |--- 实 ...
- ubuntu循环登录
ubuntu12.04管理员账户登录不了桌面,只能客人会话登录 登录管理员账户时,输入密码后,一直在登录界面循环 费了好大劲啊,一上午的时间,终于搞定了,哈哈哈 ctrl+alt+f1 ,切换到tty ...
- 吴裕雄--天生自然Numpy库学习笔记:NumPy Matplotlib
Matplotlib 是 Python 的绘图库. 它可与 NumPy 一起使用,提供了一种有效的 MatLab 开源替代方案. 它也可以和图形工具包一起使用,如 PyQt 和 wxPython. W ...
- AS布局篇
LinearLayout 线性布局 RelativeLayout 相对布局 FrameLayout 帧布局 AbsoluteLayout绝对布局 TableLayout 表格布局 GridLayout ...
- input输入文字的时候背景会变色,如何去掉呢?
默认,如图: 当input框输入文字的时候背景会变色,如图: 有两种方法: 1.在form标签里家这个属性就行: autocomplete="off"
- win10常用快捷键总结
前言: 很多快捷键在不同版本系统基本相同的,但是今天推送的这篇文章更多的介绍 win10快捷键,微软也是大力推广 旗舰系统 win10 ,所以大家提前升级,提前学习还是有必要的.毕竟2020年微软会放 ...
- 【代码总结】GD库中添加图片水印
函数 getimagesize() bool imagecopymerge( resource dst_im, resource src_im, int dst_x, int dst_y, int s ...
- [网络转载 ]LoadRunner技巧之THML与URL两种录制模式分析
loadrunner自带网站的访问 Html_based script模式 Action() { web_url("WebTours", "URL=http://127. ...
- twisted 模拟scrapy调度循环
"""模拟scrapy调度循环 """from ori_test import pr_typeimport loggingimport ti ...