spark-2.4.5 安装记录
参考 https://data-flair.training/blogs/install-apache-spark-multi-node-cluster/
下载 spark  地址为
地址为
http://spark.apache.org/downloads.html
准备三个节点
192.168.1.1 [hostname] master
192.168.1.2 [hostname] slave1
192.168.1.3 [hostname] slave2
将以上配置 append 到 三个节点机器上的 /etc/hosts 中。由于我这里三台机器的 domain 均不同,所以设置了 [hostname],例如 master 节点的为
192.168.1.1 xxx.localdomain master
查看主机名方法为,
$ hostname
如果最后启动spark 报错 unknown hostname,一般就是指主机名未设置,此时通过
$ hostname -i
发现会报同样的错误。
安装步骤:
一、设置 ssh 免密登录
如果没有安装 ssh,则需要安装
sudo apt install openssh-server
三台机器上均执行
ssh-keygen -t rsa
一路回车,使用默认设置(密钥文件路径和文件名)
将 slave1 slave2 上面的 ~/.ssh/id_rsa.pub 文件 拷贝到 master 节点上,
scp ~/.ssh/id_rsa.pub xxx@master:~/.ssh/id_rsa.pub.slave1
scp ~/.ssh/id_rsa.pub xxx@master:~/.ssh/id_rsa.pub.slave2
注意,xxx 表示用户名,这三台机器上最好使用相同的用户名,如需要,可创建用户
adduser xxx # 创建新用户 xxx
passwd xxx # 给 xxx 设置密码
在 master 上执行
cat ~/.ssh/id_rsa.pub* >> ~/.ssh/authorized_keys
scp ~/.ssh/authorized_keys xxx@slave1:~/.ssh/authorized_keys
scp ~/.ssh/authorized_keys xxx@slave2:~/.ssh/authorized_keys
在 master 上验证无密码登录
ssh slave1
ssh slave2
在 slave1/slave2 上也可以无密码登录其他两个节点。
注意:.ssh 文件夹的权限必须为 700, authorized_keys 文件权限必须为 600(其他权限值可能均不奏效),修改权限使用
chmod ~/.ssh
chmod ~/.ssh/authorized_keys
二、安装jdk ,scala,spark
省略,spark 的安装仅仅是将上面下载的文件解压即可。注意配置环境变量
export JAVA_HOME=...
export SCALA_HOME=...
export SPARK_HOME=...
export PATH=$JAVA_HOME/bin:$SCALA_HOME/bin:$SPARK_HOME/bin:$PATH
在 master 节点上,进入 SPARK_HOME 下的 conf 目录,
cd conf
cp spark-env.sh.template spark-env.sh
cp slaves.template slaves
编辑 slaves 文件
# localhost
slave1
slave2
编辑 spark-env.sh 文件
export JAVA_HOME=...
export SPARK_WORKER_CORES=
在 slave1 和 slave2 上,执行同样的操作。
注意:spark 目录最好在三台节点上保持相同,即 环境变量 SPARK_HOME 相同
三、启动集群
在 master 节点上执行
sbin/start-all.sh
关闭集群则执行
sbin/stop-all.sh
启动后,可以在 master 或 slave1/slave2 上执行 jps 以查看 java 进程。查看 web 界面,地址为
http://MASTER-IP:8080/
如果发现 worker 节点连接不是 master,报错如下
Caused by: java.io.IOException: Connecting to : timed out ( ms)
...
org.apache.spark.deploy.worker.Worker$$anonfun$org$apache$spark$deploy$worker$Worker$$tryRegisterAllMasters$$$anon$.run
...
那么需要在 三台机器上的 $SPARK_HOME/conf/spark-env.sh 添加
export SPARK_MASTER_HOST=<master ip>
然后重新执行
sbin/start-all.sh
最终web 管理界面为
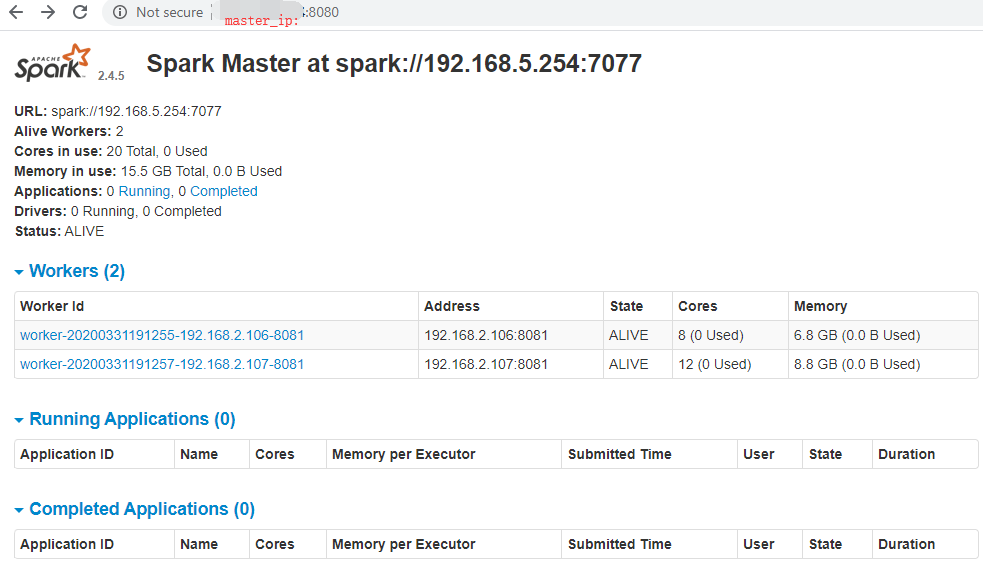
点击 worker id 下的某个worker,跳转至 worker web 页面,如果此时出现连接失败,请检查 防火墙是否开通,执行如下
sudo firewall-cmd --query-port=/tcp # 返回yes or no,表示是否开放
sudo firewall-cmd --zone=public --add-port=80/tcp --permanent # 添加白名单
sudo firewall-cmd --reload # 重新装置规则
sudo firewall-cmd --query-port=8081/tcp
如果检查 8081 端口已经开放,仍然打不开 worker web 界面,则执行
sudo iptables -F
spark-2.4.5 安装记录的更多相关文章
- spark的standlone模式安装和application 提交
spark的standlone模式安装 安装一个standlone模式的spark集群,这里是最基本的安装,并测试一下如何进行任务提交. require:提前安装好jdk 1.7.0_80 :scal ...
- 分布式监控系统Zabbix-3.0.3-完整安装记录(7)-使用percona监控MySQL
前面已经介绍了分布式监控系统Zabbix-3.0.3-完整安装记录(2)-添加mysql监控,但是没有提供可以直接使用的Key,太过简陋,监控效果不佳.要想更加仔细的监控Mysql,业内同学们都会选择 ...
- 关于node.js和npm,cnpm的安装记录以及gulp自动构建工具的使用
关于node.js和npm,cnpm的安装记录以及gulp自动构建工具的使用 工作环境:window下 在一切的最开始,安装node.js (中文站,更新比较慢http://nodejs.cn/) ...
- sourceinsight安装记录
sourceinsight安装记录 此文章为本人使用sourceinsight一个星期之后的相关设置步骤记录和经验记录,以备以后查验,网上的相关资料都也较为完善,但是对于新手还是有一定困难的,所以在这 ...
- openerp安装记录及postgresql数据库问题解决
ubuntu-14.04下openerp安装记录1.安装PostgreSQL 数据库 a.安装 sudo apt-get install postgresql 安装后ubu ...
- Matlab安装记录 - LED Control Activex控件安装
Matlab安装记录-LED Control Activex控件安装 2013-12-01 22:06:36 最近在研究Matlab GUI技术,准备用于制作上位机程序:在Matlab GUI的技术 ...
- Arch Linux 安装记录
Arch Linux 安装记录 基本上参考wiki上的新手指南,使用arch 2014.6.1 iso安装 设置网络 有线网络 Arch Linux 默认开启DHCP. 静态ip 首先关闭DHCP:s ...
- redis5.0.3单实例简单安装记录
redis5.0.3单实例简单安装记录 日常需要测试使用,索性记录下来,免得临时又麻烦的找资料. yum -y install make gcc-c++ cmake bison-devel ncurs ...
- mysql5.7安装记录
mysql安装记录 版本5.7 windows系统 一.缺少my.ini文件 [mysql]# 设置mysql客户端默认字符集default-character-set=utf8 [mysqld]#设 ...
- Liunx/RHEL6.5 Oracle11 安装记录
1.创建用户组 groupadd oinstall #创建用户组oinstall groupadd dba #创建用户组dba useradd -g oinstall -g dba -m oracle ...
随机推荐
- python爬取《龙岭迷窟》的数据,看看质量剧情还原度到底怎么样
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:简单 PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行 ...
- 爬虫的新手使用教程(python代理IP)
前言 Python爬虫要经历爬虫.爬虫被限制.爬虫反限制的过程.当然后续还要网页爬虫限制优化,爬虫再反限制的一系列道高一尺魔高一丈的过程.爬虫的初级阶段,添加headers和ip代理可以解决很多问题. ...
- 处理数字的类 —— Math类 、 Random类 、 BigDecimal类 与 BigInteger类
在我们学习C语言时,我们处理数据时要调用很多函数,那么,Java也有很多的方法可以来处理数值的类. 那么,在本篇博文中,本人就来讲解三个用于处理数值的类 -- Math类 . Random类 与 Bi ...
- 接触 Jmeter
Apache JMeter是 Apache组织开发的基于 Java的开源压力测试工具.接口以及自动化测试. JMeter 可以进行参数化测试,实现自动化脚本与测试数据分离,能够对应用程序做功能/回归测 ...
- Mybatis源码详解系列(四)--你不知道的Mybatis用法和细节
简介 这是 Mybatis 系列博客的第四篇,我本来打算详细讲解 mybatis 的配置.映射器.动态 sql 等,但Mybatis官方中文文档对这部分内容的介绍已经足够详细了,有需要的可以直接参考. ...
- MVC-路由扩展-限制浏览器
根据路由原理,MVC每次都会走获取路由上下文数据. 自定义Route 调用,以及完善其他代码 运行结果,当在谷浏览器执行时:
- ntp和chrony
目录 chrony 简介 ntp pool ntp 配置文件 chrony 配置文件 chronyc 命令行工具 修改时区 chrony 简介 chrony 是 RedHat 开发的,它是网络时间协议 ...
- fasttext 和pysparnn的安装
- pytorch LSTM情感分类全部代码
先运行main.py进行文本序列化,再train.py模型训练 dataset.py from torch.utils.data import DataLoader,Dataset import to ...
- TensorFlow keras vgg16net的使用
from tensorflow.python.keras.applications.vgg16 import VGG16,preprocess_input,decode_predictions fro ...