网站爬取-案例四:知乎抓取(COOKIE登录抓取个人中心)(第二卷)
接着上卷来分析,作为开发人员我们都知道,登录是一个想指定URL发送POST请求的过程,所以我们需要找到请求的URL,以及字段,先用一个错误账号和密码做一下尝试,如果是正确的话会直接跳转到别的页面,这样COOKIE就会刷新
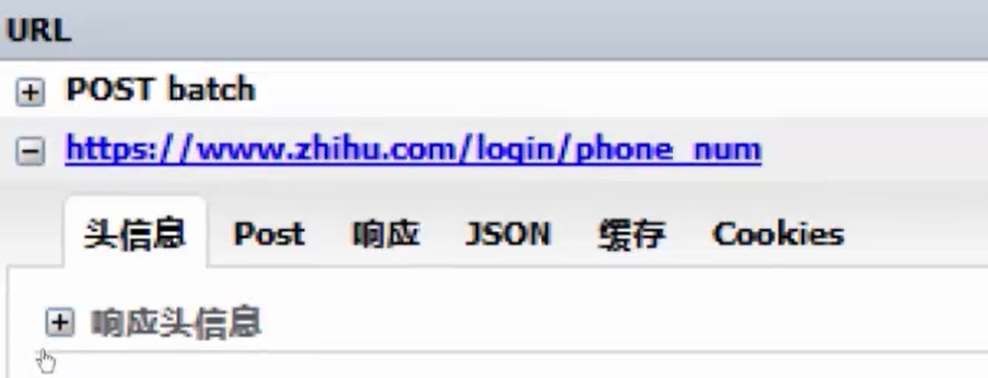
很明显拿到了URL看的出来这是手机号的方式进行登录,看下数据

_xsrf保证请求得安全性防止攻击
再用EMAIL试一下
 看下参数
看下参数
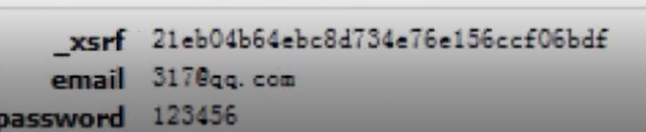
效果相似
这样请求的URL以及字段都找到了
现在我们需要判断请求类型,先通过源码找一下_xsrf
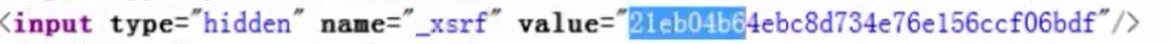
现在我们开始编译
 兼容写法引入COOKLELIB
兼容写法引入COOKLELIB
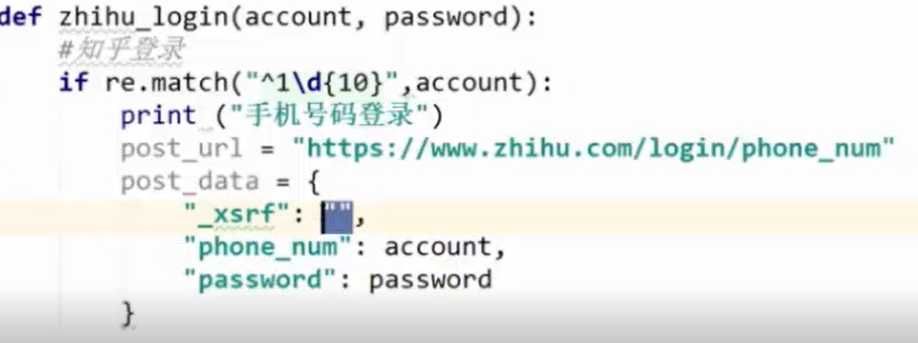 登陆请求
登陆请求
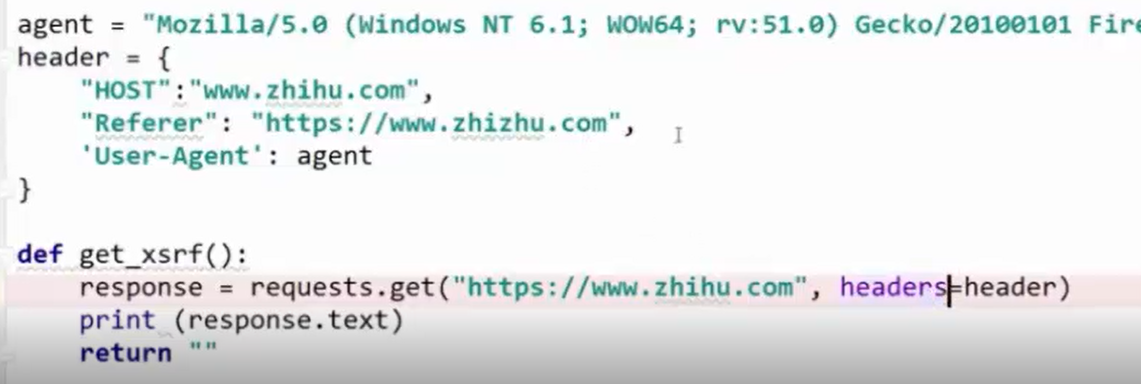 获取_xsrf
获取_xsrf
 正则获取
正则获取
 看下结果
看下结果
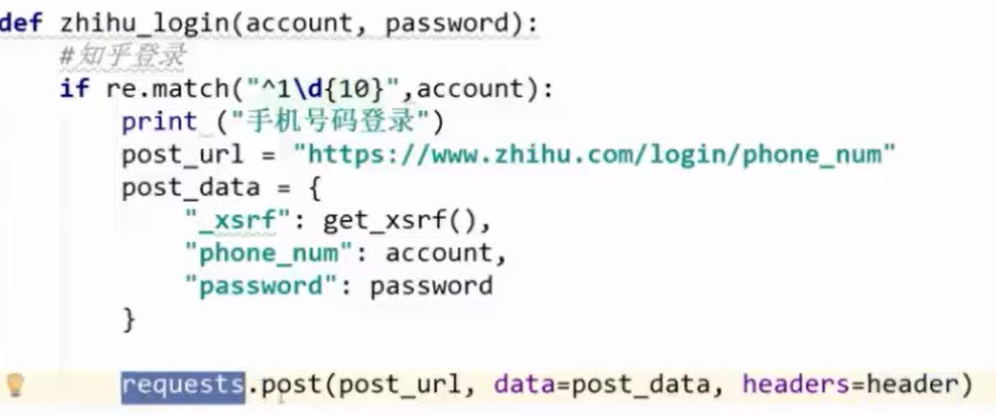 这次可以请求,但是这里需要做个登陆,我们这里用下REQUESTS里的SESSION,加大效率
这次可以请求,但是这里需要做个登陆,我们这里用下REQUESTS里的SESSION,加大效率
 这样不用一次次请求了
这样不用一次次请求了
 全部换掉
全部换掉
 调用方法用于存储
调用方法用于存储


保存到本地,以后就可以使用了
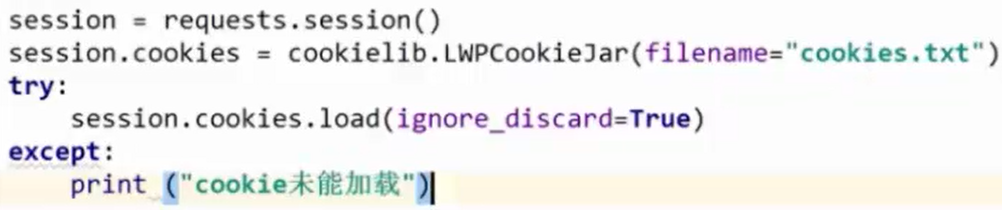 加一步异常处理
加一步异常处理
 读写下页面
读写下页面
 获取了页面
获取了页面
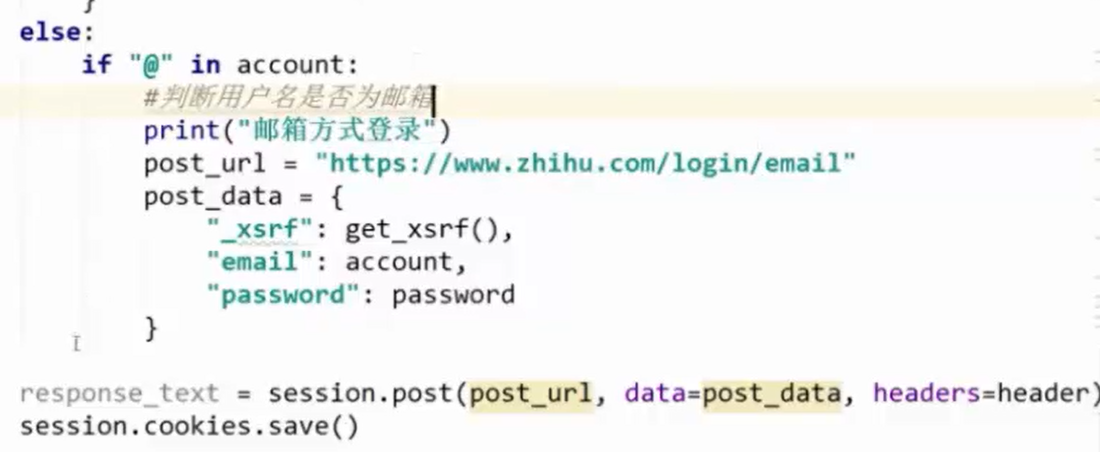 再加一步邮箱验证
再加一步邮箱验证
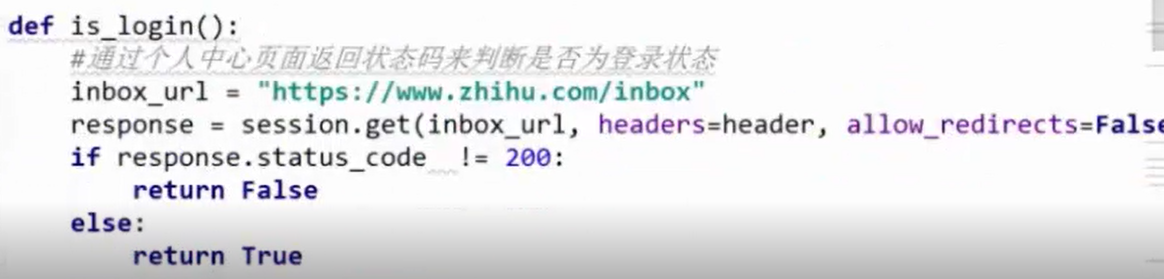
最后一步加一步判断用户是否登陆
网站爬取-案例四:知乎抓取(COOKIE登录抓取个人中心)(第二卷)的更多相关文章
- 网站爬取-案例三:今日头条抓取(ajax抓取JS数据)
今日头条这类的网站制作,从数据形式,CSS样式都是通过数据接口的样式来决定的,所以它的抓取方法和其他网页的抓取方法不太一样,对它的抓取需要抓取后台传来的JSON数据,先来看一下今日头条的源码结构:我们 ...
- Java爬虫_资源网站爬取实战
对 http://bestcbooks.com/ 这个网站的书籍进行爬取 (爬取资源分享在结尾) 下面是通过一个URL获得其对应网页源码的方法 传入一个 url 返回其源码 (获得源码后,对源码进 ...
- Python爬虫入门教程 2-100 妹子图网站爬取
妹子图网站爬取---前言 从今天开始就要撸起袖子,直接写Python爬虫了,学习语言最好的办法就是有目的的进行,所以,接下来我将用10+篇的博客,写爬图片这一件事情.希望可以做好. 为了写好爬虫,我们 ...
- 5分钟掌握智联招聘网站爬取并保存到MongoDB数据库
前言 本次主题分两篇文章来介绍: 一.数据采集 二.数据分析 第一篇先来介绍数据采集,即用python爬取网站数据. 1 运行环境和python库 先说下运行环境: python3.5 windows ...
- selenium在爬虫领域的初涉(自动打开网站爬取信息)
selenium简介 Selenium 是一个用于Web应用程序测试的工具.Selenium测试直接运行在浏览器中,就像真正的用户在操作一样.这个工具的主要功能包括:测试与浏览器的兼容性--测试你的应 ...
- 基于webmagic的种子网站爬取
代码地址如下:http://www.demodashi.com/demo/12175.html 1. 概述 因为无聊,闲来没事做,故突发奇想,爬个种子,顺便学习爬虫.本文将介绍使用Spring/Myb ...
- Heritrix源码分析(十四) 如何让Heritrix不间断的抓取(转)
欢迎加入Heritrix群(QQ):109148319,10447185 , Lucene/Solr群(QQ) : 118972724 本博客已迁移到本人独立博客: http://www.yun5u ...
- python3下scrapy爬虫(第二卷:初步抓取网页内容之直接抓取网页)
上一卷中介绍了安装过程,现在我们开始使用这个神奇的框架 跟很多博主一样我也先选择一个非常好爬取的网站作为最初案例,那么我先用屌丝必备网站http://www.shaimn.com/xinggan/作为 ...
- scrapy 知乎的模拟登陆及抓取用户数据
最近看了python的scrapy 框架并用其抓取了部分知乎用户数据,代码主要是集中在知乎登陆和抓取时候的逻辑处理上. 1. 首先进入知乎登陆页面zhihu.com/#sigin上, 用xpath提取 ...
随机推荐
- Ubuntu 不插优盘无法启动
ubuntu安装成功后只能通过优盘启动 不插优盘就无法启动 启动后拔掉优盘没问题 难道动过优盘安装的 2013-06-16 20:01 提问者悬赏:5分 | 理电池 | 分类:电脑外接设备 | 浏览2 ...
- CodeForces - 686D 【树的重心】
传送门:http://codeforces.com/problemset/problem/686/D 题意:给你n个节点,其中1为根, 第二行给你2~n的节点的父亲节点编号. 然后是q个询问,求询问的 ...
- EF Core开发模式之Code First
Code First顾名思义,代码为先.首先编写完相关的实体类及DbContext派生类,然后通过映射关系自动在数据库中完成数据库表的创建. 本例中创建一个班级和学生的管理,主要有班级类MyClass ...
- MySQL性能管理及架构设计:第2章 什么影响了MySQL性能
第2章 什么影响了MySQL性能 2-1 影响性能的几个方面 1.服务器的硬件 2.服务器的操作系统 3.数据库的存储引擎 4.数据库的参数配置 5.数据库表结构设计和SQL语句的编写和优化 2-2 ...
- UML-GRASP总结
对象设计的核心 1).对象交互 2).职责分配
- vue项目 首页开发 part3
da当拖动图标时候,只有上部分可以,下部分无响应 swiper 为根页面引用,其中的css为独立,点击swiper标签可以看见其包裹区域只有部分 那么需要修改 就需要穿透样式 外部 >> ...
- Django2.0——中间件
Django中间件middleware本质是一个类,在请求到返回的中间,类中不同的方法会在指定的时机中被触发.setting.py的变量MIDDLEWARE_CLASSES中的每一个元素都是中间件,且 ...
- linux 离线安装mysql7或者8
安装方式:官网下载压缩包进行安装 1.下载jdk8 登录网址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-download ...
- Django框架(九):视图(二) HttpRequest对象、HttpResponse对象
1. HttpRequest对象 服务器接收到http协议的请求后,会根据报文创建HttpRequest对象,这个对象不需要我们创建,直接使用服务器构造好的对象就可以.视图的第一个参数必须是HttpR ...
- 63)对于STL基本概念东西 自己百度(没有整理)
基础知识 看 C++进阶课程讲义的那个word文档