数据库SQL实战(一)
一、
1、
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`));
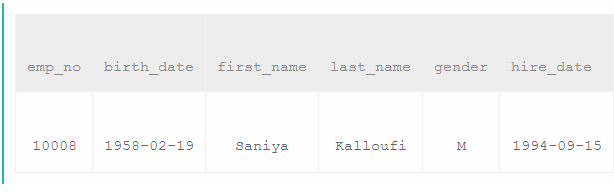

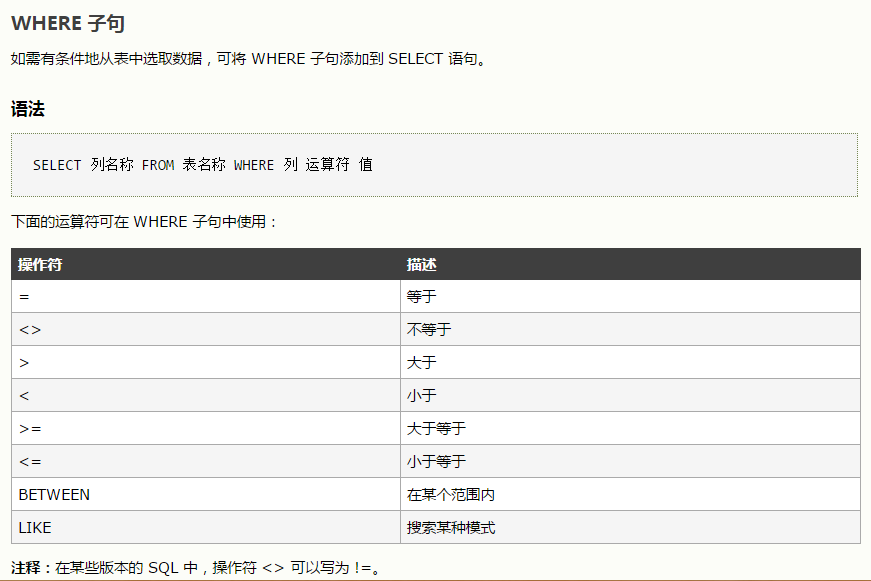
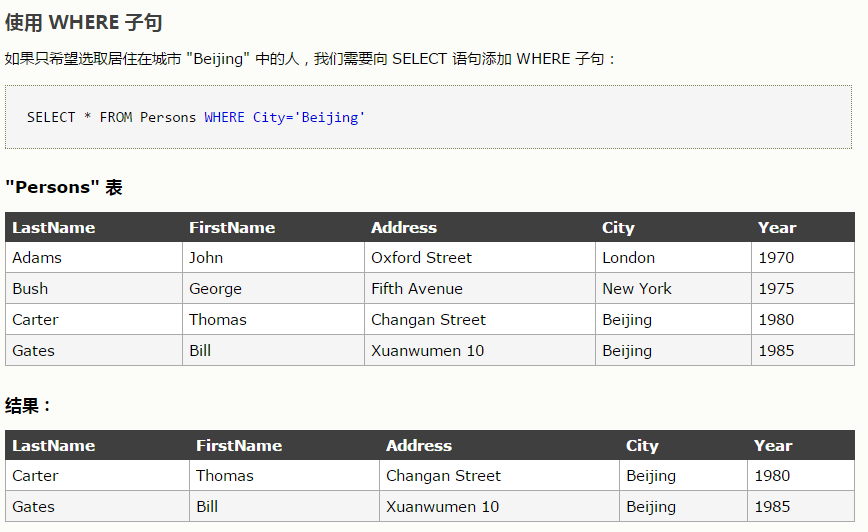
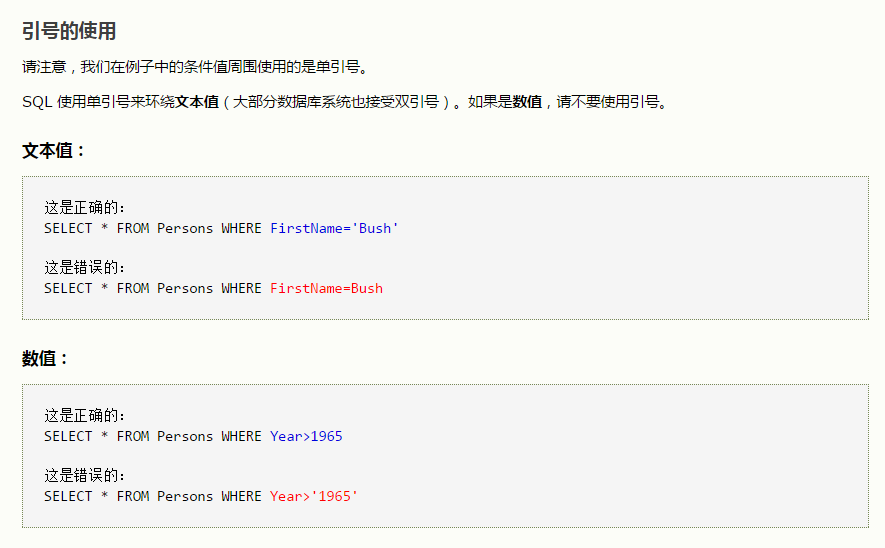
select * from employees where hire_date=(select max(hire_date) from employees)
2、排序后输出第一个
’
默认升序
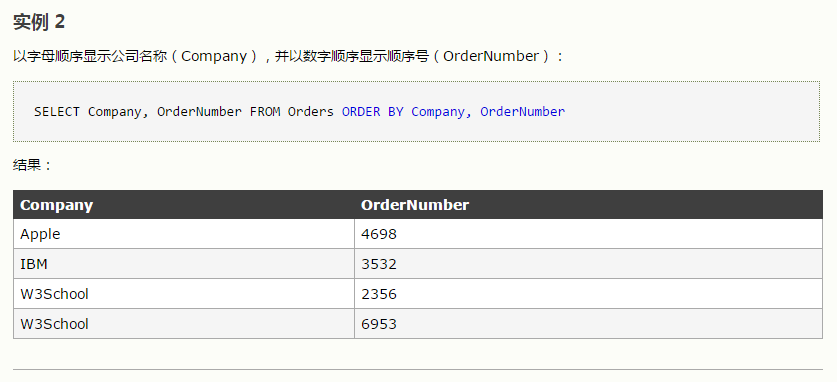
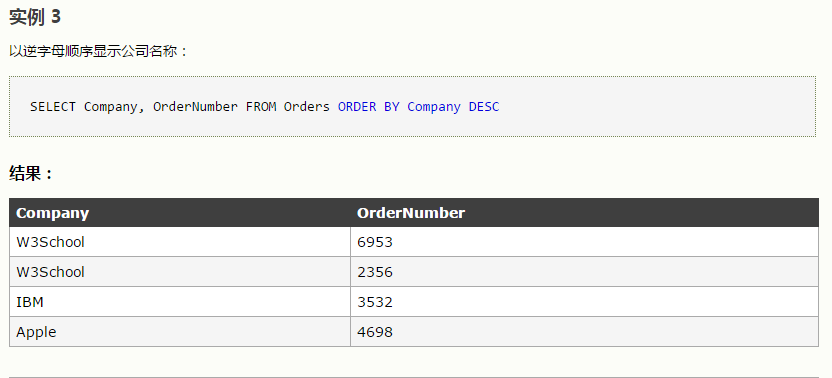
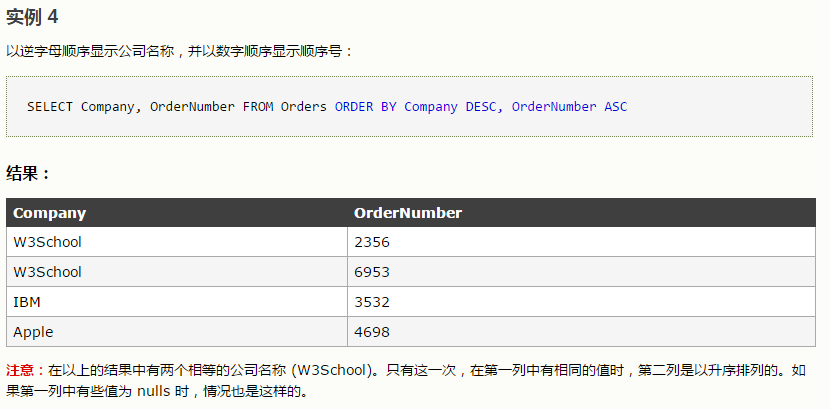

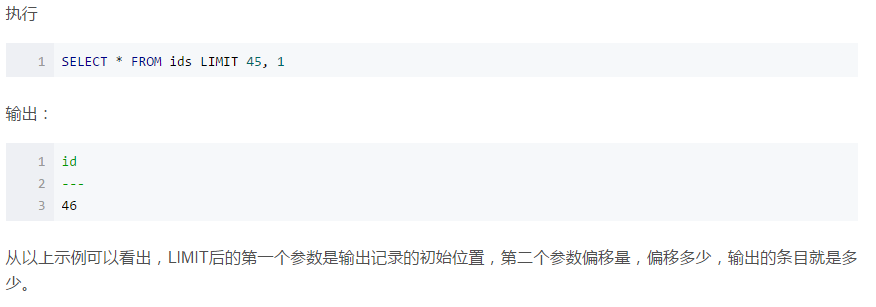
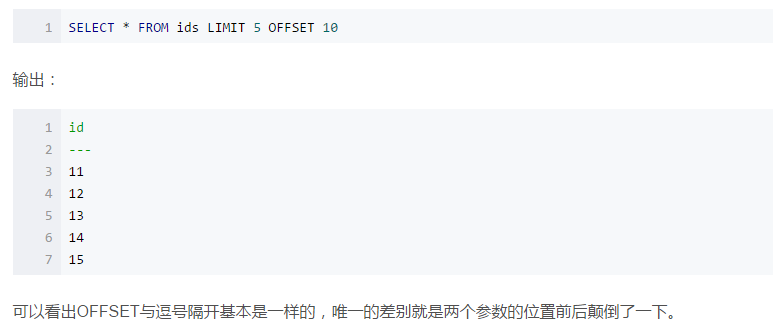
select * from employees order by hire_date desc
limit 0,1--从0开始
二、
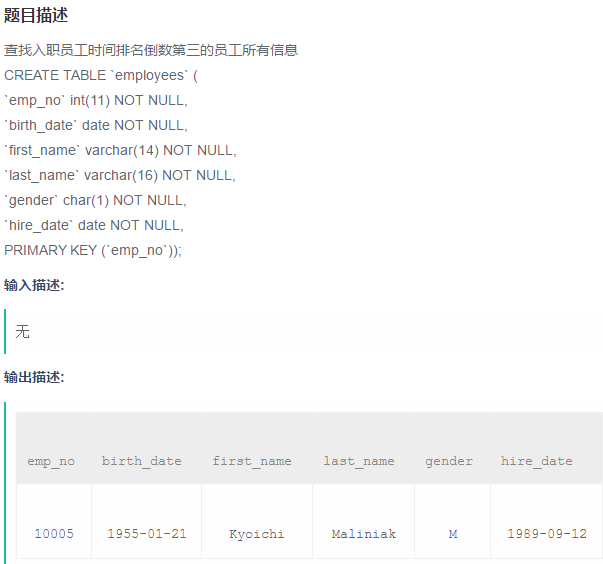
1、
降序排列后,输出第三个(并没有考虑重复的情况)
select * from employees order by hire_date desc
limit 2,1
2、
最严谨的是去除了重复后的第三个,然后找出与之相同的所有的
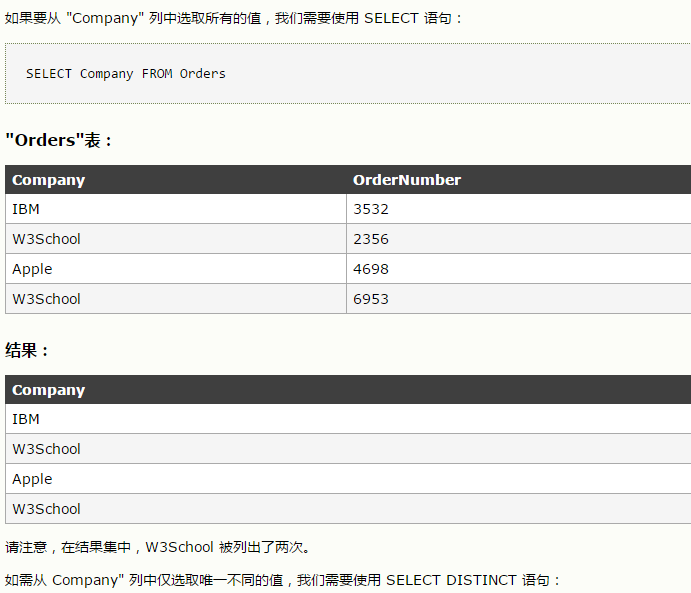
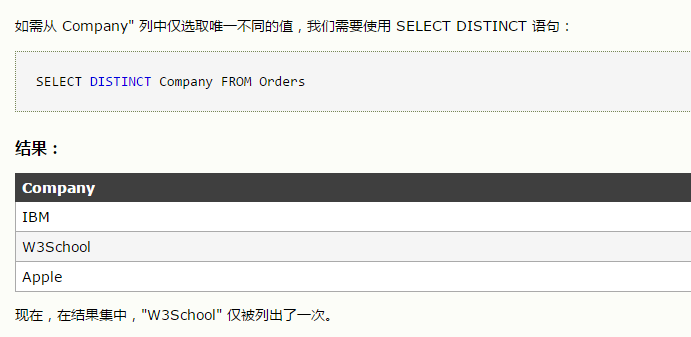
select * from employees --为了输出所有的信息
where hire_date=(select distinct hire_date from employees order by hire_date desc limit 2,1)
(select distinct hire_date from employees order by hire_date desc limit 2,1)这个是为了得到倒数第三个日期,注意limit2,1是为了输出这个日期,如果没有limit降序去重后的所有
where hire_date是输出所有选出的那一天。
三、
题目描述(合并表)
CREATE TABLE `dept_manager` (
`dept_no` char(4) NOT NULL,
`emp_no` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));

可以看到这个题目是从dept_manager表中选出部门编号dept_no添加到salaries表中。
主键、外键



select s.*,d.dept_no from salaries as s,dept_manager as d --别名 ,注意两个表的顺序
where s.emp_no=d.emp_no and s.to_date="9999-01-01" and d.to_date="9999-01-01" --选择条件
四、
查找所有已经分配部门的员工的last_name和first_name
CREATE TABLE `dept_emp` (
`emp_no` int(11) NOT NULL,
`dept_no` char(4) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`));
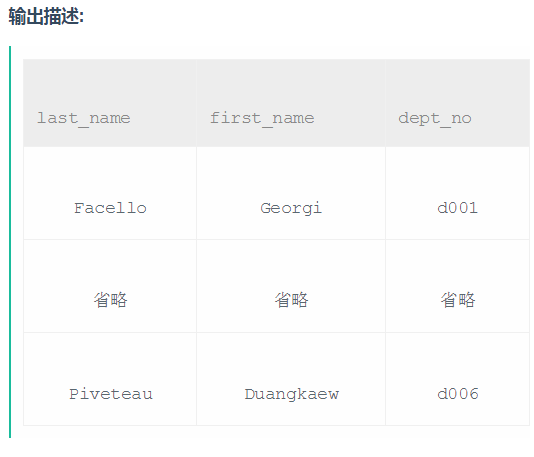
1、
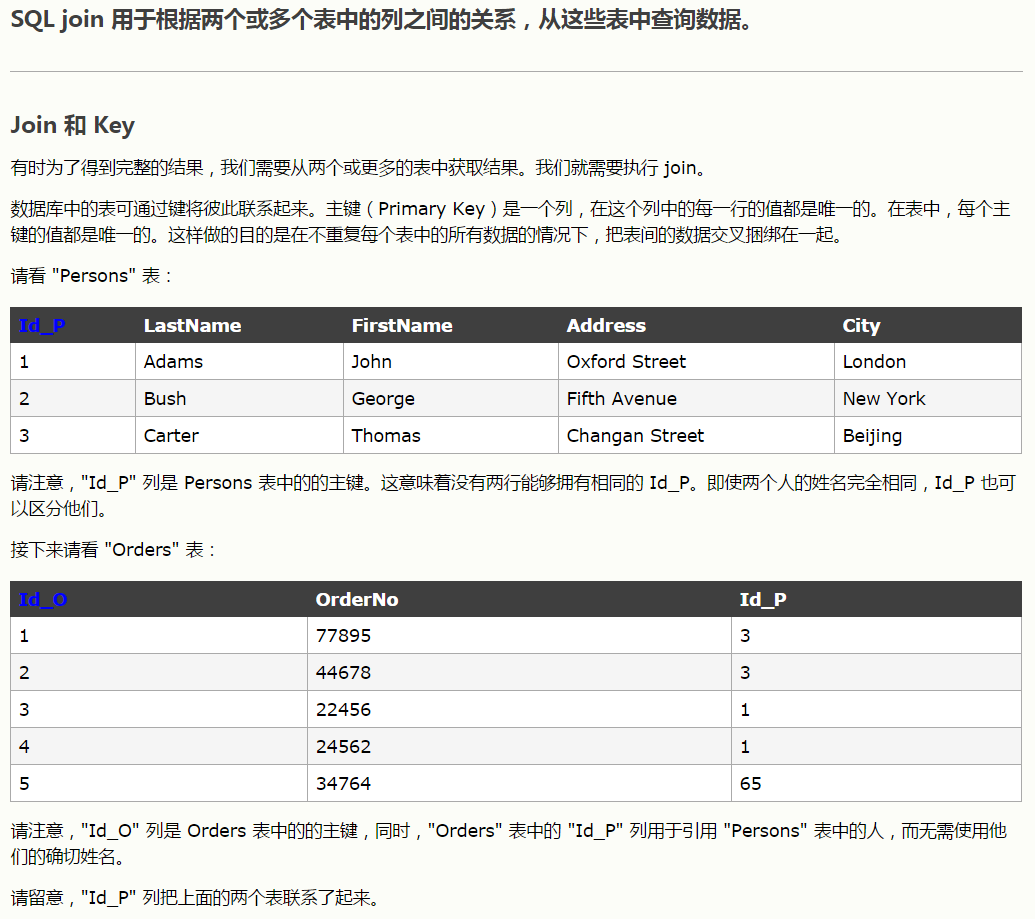

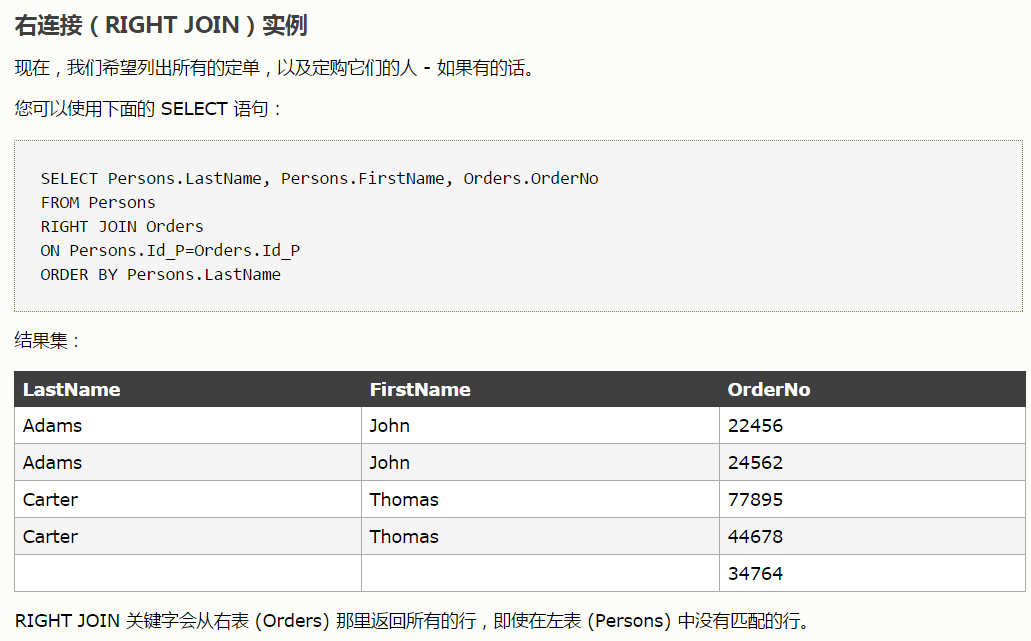
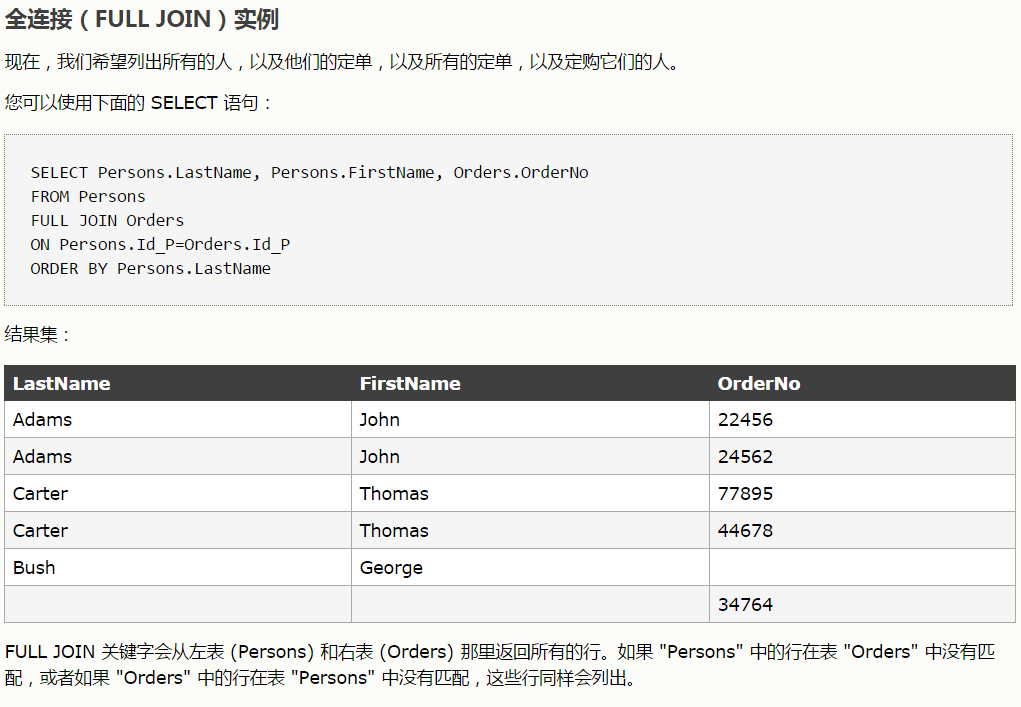
内连接
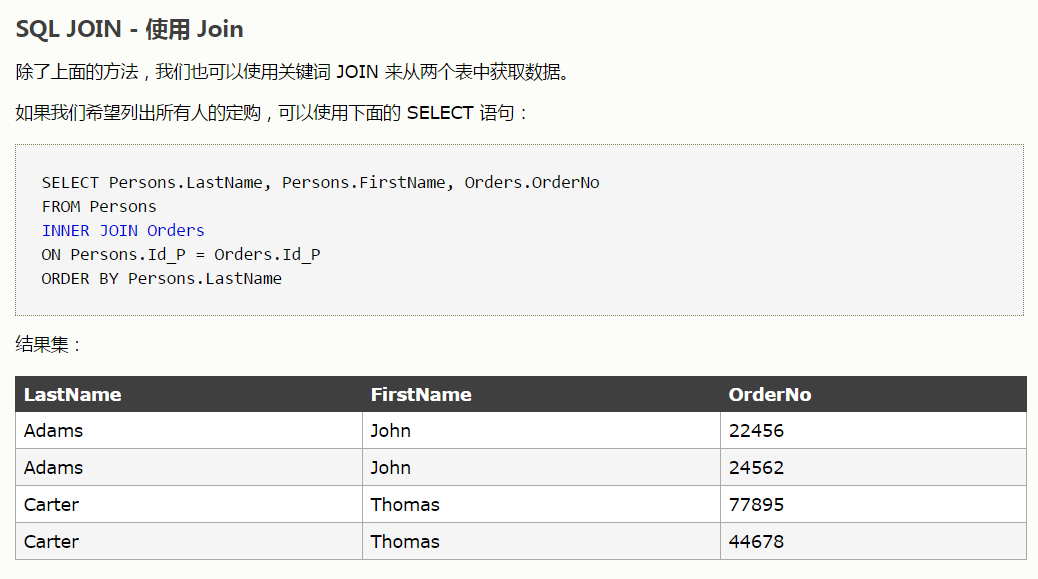
左连接

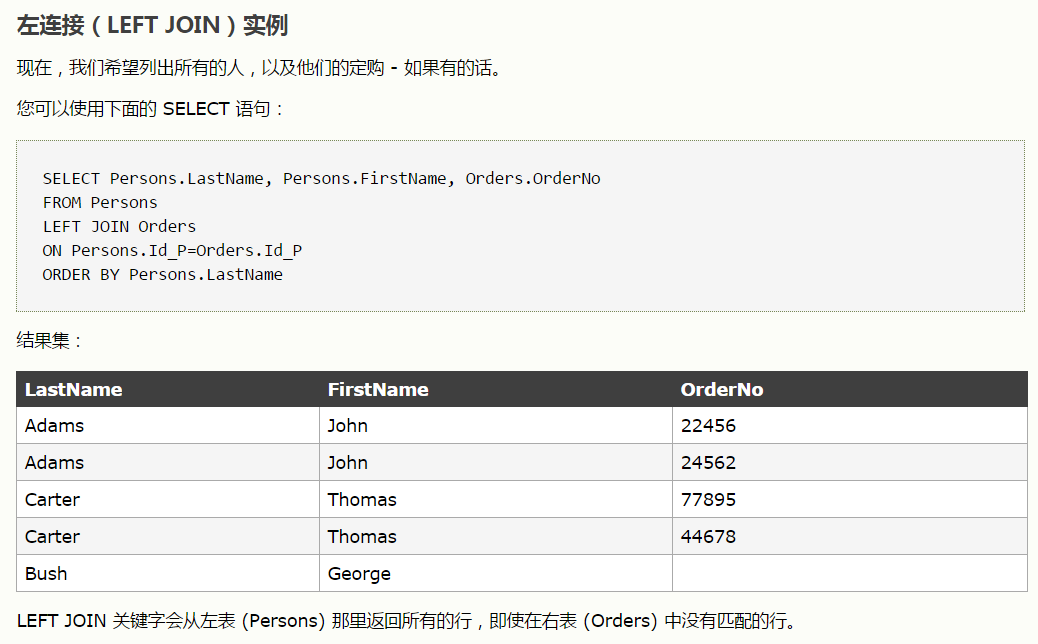
2、
select e.last_name,e.first_name,d.dept_no from employees as e,dept_emp as d
where e.emp_no=d.emp_no
3、join方法
select e.last_name,e.first_name,d.dept_no from employees as e join dept_emp as d
on e.emp_no=d.emp_no
五、
题目描述
CREATE TABLE `dept_emp` (
`emp_no` int(11) NOT NULL,
`dept_no` char(4) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`));
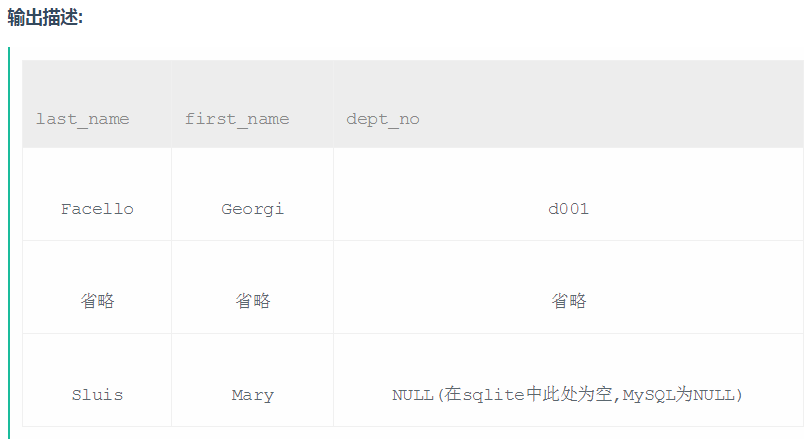
左连接的应用(选择 哪些列 从什么地方 到什么地方 具体条件是什么)
select e.last_name,e.first_name,d.dept_no from employees as e
left join dept_emp as d
on e.emp_no=d.emp_no
六、
查找所有员工入职时候的薪水情况,给出emp_no以及salary, 并按照emp_no进行逆序
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`));
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));
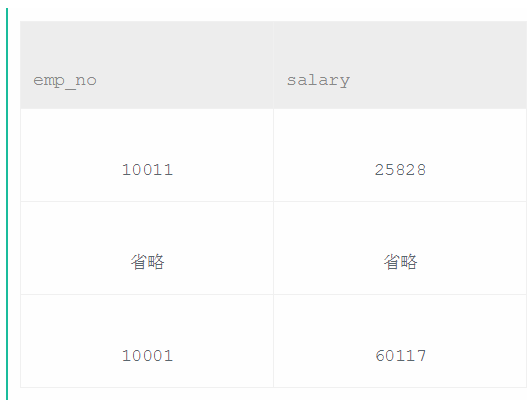
可以看出employees表中显示了emp_no和hire_date。而salaries 中emp_no对应了多个salary。所以得从employees 中读取hire_date,匹配合并表。
1、逗号并列查询两张表
select e.emp_no,s.salary from employees as e,salaries as s
where e.emp_no=s.emp_no and e.hire_date=s.from_date
order by e.emp_no desc
先合并表,再排序
2、join方法
select e.emp_no,s.salary from employees as e join salaries as s
on e.emp_no=s.emp_no and e.hire_date=s.from_date
order by e.emp_no desc
七、
题目描述
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));
1、


group by


having 函数

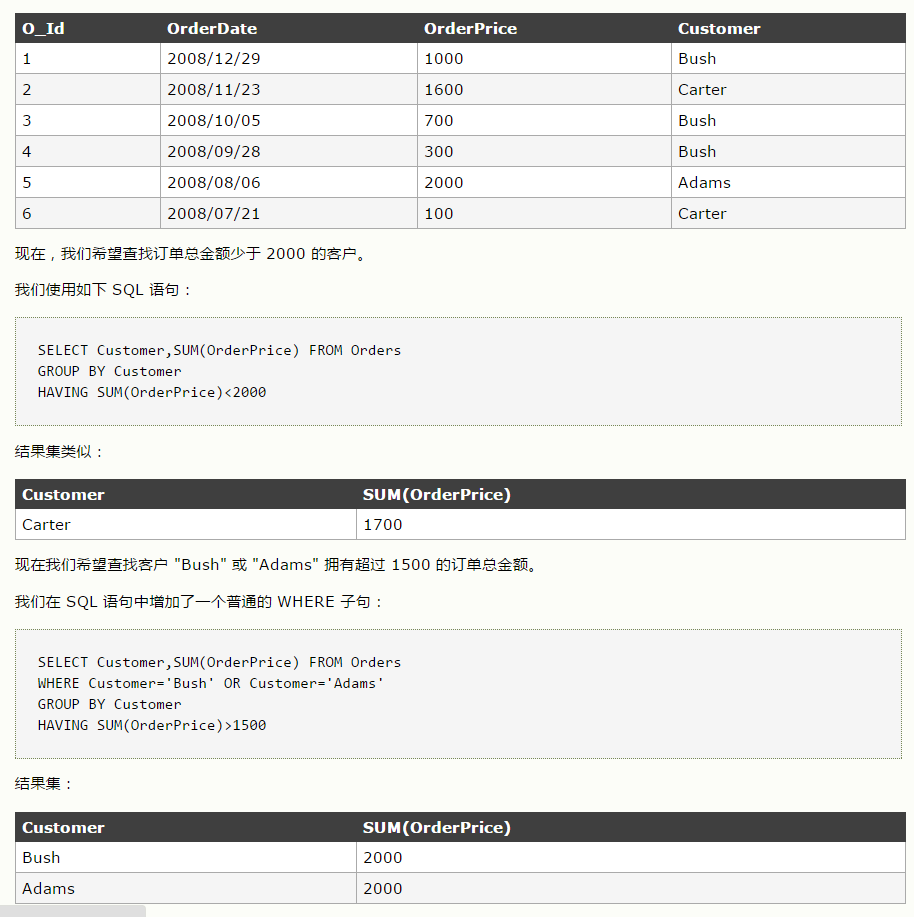
2、
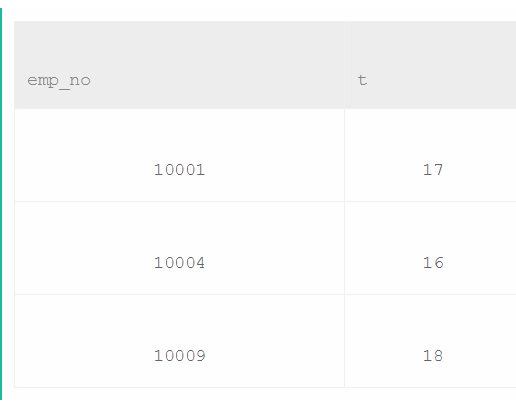
select emp_no,count(emp_no) from salaries
group by emp_no
having count(emp_no)>15
分类汇总,计数,判断。
八、
找出所有员工当前(to_date='9999-01-01')具体的薪水salary情况,对于相同的薪水只显示一次,并按照逆序显示
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));

本质就是找出 “9999-01-01”对应的salary,然后去重,排序
1、group by 去重
select salary from salaries
where to_date="9999-01-01"
group by salary --去重
order by salary desc
2、distinct去重
select distinct salary from salaries
where to_date="9999-01-01"
order by salary desc
九、
题目描述
CREATE TABLE `dept_manager` (
`dept_no` char(4) NOT NULL,
`emp_no` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));
1、
select d.dept_no,d.emp_no,s.salary from dept_manager as d,salaries as s
where d.emp_no=s.emp_no and d.to_date="9999-01-01" and s.to_date="9999-01-01"
order by d.emp_no
注意,最后order by d.emp_no 排序,否则就没有按格式输出
2、
select d.dept_no,d.emp_no,s.salary from dept_manager as d join salaries as s
on d.emp_no=s.emp_no and d.to_date="9999-01-01" and s.to_date="9999-01-01"
order by d.emp_no
十、
题目描述
CREATE TABLE `dept_manager` (
`dept_no` char(4) NOT NULL,
`emp_no` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`));
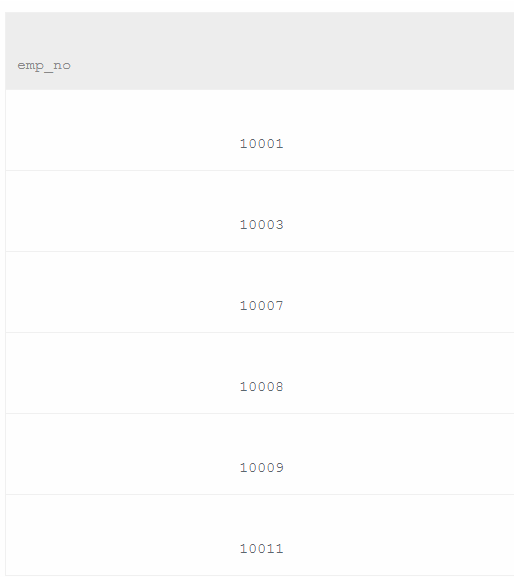
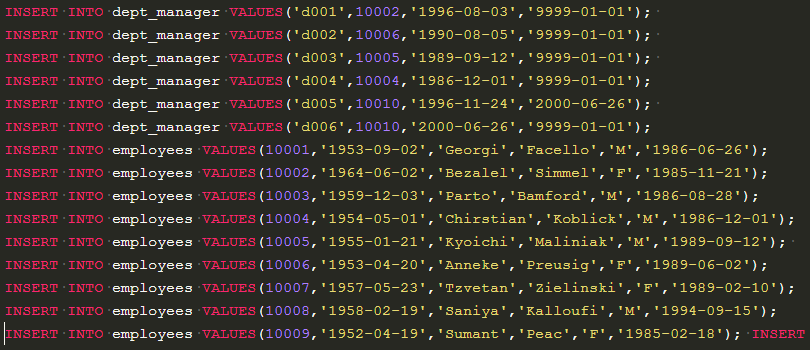
其实是将employees表中的emp_no去除dept_manager中的emp_no。
1、
select e.emp_no from employees as e
where e.emp_no not in(select d.emp_no from dept_manager as d)
先将dept_manager表中emp_no提取出来,判断employees中emp_no 在其中没有。
2、
利用左连接
SELECT emp_no FROM (SELECT * FROM employees LEFT JOIN dept_manager
ON employees.emp_no = dept_manager.emp_no)
WHERE dept_no IS NULL
简化后的代码。
select e.emp_no from employees as e left join dept_manager as d
on e.emp_no=d.emp_no --按条件左连接形成新的表 where d.emp_no is Null --新表条件输出
这道题可以看出,左连接是新生成了一个表,所有元素都有了,然后再根据新表中的数据筛选自己的数据。
数据库SQL实战(一)的更多相关文章
- 牛客网数据库SQL实战解析(51-61题)
牛客网SQL刷题地址: https://www.nowcoder.com/ta/sql?page=0 牛客网数据库SQL实战解析(01-10题): https://blog.csdn.net/u010 ...
- 牛客网数据库SQL实战解析(41-50题)
牛客网SQL刷题地址: https://www.nowcoder.com/ta/sql?page=0 牛客网数据库SQL实战解析(01-10题): https://blog.csdn.net/u010 ...
- 牛客网数据库SQL实战解析(31-40题)
牛客网SQL刷题地址: https://www.nowcoder.com/ta/sql?page=0 牛客网数据库SQL实战解析(01-10题): https://blog.csdn.net/u010 ...
- 牛客网数据库SQL实战解析(21-30题)
牛客网SQL刷题地址: https://www.nowcoder.com/ta/sql?page=0 牛客网数据库SQL实战解析(01-10题): https://blog.csdn.net/u010 ...
- 牛客网数据库SQL实战解析(11-20题)
牛客网SQL刷题地址: https://www.nowcoder.com/ta/sql?page=0 牛客网数据库SQL实战解析(01-10题): https://blog.csdn.net/u010 ...
- 牛客网数据库SQL实战解析(1-10题)
牛客网SQL刷题地址: https://www.nowcoder.com/ta/sql?page=0 牛客网数据库SQL实战解析(01-10题): https://blog.csdn.net/u010 ...
- 【牛客网】数据库SQL实战(题解)
1.查找最晚入职员工的所有信息 [题解] hire_date可能存在重复值,所以需要找到hire_date的最大值,然后再筛选,才能hire_date最晚的记录都筛选出来. [代码] 1 SELECT ...
- 牛客-数据库SQL实战
查找最晚入职员工的所有信息 CREATE TABLE `employees` ( `emp_no` ) NOT NULL, `birth_date` date NOT NULL, `first_nam ...
- 牛客网数据库SQL实战(此处只有答案,没有表内容)
1.查找最晚入职员工的所有信息 select * from employees order by hire_date desc limit 1; --limit n表示输出前n条数据,limit ...
- 牛客网数据库SQL实战(21-25)
21.查找所有员工自入职以来的薪水涨幅情况,给出员工编号emp_no以及其对应的薪水涨幅growth,并按照growth进行升序CREATE TABLE `employees` (`emp_no` i ...
随机推荐
- 常用css3选择器
<div class="wrapper"> <p class="test1">1</p> <p class=" ...
- 每日一点:git 与 github 区别
絮絮叨叨在前:以前的公司,都用svn 进行代码管理.最近我那程序猿先生真的受不了我,强迫我使用tortoiseGit. 一开始对于 git 和 github 傻傻分不清,干脆自己整理资料,总结一下. ...
- 【从零单排HBase 01】从一无所知到5分钟快速了解HBase
最近公司正好准备投入HBase,因此做了一些基础学习准备,所以先暂时停止MySQL的更新,把HBase的学习心得跟大家分享一下,接下来一段时间都会发布HBase相关内容. 在学的过程中,发现跟MySQ ...
- FSBPM流程引擎(002)之表单+自定义流程挂载到引擎
本章节介绍如何将实际业务的表单和自定义流程挂载到FSBPM流程引擎上. 首先进入引擎交互界面: 点击创建:->出差申请 然后根据实际的业务输入对应的数据项即可,比如[姓名,部门,开始时间,结束时 ...
- 一文掌握Redis的三种集群方案
在开发测试环境中,我们一般搭建Redis的单实例来应对开发测试需求,但是在生产环境,如果对可用性.可靠性要求较高,则需要引入Redis的集群方案.虽然现在各大云平台有提供缓存服务可以直接使用,但了解一 ...
- 使用VS2017进行Python代码的编写并打印出九九乘法表
我们来盘一盘怎么使用VS2017进行python代码的编写并打印出九九乘法表. 使用Visual Studio 2017进行Python编程不需要太复杂的工作,只需要vs2017安装好对Python的 ...
- 数据结构 - ArrayList
简介 ArrayList是一个动态数组.ArrayList几乎拥有数组所有优点,例如元素有序,索引访问等:并且一般情况下它还不会越界,添加元素时它能动态扩容.平时工作中ArrayList被我们广泛应用 ...
- js 图片实现无缝滚动
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- Spark入门(六)--Spark的combineByKey、sortBykey
spark的combineByKey combineByKey的特点 combineByKey的强大之处,在于提供了三个函数操作来操作一个函数.第一个函数,是对元数据处理,从而获得一个键值对.第二个函 ...
- Spark入门(五)--Spark的reduce和reduceByKey
reduce和reduceByKey的区别 reduce和reduceByKey是spark中使用地非常频繁的,在字数统计中,可以看到reduceByKey的经典使用.那么reduce和reduceB ...